





Des chercheurs en sécurité de Datadog affirment que le logiciel malveillant Vidar était présent dans 23 versions du référentiel npm depuis deux semaines et recommandent de prendre des précautions pour se protéger.
Des codes malveillants continuent d’être téléchargés dans des référentiels open source, ce qui rend difficile pour les développeurs responsables de faire confiance à leur contenu et pour les RSSI aux applications qui incluent du code open source. Dernier exemple en date : la découverte par des chercheurs en sécurité de Datadog le mois dernier dans le référentiel npm de 17 paquets (23 versions) contenant un malware pour les systèmes Windows qui s’exécute via un script de post-installation. Usant de typosquatting, les paquets associés se font passer pour ceux d’aide aux bots Telegram, de bibliothèques d’icônes ou de forks apparemment légitimes de projets préexistants tels que Cursor et React. Ces paquets offrent des fonctionnalités légitimes, mais leur objectif réel est d’exécuter l’infostealer Vidar sur le système de la victime. Datadog estime qu’il s’agit de la première divulgation publique du logiciel malveillant Vidar distribué via des paquets npm. Depuis, les deux comptes proposant ces paquets (aartje et saliii229911) ont été bannis. Mais, ils sont restés dans le registre pendant environ deux semaines, et les paquets malveillants ont été téléchargés au moins 2 240 fois. Les chercheurs pensent cependant que bon nombre de ces téléchargements ont probablement été effectués par des scrapers automatisés, certains ayant eu lieu après que les paquets ont été supprimés et remplacés par des paquets de sécurité vides.
Le typosquatting, c’est-à-dire la création de paquets dont les noms sont similaires à ceux de paquets officiels afin de tromper les développeurs qui recherchent une bibliothèque particulière, est l’une des tactiques préférées des acteurs malveillants qui tentent d’infecter la chaîne d’approvisionnement des logiciels open source. Par exemple, en 2018, un chercheur a découvert que des acteurs malveillants avaient créé de fausses bibliothèques dans le référentiel Python appelées « diango », « djago » et « dajngo » afin de tromper les développeurs qui recherchaient la célèbre bibliothèque Python « django ». Les RSSI doivent s’assurer que les employés sont au fait de ce problème de typosquatting et qu’ils savent ce qu’ils doivent rechercher. Les services IT doivent tenir un inventaire complet des composants utilisés par tous les logiciels approuvés, sur la base duquel des audits peuvent être effectués, afin de s’assurer que seuls les composants approuvés sont en place. Cet inventaire et cet audit doivent être effectués pour valider tout nouveau composant introduit.
Des conséquences fâcheuses
La compromission malveillante de composants open source peut entraîner toutes sortes de choses désagréables. Tout d’abord, les auteurs de la menace peuvent voler les identifiants des développeurs et insérer des portes dérobées dans leur code. Ensuite, le code malveillant contenu dans le composant téléchargé peut se propager dans le monde entier et atteindre les clients du développeur. La découverte de Datadog n’est qu’un exemple parmi d’autres de codes malveillants téléchargés sur npm, PyPI, GitHub et d’autres référentiels open source. La semaine dernière, Koi Security a signalé avoir trouvé 126 paquets malveillants dans npm, et en septembre, les chercheurs de Step Security ont signalé que des dizaines de bibliothèques npm avaient été remplacées par du code permettant de voler des identifiants. Le même mois, les chercheurs d’Aikido ont signalé que 18 paquets npm très populaires et téléchargés avaient été contaminés. « Je ne vois pas comment résoudre facilement ce problème sans une vue complète de la sécurité de tout nouveau code soumis, et ce n’est ni rapide, ni bon marché, ni facile », a commenté Roger Grimes, conseiller en sécurité informatique chez KnowBe4. « Mais c’est vraiment la seule solution si l’on veut un code open source fiable et sûr », a-t-il ajouté.
« Paradoxalement, l’une des principales raisons invoquées pour inciter à utiliser du code open source, c’est de dire qu’il est aisément vérifiable, de sorte que n’importe qui peut le consulter pour détecter et corriger les vulnérabilités », a-t-il souligné. « Sauf que, en réalité, presque personne ne vérifie la sécurité des dizaines de millions de lignes de code open source », a-t-il fait remarquer. « Des dizaines de projets open source ont tenté de mettre en place davantage de révisions de code par défaut, mais tous ont échoué », a-t-il rappelé. « L’une de mes citations préférées à ce sujet est la suivante : demander aux utilisateurs de réviser le code open source avant de l’utiliser revient à demander aux passagers d’un avion de descendre de l’appareil et de vérifier sa sécurité avant le décollage. Je ne sais pas qui est le premier à avoir dit cela, mais ça résume parfaitement les raisons pour lesquelles la révision volontaire du code open source ne fonctionne pas. »
Des actions correctives possibles
Les conseils ne manquent pas pour éviter aux développeurs et responsables IT et du SI pour éviter qu’ils ne soient victimes de paquets malveillants dans les référentiels open source. Une tactique consiste à inclure une nomenclature logicielle dans chaque application acquise par un service IT. Grâce à elle, les équipes DevOps/DevSecOps peuvent suivre les composants logiciels, identifier les vulnérabilités et garantir la conformité. Dans un avis intitulé « Defending Against Software Supply Chain Attacks » (Se défendre contre les attaques de la chaîne d’approvisionnement logicielle), et publié en 2021, l’Agence américaine de cybersécurité et de sécurité des infrastructures (Cybersecurity and Infrastructure Security Agency, CISA) et le National Institute for Standards and Technology (NIST) proposent plusieurs conseils pour créer des applications open source sécurisées. En premier lieu, elles suggèrent de créer un programme officiel de gestion des risques liés à la chaîne d’approvisionnement afin de garantir que ces risques soient pris en compte dans toute l’entreprise, y compris par les cadres et les responsables des opérations et du personnel occupant des fonctions de soutien, comme l’IT, les acquisitions, le service juridique, la gestion des risques et la sécurité.
Selon l’avis, il est possible de réduire sa surface d’attaque logicielle grâce à la gestion de la configuration, laquelle comprend :
– La mise en place d’un contrôle des modifications des configurations ;- Des analyses d’impact sur la sécurité ;- La mise en œuvre des directives fournies par les fabricants pour renforcer la sécurité des logiciels, des systèmes d’exploitation et des firmwares ;- La tenue d’un inventaire des composants du système d’information.
Par ailleurs, l’Open Source Web Application Security Project (OWASP) conseille aux développeurs qui utilisent npm :
– De toujours vérifier et effectuer les contrôles nécessaires sur les modules tiers qu’ils prévoient d’installer afin de confirmer leur état et leur crédibilité ;- De ne pas procéder immédiatement à la mise à niveau vers les nouvelles versions ; de laisser les nouvelles versions des paquets circuler pendant un certain temps avant de les essayer ;- Avant de procéder à la mise à niveau, de veiller à consulter les journaux des modifications et les notes de mise à jour de la version mise à niveau ;- De veiller à ajouter le suffixe ignore-scripts afin de désactiver l’exécution de tout script par des paquets tiers lors de l’installation de paquets ;- D’envisager l’ajout de ignore-scripts au fichier de projet .npmrc ou à la configuration globale npm.
Enfin, Andrew Krug, responsable de la sécurité chez Datadog, recommande encore :
– De donner aux développeurs la possibilité d’installer un scan des paquets en temps réel lors de l’installation ;- De se protéger contre le typosquatting et la confusion des dépendances en privilégiant l’utilisation de référentiels de paquets internes comme garde-fou pour les paquets approuvés ;- De maintenir des nomenclatures logicielles ;- De déployer l’analyse de la composition logicielle (Software Composition Analysis, SCA) à chaque phase du cycle de vie du développement logiciel. « Les outils SCA traditionnels n’analysent que périodiquement des instantanés de code », a fait remarquer M. Krug, « or, une détection efficace doit être complétée par une visibilité en temps réel sur les services déployés, y compris en production, afin de redéfinir les priorités et de se concentrer sur les problèmes exposés dans des environnements sensibles ».
Le fournisseur de solutions de sécurité F5 Networks a expliqué avoir été touché par une attaque informatique ayant probablement bénéficié d’un soutien de niveau étatique. Il exhorte les entreprises à installer ses derniers correctifs.
Les responsables de la sécurité informatique dont l’environnement comprend des équipements F5 Networks doivent immédiatement mettre à jour leurs systèmes et rester vigilants face à toute activité suspecte. Le fournisseur a en effet reconnu ce mercredi dans un document à la Securities and Exchange Commission (SEC) qu’un acteur malveillant non identifié avait volé une partie du code source de ses produits BIG-IP au début de l’année, ainsi que des informations sur des vulnérabilités non divulguées et des données de configuration de terminaux de « quelques clients ». En réponse à cette divulgation, l’Agence américaine de cybersécurité et de sécurité des infrastructures (Cybersecurity and Infrastructure Security Agency, CISA) a demandé la veille aux agences civiles fédérales d’évaluer si leurs terminaux BIG-IP étaient accessibles depuis l’Internet public et d’appliquer les mises à jour de F5. « Cet acteur malveillant représente une menace imminente pour les réseaux fédéraux utilisant des appareils et des logiciels F5 », indique l’avertissement de la CISA.
« L’exploitation réussie des produits F5 concernés pourrait permettre à un acteur malveillant d’accéder aux identifiants et aux clés d’API intégrées, de se déplacer latéralement au sein du réseau d’une organisation, d’exfiltrer des données et d’établir un accès persistant au système. Tout cela pourrait potentiellement conduire à une compromission totale des systèmes d’information ciblés. » F5 a publié des mises à jour correctrices pour BIG-IP, F5OS, BIG-IP Next pour Kubernetes, BIG-IQ et les clients APM. « Nous recommandons vivement de procéder à la mise à jour vers ces nouvelles versions dès que possible », a déclaré le fournisseur. Connu pour ses produits de sécurité et de livraison d’applications, notamment ses passerelles Web et ses solutions de gestion des contrôles d’accès, F5 a refusé une demande d’interview pour obtenir plus de détails et s’est contenté de renvoyer vers son communiqué.
Ce qui a été dérobé
Dans sa déclaration, F5 a indiqué que le pirate avait exfiltré des fichiers provenant de l’environnement de développement du produit BIG-IP et des plateformes de gestion des connaissances techniques. « Ces fichiers contenaient une partie de notre code source BIG-IP et des informations sur des failles non divulguées sur lesquelles nous travaillions dans BIG-IP. Nous n’avons connaissance d’aucune vulnérabilité critique ou à distance non divulguée, et nous ne sommes pas au courant d’une exploitation active de vulnérabilités F5 non divulguées. » Jusqu’à présent, selon la déclaration, rien n’indique que des données provenant des systèmes de gestion de la relation client, des systèmes financiers, des systèmes de gestion des cas d’assistance ou des systèmes iHealth de F5 aient été consultées ou exfiltrées. F5 ajoute que « certains des fichiers exfiltrés de notre plateforme de gestion des connaissances contenaient cependant des informations de configuration ou de mise en œuvre concernant un petit pourcentage de clients », et qu’il examine « actuellement ces fichiers et communiquera directement avec les clients concernés, le cas échéant. » Le fournisseur indique n’avoir à ce stade aucune preuve de modification de sa chaîne logistique logicielle, y compris son code source et ses pipelines de compilation et de publication. « Cette évaluation a été validée par des examens indépendants réalisés par les cabinets de recherche en cybersécurité NCC Group et IOActive. Il n’y a aucune preuve que l’auteur de la menace ait accédé ou modifié le code source Nginx ou l’environnement de développement du produit. Pour mémoire Nginx est un serveur web open source utilisé pour du reverse proxy, de l’équilibrage de charge et de la mise en cache. Pour l’heure il n’y a pas non plus de preuve que le pirate a accédé ou modifié ses systèmes Distributed Cloud Services ou Silverline indique encore le fournisseur.
F5 attribue cette attaque à un « acteur malveillant hautement sophistiqué agissant pour le compte d’un État ». Le fournisseur n’a pas précisé depuis combien de temps le pirate était actif dans son environnement. Quant à la raison pour laquelle cette attaque est révélée maintenant, la société a expliqué dans sa déclaration à la SEC que le 12 septembre, le ministère américain de la Justice (DoJ) avait estimé qu’un report de la divulgation publique était justifié. Les dispositifs réseau critiques tels que les pare-feu, les passerelles Web, les passerelles de messagerie électronique et autres dispositifs similaires sont depuis longtemps la cible des acteurs malveillants qui les utilisent comme points d’entrée dans les réseaux informatiques, comme l’illustrent la récente divulgation par SonicWall de la compromission des données de sa plateforme de sauvegarde cloud MySonicWall et l’avertissement lancé le mois dernier par la CISA selon lequel les acteurs malveillants ciblaient les dispositifs ASA (Adaptive Security Appliances) de Cisco Systems en exploitant des vulnérabilités zero-day.
Des mesures d’atténuation appliquées
Les responsables informatiques et de la sécurité doivent s’assurer que les serveurs, logiciels et clients F5 disposent des derniers correctifs. De plus, F5 a ajouté des contrôles de renforcement automatisés à l’outil F5 iHealth Diagnostics Tool et suggère également aux administrateurs de se référer à son guide de recherche des menaces pour renforcer la surveillance, ainsi qu’à ses guides des meilleures pratiques pour renforcer les systèmes F5. À la suite de cette attaque, F5 a déclaré avoir modifié ses identifiants et renforcé les contrôles d’accès sur l’ensemble de ses systèmes, déployé une automatisation améliorée de la gestion des stocks et des correctifs, ainsi que des outils supplémentaires pour mieux surveiller, détecter et répondre aux menaces. F5 a aussi procédé à des améliorations de son architecture de sécurité réseau et renforcé son environnement de développement de produits, notamment en renforçant les contrôles de sécurité et la surveillance de toutes les plateformes de développement logiciel. Par ailleurs, F5 fournira à tous ses clients pris en charge un abonnement gratuit au service de protection des terminaux Falcon EDR de CrowdStrike.
Un tremplin pour de futures attaques ?
« D’après les informations actuellement divulguées concernant l’ampleur de l’incident et les données volées, il n’y a aucune raison de paniquer », a voulu rassurer Ilia Kolochenko, CEO d’ImmuniWeb, dans un communiqué. « Cela dit, le code source volé peut grandement simplifier les recherches sur les vulnérabilités menées par les cybercriminels à l’origine de la violation et faciliter la détection des vulnérabilités zero day dans les produits F5 concernés, qui pourraient être exploitées dans le cadre d’attaques APT ultérieures. De même, le faible pourcentage de clients dont les informations techniques auraient été compromises devrait évaluer de toute urgence ses risques et continuer à travailler avec F5 pour mieux comprendre l’impact de l’incident. »
« Cette attaque nous rappelle une fois de plus que la surface d’attaque moderne s’étend profondément dans le cycle de vie du développement logiciel », a fait remarquer Will Baxter, RSSI terrain chez Team Cymru, dans un communiqué. « Les groupes malveillants qui ciblent les référentiels de code source et les environnements de développement recherchent des informations à long terme, afin de comprendre le fonctionnement interne des contrôles de sécurité », a-t-il expliqué. « La visibilité sur les connexions sortantes, l’infrastructure de commande et de contrôle des acteurs malveillants et les modèles inhabituels d’exfiltration de données est essentielle pour identifier rapidement cette activité. La combinaison des informations externes sur les menaces et de la télémétrie interne fournit aux défenseurs le contexte nécessaire pour détecter et contenir ces intrusions avancées. »
« Cette exploitation n’était pas opportuniste », a-t-il ajouté. « Les acteurs de la menace ont cherché à obtenir des informations sur le code et les vulnérabilités avant leur divulgation. Les groupes soutenus par des États considèrent de plus en plus les référentiels de code source et les systèmes d’ingénierie comme des cibles de renseignement stratégiques. La détection précoce dépend de la surveillance des connexions sortantes, du trafic de commande et de contrôle, et des flux de données inhabituels provenant des environnements de développement et de construction. La combinaison des renseignements sur les menaces externes avec la télémétrie interne donne aux défenseurs le contexte nécessaire pour identifier et contenir ces campagnes avant que le code volé ne soit transformé en zero-day. »
L’envergure de l’incident pas encore déterminé
« L’incident F5 est grave du fait de l’accès prolongé de l’attaquant aux systèmes », a pointé Johannes Ullrich, doyen de la recherche au SANS Institute. « Selon les déclarations de F5, la quantité de données clients divulguées semble très limitée », a-t-il noté. « Cependant, on ne sait pas encore où en est F5 dans sa réponse à l’incident, ni dans quelle mesure l’entreprise est certaine d’avoir correctement identifié l’impact de l’attaquant. La perte du code source et des informations sur les vulnérabilités non corrigées pourrait entraîner une augmentation des attaques contre les systèmes F5 dans un avenir proche. Il est important de suivre les conseils de F5 pour renforcer la sécurité et, par mesure de précaution, de vérifier et de modifier éventuellement ses identifiants. »
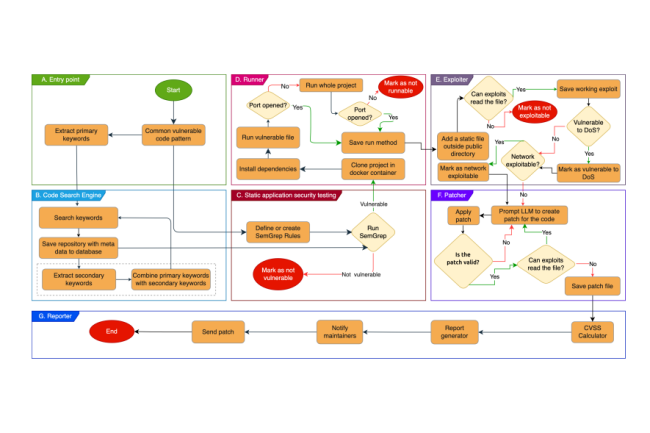
Même s’il n’est pas encore parfait, l’outil développé par des chercheurs universitaires peut trouver les vulnérabilités dans les grands référentiels comme GitHub et créer automatiquement un correctif. Un premier pas comprenant quelques limitations et le scepticisme des experts.
Souvent critiquée pour sa sécurité, l’IA peut aussi servir à renforcer la protection des applications. C’est le cas de l’outil mis au point par plusieurs chercheurs universitaires capable de détecter et de corriger du code vulnérable dans les référentiels de logiciel open source. Ainsi, il a recherché dans GitHub une vulnérabilité particulière de traversée de répertoire présente depuis 2010 dans les projets Node.js. Il a réussi à identifier 1756 projets vulnérables, dont certains sont qualifiés de « très influents ». et 63 d’entre eux ont été jusqu’à présent corrigés. La solution propose aux plateformes de genAI telles que ChatGPT de créer et de distribuer automatiquement des correctifs dans les référentiels de code, augmentant ainsi considérablement la sécurité des applications open source.
Mais la recherche, décrite dans un article récemment publié, met également en évidence une sérieuse limitation dans l’utilisation de l’IA, qui devra être corrigée pour rendre la solution efficace. En effet, si l’application automatisée de correctifs par un grand modèle de langage (LLM) améliore considérablement la mise à l’échelle, le correctif peut aussi introduire d’autres bogues. En particulier quand la vulnérabilité existe depuis longtemps, le LLM peut être contaminé et générer du code vulnérable. Les chercheurs pensent donc qu’il faudra éradiquer les modèles de code vulnérables populaires non seulement des projets open source et des ressources des développeurs, mais aussi des LLM, « une tâche qui peut s’avérer très difficile ».
Du mauvais code implanté depuis des années par les pirates
Cela fait des années que les acteurs de la menace introduisent des vulnérabilités dans les référentiels open source, dans l’espoir que, avant la découverte de ces bogues, ils puissent les exploiter pour infiltrer les entreprises qui adoptent des applications open source. Sauf que les développeurs copient et collent sans le savoir du code faillible provenant de plateformes de partage de code comme Stack Overflow, et ce code se retrouve ensuite dans les projets GitHub. Les chercheurs font remarquer que les attaquants n’ont besoin de connaître qu’un seul modèle de code vulnérable pour pouvoir attaquer avec succès de nombreux projets et leurs dépendances en aval. La solution créée par les chercheurs donne la possibilité de découvrir et d’éliminer à grande échelle les failles dans les logiciels open source, et non pas dans un seul projet à la fois comme c’est le cas actuellement.
Cependant, l’outil n’est pas capable de tout scanner et de tout corriger en un passage, car les développeurs créent souvent des référentiels sans contribuer aux projets d’origine. Par conséquent, pour qu’une vulnérabilité soit réellement effacée, tous les référentiels contenant un morceau de code vulnérable devraient être analysés et corrigés. De plus, le modèle de code vulnérable étudié dans le cadre de cette recherche utilise directement le nom du chemin dans l’URL, sans formatage particulier, ce qui facilite la découverte de la faille. C’est sur ce modèle que l’outil se concentre, et les autres emplacements du mauvais code ne sont pas détectés. Les chercheurs présenteront l’outil en août lors d’une conférence sur la sécurité au Vietnam. Ils prévoient de l’améliorer et d’étendre sa portée, notamment en intégrant d’autres modèles de codes vulnérables et en améliorant la génération de correctifs.
Scepticisme des experts
Cependant, Robert Beggs, directeur de la société canadienne de réponse aux incidents DigitalDefence, est sceptique quant à la valeur de l’outil dans son état actuel. « L’idée d’une solution automatisée pour rechercher et corriger les codes malveillants existe depuis un certain temps », souligne-t-il, et il reconnaît aux auteurs le mérite d’avoir tenté de résoudre un grand nombre des problèmes éventuels déjà soulevés. « Cependant, la recherche n’aborde toujours pas certaines questions : savoir par exemple qui est responsable si un correctif défectueux endommage un projet public, ou encore savoir si un gestionnaire de référentiel peut reconnaître qu’un outil d’IA essaye d’insérer une vulnérabilité potentielle dans une application », a-t-il ajouté,
On ne sait pas non plus dans quelle mesure, le cas échéant, l’outil effectuera des tests post-remédiation pour s’assurer que le correctif ne cause pas d’autres dommages. Le document indique qu’en fin de compte, la responsabilité du correctif incombe aux responsables du projet. La partie IA de l’outil crée un correctif, calcule un score CVSS et soumet un rapport aux responsables du projet. « Les chercheurs ont mis au point un excellent processus et je leur reconnais tout le mérite d’avoir développé un outil doté de nombreuses capacités. Cependant, en ce qui me concerne, je ne toucherais pas à cet outil parce qu’il traite de la modification du code source », a déclaré M. Beggs. Et il ajoute : « Je ne pense pas que l’intelligence artificielle ait atteint le niveau nécessaire pour lui permettre de gérer le code source d’un grand nombre d’applications. » Ce dernier admet cependant que les articles universitaires ne sont généralement qu’une première approche.
Les développeurs de logiciels libres, en partie à l’origine du problème
En cours de route, les chercheurs ont également découvert un fait troublant : les développeurs d’applications de logiciels open source ignorent parfois les avertissements sur le manque de fiabilité de certains extraits de code. Le code vulnérable que les chercheurs voulaient corriger dans le plus grand nombre possible de projets GitHub remonte à 2010 et se trouve dans GitHub Gist, un service de partage d’extraits de code. Le code crée un serveur de fichiers HTTP statique pour les applications web Node.js. « Malgré sa simplicité et sa popularité, de nombreux développeurs semblent ignorer que ce modèle de code est vulnérable à l’attaque par traversée de chemin », ont écrit les chercheurs. Même ceux qui ont reconnu le problème se sont heurtés au désaccord d’autres développeurs, qui ont à plusieurs reprises réfuté l’idée de la malignité du code. En 2012, un développeur a déclaré que le code était vulnérable. Deux ans plus tard, un autre développeur a soulevé la même préoccupation concernant la vulnérabilité, mais un autre a affirmé par la suite que le code était sûr, après l’avoir testé. L’affaire s’est répétée en 2018.
Les chercheurs rappellent que la même chose s’est produite en 2016 et dans une question à propos de Stack Overflow qui a totalisé plus de 88 000 vues, un développeur a mis en garde contre une possible vulnérabilité du code. Cependant, il n’a pas été en mesure de vérifier le problème, de sorte que le code a de nouveau été considéré comme sûr. Les chercheurs pensent que le malentendu sur la gravité de la vulnérabilité est dû au fait que, lorsque les développeurs testent le code, ils utilisent généralement un navigateur web ou la commande curl de Linux qui masqueraient tous deux le problème. « Les attaquants ne sont pas obligés d’utiliser des clients standard », ont déclaré les chercheurs. Plus inquiétant, ils ajoutent : « nous avons également trouvé plusieurs cours de Node.js qui utilisaient cet extrait de code vulnérable à des fins d’enseignement ».
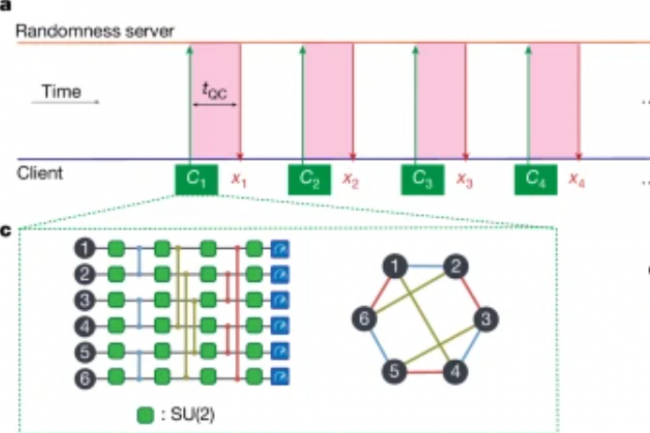
Des chercheurs affirment que leur protocole donne une capacité de créer des nombres réellement aléatoires sur un ordinateur quantique actuel servant à des applications sécurisées pour des domaines variés allant de la finance à la cybersécurité.
Si la recherche dans l’informatique quantique se focalise sur la création d’un qbit logique et la réduction des taux d’erreur, les universitaires travaillent également sur les usages. Et en particulier sur la génération de nombres aléatoires, un procédé essentiel pour le chiffrement des données. Des chercheurs viennent d’indiquer avoir trouvé un protocole dans ce domaine et ainsi sécuriser différentes applications allant de la finance à la cybersécurité. Néanmoins, une analyste du secteur se montre prudente. « Les conclusions de l’équipe de JPMorgan sont intéressantes, mais ne seront pas applicables à court terme pour la plupart des responsables de la sécurité, à moins qu’ils ne soient responsables d’environnements hautement sécurisés », a déclaré Sandy Carielli, analyste principale chez Forrester Research. « La génération de nombres aléatoires quantiques existe depuis un certain temps et des RSSI peuvent déjà utiliser des produits dans ce domaine », a-t-elle rappelé, ajoutant que « une telle certification pourrait être un atout supplémentaire pour les environnements très réglementés. »
Pour protéger les solutions actuelles et en créer de nouvelles à l’aide d’ordinateurs quantiques, il faudra des applications capables de générer des nombres aléatoires imprévisibles pour les clés de chiffrement et impossibles à déchiffrer par les machines quantiques. « La génération de nombres aléatoires est à la base d’un chiffrement efficace, car elle est nécessaire pour créer des clés de manière optimale », a expliqué Mme Carielli. « Si un déficit du caractère aléatoire réduit le nombre de clés potentielles d’un facteur significatif, un attaquant peut utiliser la force brute ou deviner une clé », a-t-elle ajouté. « Au fil des ans, des problèmes liés à une mauvaise génération de nombres aléatoires ont entravé la mise en œuvre de la cryptographie. Il existe également de nombreuses méthodes de génération de nombres aléatoires réputées. L’utilisation d’un ordinateur quantique pour la génération de nombres aléatoires est certainement une option, mais elle pose aussi des questions de coût ou d’évolutivité. »
La création de nombres véritablement aléatoires possible
Selon les auteurs de l’article publié dans Nature, les recherches montrent que les ordinateurs quantiques peuvent résoudre des problèmes mieux que les techniques informatiques classiques, mais que les besoins en ressources des algorithmes quantiques connus pour ces problèmes les placent loin de la portée des machines quantiques actuelles ou à venir à court terme. Cependant, les chercheurs de JPMorganChase, Quantinuum, Argonne National Laboratory, Oak Ridge National Laboratory et de l’université du Texas à Austin, affirment que leur solution montre que les ordinateurs quantiques actuels et de court terme, basés sur des portes quantiques peuvent effectuer au moins une tâche utile sur le plan pratique : créer des nombres véritablement aléatoires. L’équipe y est parvenue en élaborant un protocole qui a fonctionné sur Internet avec un ordinateur quantique à ions piégés de 56 qubits de l’entreprise américaine Quantinuum. Selon un communiqué de JPMorganChase, les chercheurs ont tiré parti d’une tâche conçue à l’origine pour démontrer l’avantage quantique, connue sous le nom de random circuit sampling (RCS), pour exécuter un protocole d’expansion de caractère aléatoire certifié, qui produit plus d’aléatoire qu’il n’en prend en entrée. Selon eux, cette tâche est irréalisable par l’informatique classique.
Dans un billet de blog, JPMorganChase explique que le type du caractère aléatoire idéal présenterait les trois caractéristiques suivantes :
1. Provenir d’une source fiable et vérifiable2. Être assorti de garanties mathématiques rigoureuses3. Ne pas avoir été manipulé par un adversaire malveillant
C’est ce qu’on appelle un caractère aléatoire certifié ou certified randomness. Et, selon l’article, « il s’avère qu’un tel protocole est impossible à réaliser à l’aide d’ordinateurs conventionnels, mais qu’il peut l’être à l’aide d’un ordinateur quantique. » Ce procédé comprend deux étapes. Tout d’abord, il génère des circuits aléatoires de défi (les programmes quantiques sont appelés circuits) et les envoie à l’ordinateur quantique distant non fiable, qui doit alors renvoyer les nombres « aléatoires » obtenus. Cette méthodologie a également été testée par rapport aux meilleures techniques actuellement connues pour simuler des circuits aléatoires sur les supercalculateurs conventionnels les plus puissants du monde. Alors que le temps d’exécution quantique par défi était d’environ deux secondes, l’équipe a estimé que les circuits de défi ne pouvaient être simulés de manière classique qu’en 100 secondes environ.
Ensuite, pour vérifier que de véritables nombres aléatoires avaient été générés, le caractère aléatoire des résultats a été certifié mathématiquement à l’aide de superordinateurs classiques du département américain de l’énergie. « Lorsque j’ai proposé pour la première fois mon protocole de hasard certifié en 2018, je n’avais aucune idée du temps qu’il faudrait attendre pour en voir une démonstration expérimentale », a reconnu dans un communiqué Scott Aaronson, titulaire de la Schlumberger Centennial Chair of Computer Science et directeur du Quantum Information Center à l’Université du Texas à Austin. « Je suis ravi que JPMorganChase et Quantinuum se soient appuyés sur le protocole original et l’aient réalisé. C’est un premier pas vers l’utilisation d’ordinateurs quantiques pour générer des bits aléatoires certifiés pour des applications cryptographiques réelles », s’est-il félicité.
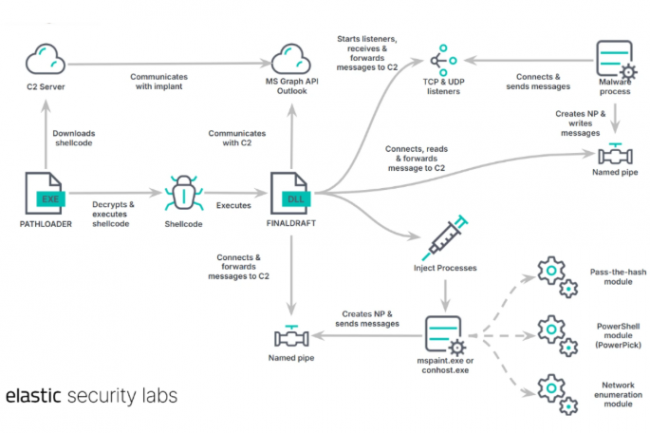
Des chercheurs d’Elastic Security ont identifié une attaque commençant par le vol d’identifiants et se poursuivant par une utilisation compromettante d’Outlook et de l’API graphique de Microsoft pour voler discrètement des données.
Les chercheurs d’Elastic Security mettent en garde les RSSI contre une famille de logiciels malveillants voleurs de données. Le nouveau vecteur d’attaque utilise Microsoft Outlook comme canal de communication en abusant de l’API Graph, et inclut un moyen de contourner les mots de passe hachés. Selon les chercheurs à l’origine de sa découverte, cette méthode a été créée par un groupe anonyme ciblant le ministère des Affaires étrangères d’un pays d’Amérique du Sud, mais est aussi liée à des compromissions observées dans une université d’Asie du Sud-Est et dans les télécommunications de cette région. La campagne se caractérise par un « ensemble d’intrusions novatrices, bien conçues et très performantes », indiquent-ils dans un rapport. La campagne contre le pays sud-américain a peut-être commencé en novembre 2024. C’est à ce moment-là qu’Elastic Security a détecté un groupe restreint d’alertes comportementales au sein du ministère des Affaires étrangères du pays. La manière dont le système informatique a été initialement compromis n’est pas claire, mais le gang a utilisé des tactiques de survie une fois à l’intérieur du système. Ils ont notamment utilisé l’application de gestion des certificats certutil de Windows pour télécharger des fichiers. Le rapport indique que l’espionnage semble être le motif de l’intrusion et qu’il existe des versions Windows et Linux du logiciel malveillant. Par chance, le gang « a commis des erreurs dans la gestion de sa campagne et ses tactiques d’évasion sont incohérentes », note le rapport.
Néanmoins, les RSSI devraient être attentifs aux signes d’attaques utilisant les techniques de ce groupe, car leurs cibles pourraient se répandre et leurs techniques pourraient gagner en sophistication. Un indice signalé aux RSSI par les chercheurs serait immédiatement détectable : après la compromission initiale, le gang a utilisé le plugin Remote shell de Windows Remote Management (WinrsHost.exe), un processus côté client utilisé par Windows Remote Management, pour télécharger des fichiers. Ces fichiers comprennent un exécutable, des fichiers rar, des fichiers ini et des fichiers log. L’exécutable est une version renommée d’un débogueur signé par Windows, CDB.exe.
Des informations d’identification réseau valides aux mains des pirates
Comme l’indique le rapport, l’utilisation abusive de ce binaire a permis aux attaquants d’exécuter un shellcode malveillant livré dans un fichier config.ini sous l’apparence de binaires de confiance. L’utilisation du plugin shell de Windows Remote Management (WRM) « indique que les attaquants possédaient déjà des informations d’identification réseau valides et qu’ils les utilisaient pour un mouvement latéral à partir d’un hôte précédemment compromis dans l’environnement ». Il ajoute que « la manière dont ces informations d’identification ont été obtenues est inconnue ». Johannes Ullrich, doyen de la recherche à l’Institut SANS fait remarquer qu’il « est toujours délicat d’empêcher les mouvements latéraux si un attaquant a obtenu des informations d’identification valides », ajoutant « qu’ils pourraient provenir d’autres brèches (credential stuffing) ou simplement d’enregistreurs de frappe ou de voleurs d’informations qu’ils ont pu déployer au cours de phases antérieures de l’attaque et qui ne sont pas couvertes par le rapport. »
Outre un chargeur et une porte dérobée, les principaux composants du logiciel malveillant utilisé par l’attaquant sont les suivants :
– Pathloader : ce fichier exécutable Windows léger télécharge et exécute un shellcode chiffré hébergé sur un serveur distant. Il utilise des techniques pour éviter une exécution immédiate dans la sandbox de l’entreprise cible. Pour bloquer l’analyse statique, il effectue un hachage de l’API et un chiffrement de la chaîne ;
– FinalDraft : ce logiciel malveillant 64 bits écrit en C++ se concentre sur l’exfiltration de données et d’exécution de code arbitraire dans un espace d’adresse séparé d’un processus (process injection). Il comprend plusieurs modules qui peuvent être injectés par le logiciel malveillant ; leurs résultats sont transmis à un serveur de commande et de contrôle (C2).
Entre autres choses, il recueille initialement des informations sur les serveurs ou les PC compromis, notamment le nom de l’ordinateur, le nom d’utilisateur du compte, les adresses IP internes et externes, ainsi que des détails sur les processus en cours d’exécution. FinalDraft comprend également une boîte à outils « pass-the-hash » similaire à Mimikatz pour traiter les hachages NTLM (New Technology LAN Manager) volés.
Des attaques personnalisées plus efficaces
Pour communiquer, le malware passe, entre autres choses, par le service de messagerie Outlook, qui utilise l’API Microsoft Graph. Cette API permet aux développeurs d’accéder aux ressources hébergées sur les services cloud de Microsoft, y compris Microsoft 365. Bien qu’un jeton de connexion soit nécessaire pour cette API, le logiciel malveillant FinalDraft a la capacité de capturer un jeton de l’API Graph. Selon un rapport de Symantec publié l’année dernière, un nombre croissant d’acteurs de la menace abusent de l’API Graph pour dissimuler des communications. De plus, FinalDraft peut, entre autres, installer un listener TCP après avoir ajouté une règle au pare-feu Windows. Cette règle est supprimée lorsque le serveur s’éteint. Il peut également supprimer des fichiers et empêcher les services IT de les récupérer en écrasant les données par des zéros avant de les supprimer. « C’est un excellent exemple d’utilisation de la technique « living-off-the-land » (LOLBins) à son plein potentiel », a commenté M. Ullrich. « Cela indique que l’adversaire a pris le temps de personnaliser son attaque afin d’atteindre le plus efficacement possible sa cible. Il est vraiment difficile de se défendre contre une attaque de ce type. L’aspect « avancé » de l’APT (Advanced Persistent Threat) est souvent plus visible dans cette préparation que dans les outils utilisés et l’exécution de l’attaque.
À la fin de son rapport, Elastic Security énumère plusieurs règles Yara qu’il a créées et publiées sur GitHub pour mieux se défendre contre le malware. Ces règles permettent de détecter PathLoader et FinalDraft sous Windows, et cette règle détecte FinalDraft sous Linux.
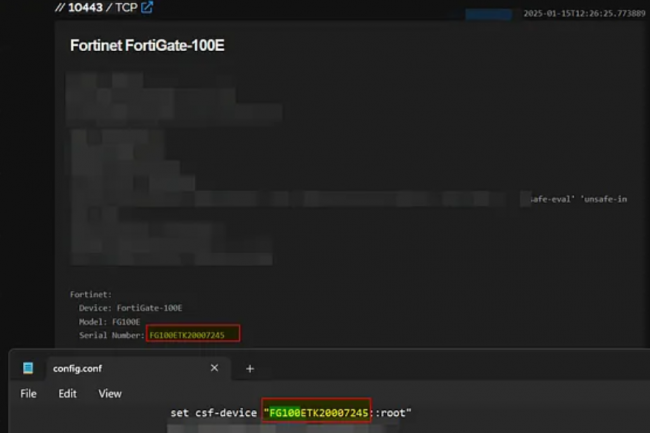
A peine sortis d’une zero-day, les administrateurs de pare-feux FortiGate de Fortinet doivent examiner minutieusement leurs systèmes pour éviter tout risque de compromission suite à la diffusion de données de configuration et d’informations d’identification VPN volées il y a deux ans.
Coup de chaud pour les administrateurs réseau qui utilisent le pare-feu FortiGate de Fortinet dans leur environnement informatique. Après une faille zero-day exploitée dans les firewalls de ce fournisseur, le chercheur en cybersécurité Florian Roth a lancé une autre alerte. Cet avertissement fait suite à l’analyse qu’il a faite des données de configuration de matériels FortiGate volés, publiées au début du mois par un acteur malveillant appelé Belsen Group. Ces données, censées contenir les paramètres de configuration de 15 000 pare-feux, seraient d’une grande valeur pour les pirates. « Si la sécurité est importante pour vous, vous devez évaluer la compromission des terminaux et autres systèmes de votre réseau touchés […] les correctifs ne suffisent pas. » Le chercheur les exhorte aussi à traiter cette affaire comme un incident de sécurité.
A l’origine de cette découverte, Kevin Beaumont, également chercheur en sécurité, qui a trouvé après examen des données publiées par ce cybergang. Elles contenaient des adresses IP, des mots de passe en clair et certaines adresses électroniques d’utilisateurs ou de leurs entreprises. À la vue de ces informations, certains se demandent aussi pourquoi les administrateurs ont autorisé le stockage de mots de passe en clair dans un fichier de configuration. M. Roth a regroupé les adresses électroniques par domaine de premier niveau afin d’aider les RSSI et les équipes de sécurité à déterminer si leur entreprise était concernée. Cependant, il a averti que certains des domaines pouvaient être ceux de services de messagerie gratuits ou de fournisseurs de services travaillant pour les victimes réelles.
Des mesures à prendre pour éviter l’exploit
Pour sa part, après la publication, la semaine dernière, des données dérobées par Belsen Group, Fortinet s’est voulu rassurant, déclarant que les informations exposées avaient été capturées à partir d’une vulnérabilité de 2022 et agrégées pour ressembler à une nouvelle divulgation. « Notre analyse des appareils en question montre que la majorité d’entre eux ont depuis longtemps été mis à niveau vers des versions plus récentes », a affirmé l’entreprise. La liste ne comprend aucune configuration pour FortiOS 7.6 ou 7.4 (les versions les plus récentes du système d’exploitation de Fortinet), « ni aucune configuration récente pour 7.2 et 7.0 ». « Si votre entreprise a toujours respecté les meilleures pratiques de routine en actualisant régulièrement les informations d’identification de sécurité et a pris les mesures recommandées au cours des années précédentes, il y a très peu de risque que la configuration actuelle de l’entreprise ou des informations d’identification aient été divulguées par l’acteur de la menace », a précisé Fortinet.
« Nous continuons à recommander vivement aux entreprises de prendre les mesures recommandées, si elles ne l’ont pas déjà fait, pour améliorer leur posture de sécurité. Nous pouvons également confirmer que les équipements achetés depuis décembre 2022 ou qui n’ont exécuté que FortiOS 7.2.2 ou une version plus récente ne sont pas concernés par les informations divulguées par cet acteur de la menace. » Cependant, le fournisseur ajoute que si une entreprise « utilisait une version impactée (7.0.6 et inférieure ou 7.2.1 et inférieure) avant novembre 2022 et qu’elle n’a pas encore pris les mesures recommandées dans l’avis [d’octobre 2022] », elle doit revoir les actions recommandées pour améliorer sa posture de sécurité. Les chercheurs de Censys pensent qu’un peu plus de 5 000 des 15 000 dispositifs FortiGate compromis exposent encore leurs interfaces de connexion Web. « Même si vous avez appliqué un correctif en 2022, vous pouvez toujours avoir été exploité, car les configurations ont été vidées il y a des années et viennent seulement d’être publiées », a encore écrit M. Beaumont. « Il est préférable de savoir à quel moment ce correctif a été appliqué. Disposer de la configuration complète d’un appareil, y compris de toutes les règles de pare-feu, cela représente beaucoup d’informations… »
Une faille toujours dangereuse
Alors que les données ont apparemment été collectées il y a un peu plus de deux ans, on ne sait pas pourquoi elles sont diffusées maintenant. Dans un article publié la semaine dernière et analysant les données, les chercheurs de Censys font remarquer que Belsen Group est un acteur récent de la menace et qu’il a peut-être récemment acheté ou rassemblé les données mises en vente par le(s) pirate(s) initial(aux). Censys estime également que, même si des mesures ont été prises par les administrateurs de FortiGate il y a deux ans, après la découverte de la vulnérabilité, « celle-ci est toujours pertinente et pourrait causer des dommages ». Souvent, les règles de configuration des pare-feux ne sont pas modifiées, à moins qu’un incident de sécurité spécifique oblige à une mise à jour. « Il peut aussi arriver que certains de ces firewalls aient changé de propriétaire dans l’intervalle, mais ces cas sont également rares. »