





Une étude de Cisco Talos montre que l’activité de la franchise de ransomware BlackByte a été plus intense qu’estimée. Le groupe de cybercriminels a modifié et fait évoluer ses tactiques et ses outils au fil du temps.
Il ne faut pas se fier aux sites de revendications des groupes de ransomware pour établir un baromètre de leurs activités. Des chercheurs de Talos, division cybersécurité de Cisco, ont trouvé que le nombre de victimes répertoriées par BlackByte sur son site ne représente que 20 à 30% des compromissions du groupe de ransomware. De plus, les attaques récemment analysées montrent des changements de tactiques et un autre variant de son chiffreur de fichiers.
Un pic d’activité passé sous le radar
Dans son rapport, les experts de Talos spécialisés en réponse à incident et threat intelligence ont « remarqué des similitudes étroites entre les indicateurs de compromission (IOC) découverts au cours de l’enquête et d’autres événements signalés dans la télémétrie globale de Talos ». Ils ajoutent qu’ « un examen plus approfondi de ces similitudes a permis de mieux comprendre la stratégie actuelle de BlackByte et a révélé que le groupe a été beaucoup plus actif qu’il n’y paraît au vu du nombre de victimes publié sur son site de fuites de données. »
La raison pour laquelle le cybergang ne publie pas toutes les compromissions réussies sur son site n’est pas claire. Il se peut que ce soit pour éviter d’attirer trop d’attention ou que certaines victimes acceptent de payer avant qu’il ne soit nécessaire de les répertorier. Il est également possible que toutes les attaques de BlackByte n’aboutissent pas à une exfiltration de données. Les chercheurs donnent un exemple où l’outil d’exfiltration des données nommé ExByte a été déployé mais sans confirmer avec certitude que des données ont été dérobées.
Une émanation de Conti
BlackByte est un groupe de ransomware-as-a-service (RaaS) apparu pour la première fois fin 2021 et qui est soupçonnée d’être une ramification de Conti, gang de premier plan qui s’est dissous en mai 2022 après avoir attiré trop d’attention et commis une série d’erreurs opérationnelles. Après l’invasion de l’Ukraine par la Russie en février 2022, de nombreux groupes de cybercriminels se sont déclarés neutres d’autant plus que beaucoup d’entre eux étaient à la fois en Russie et en Ukraine.
Mais Conti s’est publiquement rangé du côté de la Russie et a menacé de cibler les infrastructures critiques occidentales en représailles, ce qui a probablement incité certains de ses affiliés à prendre leurs distances par rapport au groupe. Après la fin de Conti, plusieurs franchises sont apparues. BlackByte, Black Basta et KaraKurt se sont rapidement distingués comme trois nouveaux groupes ayant adopté un code, des outils et des tactiques très similaires à ceux précédemment associés à Conti
Des outils et des attaques affinés
Si BlackByte a conservé les mêmes tactiques, techniques et procédures (TTP) depuis sa création, les attaques les plus récentes en ont révélé d’autres. Par exemple, le groupe est connu pour avoir déployé un chiffreur de ransomware de type ver qui se propage de lui-même et qui est personnalisé pour chaque victime à l’aide d’identifiants SMB et NTLM codés en dur et volés à l’intérieur du réseau ciblé. Bien que ce procédé serve toujours, le chiffreur de fichiers a été remanié au fil du temps dans plusieurs langages de programmation : Go, .NET et enfin C++. La dernière variante observée par Cisco Talos ajoute l’extension « blackbytent_h » aux fichiers chiffrés.
Le groupe était également connu pour déployer plusieurs pilotes officiels mais vulnérables sur des systèmes compromis afin de les utiliser pour l’escalade des privilèges et d’autres tâches. Pour cette technique, connue sous le nom de BYOVD (bring your own vulnerable driver), BlackByte était connu pour utiliser trois pilotes spécifiques : RtCore64.sys, utilisé à l’origine par l’utilitaire d’overclocking MSI Afterburner ; DBUtil_2_3.sys, issu de l’utilitaire de mise à jour du firmware Dell Client ; et gdrv.sys, un driver du logiciel Gigabyte Tools pour les cartes mères du fournisseur. Lors d’attaques récentes, le gang a ajouté un quatrième pilote appelé zamguard64.sys, qui fait partie de l’application Zemana Anti-Malware (ZAM). Il présente une vulnérabilité qui peut être utilisée pour mettre fin à d’autres processus et pour désactiver les produits EDR sur les ordinateurs des victimes. La franchise s’intéresse par ailleurs aux environnements virtuels avec l’exploitation de la vulnérabilité CVE-2024-37085 de contournement de l’authentification dans VMware ESXi quelques jours après sa divulgation publique. La faille permet aux membres d’un groupe Active Directory appelé « ESX Admins » de contrôler les machines virtuelles sur les hôtes ESXi.
Des mesures d’atténuations recommandées
Cisco Talos recommande aux entreprises de mettre en œuvre les MFA pour toutes les connexions à distance et dans le cloud et d’auditer leurs configurations VPN. Les sociétés devraient également mettre en place des alertes pour les changements dans les groupes privilégiés d’Active Directory et limiter ou désactiver l’utilisation de NTLM à l’intérieur de leurs réseaux. Un protocole d’authentification que Microsoft a abandonné au profit de Kerberos. SMBv1, un autre protocole ancien, devrait également être désactivé et les versions plus récentes de SMB devraient être signées et cryptées. Tous les comptes fournisseurs et les fonctions d’accès à distance qui ne sont pas utilisés devraient également être désactivés et des détections de politiques Windows Defender et d’objets de stratégie de groupe non autorisés devraient être déployées sur les systèmes.

Les déploiements du framework d’intelligence artificielle Ray ne sont pas censés se connecter à Internet. Si les développeurs le font quand même, ils rendent alors leurs serveurs vulnérables.
Des chercheurs avertissent que des milliers de serveurs ont été compromis au cours des sept derniers mois en raison de l’absence d’authentification par défaut dans un framework de calcul open source appelé Ray. Il est utilisé pour distribuer des workload de machine learning et d’IA. Problème, les développeurs du framework conteste le fait que ce manque d’authentification soit une faille. “Des milliers d’entreprises et de serveurs exploitant une infrastructure d’IA sont exposés à une attaque via une vulnérabilité critique qui fait l’objet d’un litige et n’a donc pas de correctif”, ont déclaré les experts de la société Oligo, spécialisée dans la sécurité des applications, dans un rapport publié cette semaine. “Cette faille accorde aux attaquants de prendre le contrôle de la puissance de calcul des entreprises et de faire fuiter des données sensibles.”
Jusqu’à présent, Oligo a identifié des serveurs compromis dans de nombreux secteurs d’activité, notamment l’éducation, les crypto-monnaies, la biopharmacie et l’analyse vidéo. Ces serveurs Ray avaient l’historique des commandes activé, ce qui signifie que les pirates pouvaient facilement découvrir des secrets sensibles utilisés dans les commandes précédentes. Ray est souvent utilisé pour exécuter des charges de travail qui servent à former, déployer et affiner des modèles d’IA. Par ailleurs, certains des travaux comprennent des scripts Python et des commandes bash qui peuvent contenir des informations d’identification nécessaires à l’intégration avec des services tiers. “Un environnement ML-OPS se compose de nombreux services qui communiquent entre eux, à l’intérieur d’un même cluster et entre les clusters”, expliquent les chercheurs. “Lorsqu’il est utilisé pour la formation ou au fine tuning, il a généralement accès à des ensembles de données et à des modèles, sur disque ou dans un stockage distant, tel qu’un bucket S3. Souvent, ces jeux de données constituent la propriété intellectuelle unique et privée qui différencie une entreprise de ses concurrents.” ajoutent-ils.
Une fonctionnalité prévue ayant des implications en matière de sécurité
L’année dernière, des chercheurs en sécurité de Bishop Fox ont découvert et signalé cinq vulnérabilités dans le cadre Ray. Anyscale, la société qui maintient le logiciel, a décidé de corriger quatre d’entre elles (CVE-2023-6019, CVE-2023-6020, CVE-2023-6021 et CVE-2023-48023) dans la version 2.8.1, mais a affirmé que la cinquième, assignée CVE-2023-48022, n’en n’était pas vraiment une et qu’elle n’avait donc pas été corrigée. En effet, la CVE-2023-48022 est directement causée par le fait que le tableau de bord Ray et l’API client n’implémentent pas de contrôles d’authentification. Ainsi, tout attaquant qui peut atteindre l’API client peut soumettre de nouveaux travaux, supprimer ceux existants, récupérer des informations sensibles et, essentiellement, exécuter des commandes à distance.
“En raison de la nature de Ray en tant qu’environnement d’exécution distribué, la frontière de sécurité de Ray se trouve à l’extérieur du cluster Ray”, a déclaré Anyscale dans son avis. “C’est pourquoi nous insistons sur le fait que vous devez empêcher l’accès à votre cluster Ray à partir de machines non fiables (par exemple via l’Internet public). C’est la raison pour laquelle la cinquième CVE (le manque d’authentification intégré dans Ray) n’a pas été abordée et qu’il ne s’agit pas, à notre avis, d’une vulnérabilité, ni même d’un bogue”. La documentation de Ray indique clairement que “Ray s’attend à fonctionner dans un environnement réseau sûr et à agir sur un code fiable” et qu’il est de la responsabilité des développeurs et des fournisseurs de plateformes de garantir ces conditions pour un fonctionnement sûr. Cependant, comme nous l’avons vu avec d’autres technologies dans le passé qui manquaient d’authentification par défaut, les utilisateurs ne suivent pas toujours les meilleures pratiques et les déploiements non sécurisés feront leur chemin sur Internet tôt ou tard. Anyscale en est conscient et va travailler sur l’ajout d’un mécanisme d’authentification dans les versions futures.
Des configurations non sécurisées par défaut
D’ici là, cependant, de nombreuses entreprises continueront probablement à exposer involontairement ces serveurs sur Internet car, selon Oligo, de nombreux guides de déploiement et référentiels pour Ray, y compris certains des guides officiels, sont fournis avec des configurations de déploiement non sécurisées.
“Les experts en IA ne sont PAS des experts en sécurité, ce qui les rend potentiellement dangereusement inconscients des risques très réels posés par les frameworks d’IA”, ont déclaré les chercheurs. “Sans autorisation pour l’API Jobs de Ray, l’API peut être exposée à des attaques RCE si les meilleures pratiques ne sont pas respectées.

Depuis un an, l’outil de gestion de cluster de containers fait face à de sérieuses failles. Après celle relative aux fichiers de configuration YAML accordant des privilèges systèmes sur les hôtes Windows l’été dernier, une autre en injection de commandes via les volumes locaux de Kubernetes a été mise à jour par le même chercheur en sécurité d’Akamai.
Kubernetes est un environnement IT comme les autres et est donc soumis à de nombreuses failles. Depuis un an, l’orchestrateur de cluster de containers en a connu deux particulièrement graves. Tout d’abord l’été dernier dans les fichiers configuration YAML des clusters Kubernetes accordant des privilèges systèmes sur les hôtes Windows. Et puis plus récemment en novembre une autre méritant une attention particulière, cette fois relative à de l’injection de commandes via des volumes locaux de l’orchestrateur de containers.
Découverte et partagée ce 13 mars par le chercheur en sécurité d’Akamai Tomer Peled, celle-ci a été répertoriée en tant que CVE-2023-5528 et corrigée dans les versions 1.28.4, 1.27.8, 1.26.11 et 1.25.16 de Kubernetes publiées en novembre 2023. La faille est similaire à la précédente CVE-2023-3676 mais au lieu de cibler la fonction de volume subPath, elle provient de la fonction de volumes locaux. Ceux-ci sont un type de volumes pris en charge dans l’orchestrateur grâce auxquels les utilisateurs montent des partitions de disque à l’intérieur d’un pod. Ils se différencient des volumes hostPath leur donnant la possibilité de monter des répertoires spécifiques. Un administrateur de clusters peut provisionner l’espace de stockage à l’avance en créant un persistentVolume, puis les utilisateurs peuvent utiliser YAML lors de la configuration d’un pod pour faire un persistentVolumeClaim afin de réclamer une partie de cet espace de stockage.
Une faille corrigée, une mise à jour à effectuer
Problème : lors de l’analyse de ces demandes à partir d’un fichier YAML, le service kubelet s’appuyait sur une fonction qui utilisait exec.command pour exécuter une commande sur le système afin de créer un lien symbolique entre le volume et l’emplacement à l’intérieur du pod. Le terminal de ligne de commande Windows accepte la concaténation de commandes – l’exécution de plusieurs commandes sur une seule ligne – en plaçant les caractères && entre les commandes.
Tomer Peled – encore lui – a découvert qu’un attaquant pouvait placer des commandes dans la définition Path du persistentVolumeClaim dans YAML et les entourer avec les caractères && avant que celles-ci soient potentiellement exécutées sur le système hôte lorsque la réclamation est traitée par le service kubelet qui s’exécute avec les privilèges SYSTEM. L’équipe Kubernetes a corrigé la vulnérabilité d’injection de commande en remplaçant l’appel cmd effectué par le service kubelet par une fonction dans GO appelée “os.Symlink()” qui effectuera la même opération de création de liens symboliques mais d’une manière sûre. Si ce n’était pas encore le cas, il convient bien entendu d’appliquer d’installer les dernières versions disponibles pour éviter tout souci lié à cette dangereuse CVE.

Plusieurs vulnérabilités ont été identifiées dans le runtime de container runc exposant Docker mais aussi d’autres systèmes d’exécution de conteneurs. Principal risque : la couche d’isolation entre le conteneur et le système d’exploitation hôte peut être rompue.
Des chercheurs en sécurité ont découvert quatre vulnérabilités dans des composants de Docker qui pourraient permettre à des attaquants d’accéder à des systèmes d’exploitation hôtes à partir de conteneurs. L’une de ces vulnérabilités se trouve dans runc, un outil de ligne de commande permettant de créer et d’exécuter des conteneurs sous Linux, qui est à la base de plusieurs moteurs de conteneurs, et pas seulement de Docker. Ce n’est pas la première fois que ce runtime de container est touché par des failles de sécurité. Les vulnérabilités ont été découvertes par Rory McNamara, un chercheur de la société de sécurité informatique Snyk, qui les a collectivement baptisées « Leaky Vessels », car elles permettent de rompre la couche d’isolation critique entre les conteneurs et le système d’exploitation hôte. « Ces évasions de conteneurs pourraient permettre à un attaquant d’obtenir un accès non autorisé au système d’exploitation hôte sous-jacent à partir du conteneur et potentiellement permettre l’accès à des données sensibles (identifiants, informations sur les clients, etc.), et lancer d’autres attaques, en particulier lorsque l’accès obtenu comprend des privilèges de super-utilisateur », a déclaré Snyk dans un billet de blog.
De multiples voies d’attaque à partir de runc
Runc peut être considéré comme la tuyauterie qui relie la plupart des moteurs de gestion de conteneurs tels que Docker, containerd, Podman et CRI-O aux fonctionnalités de sandboxing du noyau Linux : groupes de contrôle, espaces de noms, seccomp, apparmor, etc. Il prend en charge plusieurs commandes pour démarrer, arrêter, suspendre, mettre en pause et répertorier les conteneurs, ainsi que pour exécuter des processus à l’intérieur des conteneurs. La faille dans runc découverte par Rory McNamara, répertoriée sous le nom de CVE-2024-21626, provient d’un descripteur de fichier divulgué par inadvertance en interne au sein de runc, y compris un handle vers le groupe /sys/fs/c de l’hôte. Ceci peut être exploité de plusieurs façons : une repérée par McNamara et trois autres trouvées par les mainteneurs de runc. « Si le conteneur a été configuré pour que process.cwd soit défini sur /proc/self/fd/7/ (le fd réel peut changer en fonction de l’ordre d’ouverture des fichiers dans runc), le processus pid1 résultant aura un répertoire de travail dans l’espace de noms de montage de l’hôte et le processus engendré pourra donc accéder à l’ensemble du système de fichiers de l’hôte », avertissent les responsables de runc dans une note d’information. « Cela ne constitue pas en soi un exploit contre runc. Cependant, une image malveillante pourrait faire de n’importe quel chemin non-/ d’apparence inoffensive un lien symbolique vers /proc/self/fd/7/ et ainsi tromper un utilisateur en lui faisant démarrer un conteneur dont le binaire a accès au système de fichiers de l’hôte ». Cet exploit cible la commande runc run, qui est utilisée pour créer et démarrer un conteneur à partir d’une image. De nombreux conteneurs sont démarrés à partir d’images téléchargées à partir de dépôts publics tels que Docker Hub et des images malveillantes ont été téléchargées dans le registre au fil du temps.
Une autre variante de l’attaque concerne runc exec utilisé pour démarrer un processus à l’intérieur d’un conteneur existant. Pour ce faire, l’attaquant doit savoir qu’un processus administratif appelle runc exec avec l’argument -cwd et un chemin spécifique, puis remplacer ce chemin par un lien symbolique vers le descripteur de fichier /proc/self/fd/7. Une troisième attaque consiste à utiliser la technique runc run ou runc exec pour écraser les binaires du système d’exploitation hôte, tels que /bin/bash – l’interpréteur de commandes de Linux. Ces deux variantes sont connues sous le nom d’attaques 3a et 3b. « Alors que l’attaque 3a est la plus grave du point de vue de CVSS, les attaques 2 et 3b sont sans doute plus dangereuses en pratique car elles permettent une évasion depuis l’intérieur d’un conteneur plutôt que d’exiger qu’un utilisateur exécute une image malveillante », ont prévenu les responsables de runc. Cependant, cela dépend du contexte. Par exemple, dans les systèmes d’exécution de niveau supérieur comme Docker ou Kubernetes, toute personne ayant les droits de démarrer une image de conteneur peut exécuter l’exploit à distance. L’attaque peut également être lancée en utilisant la fonction ONBUILD dans les fichiers Docker. Bien que runc soit probablement le runtime de conteneur le plus populaire et le plus utilisé en raison de son association avec Docker, ce n’est pas le seul disponible. Les responsables de runc préviennent que d’autres runtimes sont potentiellement vulnérables à des attaques similaires ou ne disposent pas d’une protection suffisante contre celles-ci.
Comment atténuer la vulnérabilité runc de Docker
En plus du trou de sécurité runc, corrigé dans la dernière version 1.1.12, Rory McNamara a également trouvé des vulnérabilités d’échappement de conteneur dans d’autres composants Docker tels que BuildKit (CVE-2024-23652 et CVE-2024-23653) et une condition de course de cache (CVE-2024-23651).
« Recherchez les annonces du fournisseur de vos systèmes de déploiement et d’orchestration de conteneurs concernant les mises à jour pour résoudre le problème ou les déclarations dans les cas où ils ne sont pas affectés », ont déclaré les chercheurs de Snyk. « Cela signifie probablement que vous devez mettre à jour vos Docker Daemon et vos déploiements Kubernetes, ainsi que tous les outils de construction de conteneurs que vous utilisez dans les pipelines CI/CD, sur les serveurs de construction et sur les postes de travail de vos développeurs ». Snyk a également développé deux outils open source qui permettent aux utilisateurs de surveiller leurs conteneurs pour détecter les signes de tentatives d’exploitation. L’un est un scanner d’exécution qui utilise des crochets eBPF pour surveiller les invocations suspectes de commandes de construction et d’exécution de conteneurs qui correspondent aux modèles de cet exploit, et l’autre est un scanner statique pour les fichiers et les images Docker.
Plusieurs vulnérabilités ont été identifiées dans le runtime de container runc exposant Docker mais aussi d’autres systèmes d’exécution de conteneurs. Principal risque : la couche d’isolation entre le conteneur et le système d’exploitation hôte peut être rompue.
Des chercheurs en sécurité ont découvert quatre vulnérabilités dans des composants de Docker qui pourraient permettre à des attaquants d’accéder à des systèmes d’exploitation hôtes à partir de conteneurs. L’une de ces vulnérabilités se trouve dans runc, un outil de ligne de commande permettant de créer et d’exécuter des conteneurs sous Linux, qui est à la base de plusieurs moteurs de conteneurs, et pas seulement de Docker. Ce n’est pas la première fois que ce runtime de container est touché par des failles de sécurité. Les vulnérabilités ont été découvertes par Rory McNamara, un chercheur de la société de sécurité informatique Snyk, qui les a collectivement baptisées « Leaky Vessels », car elles permettent de rompre la couche d’isolation critique entre les conteneurs et le système d’exploitation hôte. « Ces évasions de conteneurs pourraient permettre à un attaquant d’obtenir un accès non autorisé au système d’exploitation hôte sous-jacent à partir du conteneur et potentiellement permettre l’accès à des données sensibles (identifiants, informations sur les clients, etc.), et lancer d’autres attaques, en particulier lorsque l’accès obtenu comprend des privilèges de super-utilisateur », a déclaré Snyk dans un billet de blog.
De multiples voies d’attaque à partir de runc
Runc peut être considéré comme la tuyauterie qui relie la plupart des moteurs de gestion de conteneurs tels que Docker, containerd, Podman et CRI-O aux fonctionnalités de sandboxing du noyau Linux : groupes de contrôle, espaces de noms, seccomp, apparmor, etc. Il prend en charge plusieurs commandes pour démarrer, arrêter, suspendre, mettre en pause et répertorier les conteneurs, ainsi que pour exécuter des processus à l’intérieur des conteneurs. La faille dans runc découverte par Rory McNamara, répertoriée sous le nom de CVE-2024-21626, provient d’un descripteur de fichier divulgué par inadvertance en interne au sein de runc, y compris un handle vers le groupe /sys/fs/c de l’hôte. Ceci peut être exploité de plusieurs façons : une repérée par McNamara et trois autres trouvées par les mainteneurs de runc. « Si le conteneur a été configuré pour que process.cwd soit défini sur /proc/self/fd/7/ (le fd réel peut changer en fonction de l’ordre d’ouverture des fichiers dans runc), le processus pid1 résultant aura un répertoire de travail dans l’espace de noms de montage de l’hôte et le processus engendré pourra donc accéder à l’ensemble du système de fichiers de l’hôte », avertissent les responsables de runc dans une note d’information. « Cela ne constitue pas en soi un exploit contre runc. Cependant, une image malveillante pourrait faire de n’importe quel chemin non-/ d’apparence inoffensive un lien symbolique vers /proc/self/fd/7/ et ainsi tromper un utilisateur en lui faisant démarrer un conteneur dont le binaire a accès au système de fichiers de l’hôte ». Cet exploit cible la commande runc run, qui est utilisée pour créer et démarrer un conteneur à partir d’une image. De nombreux conteneurs sont démarrés à partir d’images téléchargées à partir de dépôts publics tels que Docker Hub et des images malveillantes ont été téléchargées dans le registre au fil du temps.
Une autre variante de l’attaque concerne runc exec utilisé pour démarrer un processus à l’intérieur d’un conteneur existant. Pour ce faire, l’attaquant doit savoir qu’un processus administratif appelle runc exec avec l’argument -cwd et un chemin spécifique, puis remplacer ce chemin par un lien symbolique vers le descripteur de fichier /proc/self/fd/7. Une troisième attaque consiste à utiliser la technique runc run ou runc exec pour écraser les binaires du système d’exploitation hôte, tels que /bin/bash – l’interpréteur de commandes de Linux. Ces deux variantes sont connues sous le nom d’attaques 3a et 3b. « Alors que l’attaque 3a est la plus grave du point de vue de CVSS, les attaques 2 et 3b sont sans doute plus dangereuses en pratique car elles permettent une évasion depuis l’intérieur d’un conteneur plutôt que d’exiger qu’un utilisateur exécute une image malveillante », ont prévenu les responsables de runc. Cependant, cela dépend du contexte. Par exemple, dans les systèmes d’exécution de niveau supérieur comme Docker ou Kubernetes, toute personne ayant les droits de démarrer une image de conteneur peut exécuter l’exploit à distance. L’attaque peut également être lancée en utilisant la fonction ONBUILD dans les fichiers Docker. Bien que runc soit probablement le runtime de conteneur le plus populaire et le plus utilisé en raison de son association avec Docker, ce n’est pas le seul disponible. Les responsables de runc préviennent que d’autres runtimes sont potentiellement vulnérables à des attaques similaires ou ne disposent pas d’une protection suffisante contre celles-ci.
Comment atténuer la vulnérabilité runc de Docker
En plus du trou de sécurité runc, corrigé dans la dernière version 1.1.12, Rory McNamara a également trouvé des vulnérabilités d’échappement de conteneur dans d’autres composants Docker tels que BuildKit (CVE-2024-23652 et CVE-2024-23653) et une condition de course de cache (CVE-2024-23651).
« Recherchez les annonces du fournisseur de vos systèmes de déploiement et d’orchestration de conteneurs concernant les mises à jour pour résoudre le problème ou les déclarations dans les cas où ils ne sont pas affectés », ont déclaré les chercheurs de Snyk. « Cela signifie probablement que vous devez mettre à jour vos Docker Daemon et vos déploiements Kubernetes, ainsi que tous les outils de construction de conteneurs que vous utilisez dans les pipelines CI/CD, sur les serveurs de construction et sur les postes de travail de vos développeurs ». Snyk a également développé deux outils open source qui permettent aux utilisateurs de surveiller leurs conteneurs pour détecter les signes de tentatives d’exploitation. L’un est un scanner d’exécution qui utilise des crochets eBPF pour surveiller les invocations suspectes de commandes de construction et d’exécution de conteneurs qui correspondent aux modèles de cet exploit, et l’autre est un scanner statique pour les fichiers et les images Docker.
Un PoC d’exploit dévoilé par des chercheurs en sécurité montre qu’il est possible de télécharger des versions malveillantes de PyTorch sur GitHub en exploitant des erreurs de configuration dans son service Actions.
L’union fait la force. Un duo de chercheurs en sécurité a réussi à infiltrer l’infrastructure de développement de PyTorch en utilisant des techniques qui exploitent des configurations non sécurisées dans les flux de travail GitHub Actions. Leur attaque a été divulguée dans le cadre d’une démarche de hacking éthique au développeur principal de PyTorch, Meta AI, mais d’autres sociétés de développement de logiciels utilisant GitHub Actions ont probablement fait les mêmes erreurs, s’exposant potentiellement à des attaques sur leur cycle de développement logiciel. « Notre méthode d’exploitation a permis de télécharger des versions malveillantes de PyTorch sur GitHub, de télécharger des versions sur AWS, d’ajouter potentiellement du code à la branche principale du dépôt, de créer des portes dérobées dans les dépendances de PyTorch – la liste est longue », a déclaré le chercheur en sécurité John Stawinski dans un article détaillé sur l’attaque publié sur son blog personnel. « En bref, c’était mauvais. Très mauvais ».
John Stawinski a conçu l’attaque avec son collègue Adnan Khan. Tous deux travaillent comme ingénieurs en sécurité pour la société de cybersécurité Praetorian et, l’été dernier, ils ont commencé à étudier et à développer une classe d’exploits inédite pour les plateformes d’intégration et de livraison continues (CI/CD). L’une de leurs premières cibles a été GitHub Actions, un service CI/CD pour automatiser la conception et le test du code logiciel en définissant des workflows s’exécutant automatiquement à l’intérieur de conteneurs sur l’infrastructure GitHub ou sur celle de l’utilisateur. Adnan Khan a initialement trouvé une vulnérabilité critique qui aurait pu conduire à l’empoisonnement des images officielles des runners du service Actions. Les « runners » sont les machines virtuelles qui exécutent les actions de construction définies dans les flux de travail de GitHub Actions. Après avoir signalé cette faille à la filiale de Microsoft et reçu une prime de 20 000 $, Adnan Khan s’est rendu compte que le problème principal qu’il avait découvert était systémique et que des milliers d’autres dépôts étaient probablement concernés.
L’exécution risquée d’actions GitHub auto-hébergées
Depuis, Adnan Khan et John Stawinski ont trouvé des vulnérabilités dans les référentiels logiciels et l’infrastructure de développement de grandes entreprises et de projets logiciels et ont récolté des centaines de milliers de dollars de récompenses dans le cadre de programmes de bug bounty. Parmi leurs « victimes » figurent Microsoft Deepspeed, une application Cloudflare, la bibliothèque d’apprentissage automatique TensorFlow, les portefeuilles de crypto-monnaie et les nœuds de plusieurs blockchains, ainsi que PyTorch, l’un des frameworks d’apprentissage automatique open source les plus utilisés. Il a été développé à l’origine par Meta AI, une filiale de Meta (anciennement Facebook), mais son développement est désormais régi par la Fondation PyTorch, une société indépendante agissant sous l’égide de la Fondation Linux. « Nous avons commencé par découvrir toutes les nuances de l’exploitation d’Actions, en exécutant des outils, des tactiques et des procédures (TTP) qui n’avaient jamais été vus auparavant dans la nature », a expliqué John Stawinski dans un billet de blog au début du mois. « Au fur et à mesure que nos recherches avançaient, nous avons fait évoluer nos TTP pour attaquer plusieurs plateformes CI/CD, notamment GitHub Actions, Buildkite, Jenkins et CircleCI ».
GitHub propose différents types de « runners » préconfigurés (Windows, Linux et macOS) s’exécutant directement sur l’infrastructure de GitHub et utilisés pour tester et créer des applications pour ces systèmes d’exploitation. Cependant, les utilisateurs ont également la possibilité de déployer l’agent de conception Actions sur leurs propres infrastructures et de le lier à leur entreprise et à leurs dépôts GitHub. Ces solutions sont connues sous le nom de runners auto-hébergés et apportent plusieurs avantages tels que l’exécution de différentes versions de systèmes d’exploitation et de combinaisons de matériel, ainsi que des outils logiciels supplémentaires que les runners hébergés de GitHub ne fournissent pas. Compte tenu de cette flexibilité, il n’est pas surprenant que de nombreux projets et sociétés choisissent de déployer des runners auto-hébergés. C’était également le cas pour PyTorch, qui utilise largement les agents de construction hébergés par GitHub et les agents de construction auto-hébergés. Le groupe possède plus de 70 fichiers de workloads différents dans ses référentiels et en exécute généralement plus de 10 par heure.
Des paramètres Github par défaut qui n’aident pas
Les flux d’actions sont définis dans des fichiers .yml qui contiennent des instructions en syntaxe YAML sur les commandes à exécuter et sur les exécutants. Ces workflows sont déclenchés automatiquement sur différents événements – par exemple, pull_request (PR) – lorsque quelqu’un propose une modification de code pour une branche du référentiel. C’est utile parce que le flux de travail se déclenche et peut exécuter par exemple une série de tests sur le code avant même qu’un réviseur humain ne l’examine et ne décide de le fusionner. « Le fait que certains paramètres par défaut de GitHub ne soient pas très sûrs ne facilite pas les choses », indique John Stawinski. « Par défaut, lorsqu’un runner auto-hébergé est attaché à un dépôt, tous les workflows de ce dépôt peuvent utiliser ce runner. Ce paramètre s’applique également aux flux de travail issus des requêtes pull pour un fork. Rappelez-vous que n’importe qui peut soumettre une demande de fork pull requests à un dépôt GitHub public. Oui, même vous. Le résultat de ces paramètres est que, par défaut, n’importe quel contributeur du dépôt peut exécuter du code sur le runner auto-hébergé en soumettant un PR malveillant ».
Une demande de fork signifie que quelqu’un a créé une copie personnelle de ce dépôt, a travaillé dessus, et essaie maintenant de fusionner les changements. Il s’agit d’une pratique courante, car les contributeurs travaillent souvent sur leurs propres forks avant de soumettre les modifications au dépôt principal pour approbation. Du point de vue de GitHub, un contributeur est toute personne dont les demandes d’extraction ont été fusionnées dans la branche et le paramètre par défaut pour l’exécution du flux de travail est d’exécuter automatiquement les demandes d’extraction du fork des anciens contributeurs. Cela signifie que si quelqu’un a déjà eu un fork pull requests fusionné, les workflows s’exécuteront automatiquement pour tous les prochains. Ce paramètre peut être modifié pour exiger l’approbation avant d’exécuter les workflows sur tous ses PR que le propriétaire soit un ancien contributeur ou non.
Utiliser le gestionnaire d’actions GitHub comme un cheval de Troie
« En consultant l’historique des demandes d’extraction, nous avons trouvé plusieurs PR de contributeurs précédents qui ont déclenché des flux de travail pull_request sans nécessiter d’approbation », d’après les chercheurs. « Cela indique que le référentiel n’exigeait pas l’approbation du workload pour les PR du fork des contributeurs précédents. Bingo ». Ainsi, un attaquant devrait d’abord devenir un contributeur en soumettant un fork PR légitime qui est fusionné, puis il pourrait abuser de son nouveau privilège pour en créer un fork et écrire un fichier de workload malveillant à l’intérieur, puis faire une demande de pull. Ainsi, ce flux corrompu serait automatiquement exécuté sur le Github Actions auto-hébergé de l’entreprise. Cela peut sembler compliqué mais en définitif ce n’est pas le cas. Il n’est en effet pas nécessaire d’ajouter de nouvelles fonctionnalités à un projet pour devenir contributeur, les chercheurs ayant obtenu ce statut pour PyTorch en trouvant une coquille dans un fichier de documentation et en faisant un PR pour la corriger. Une fois leur correction grammaticale mineure acceptée, ils ont alors eu la possibilité d’exécuter des flux de travail malveillants.
Un autre comportement par défaut des runners Actions auto-hébergés est qu’ils ne sont pas éphémères, pas réinitialisés et pas non plus effacés une fois qu’un workload est achevé. « Cela signifie que le workload malveillant peut démarrer un processus en arrière-plan qui continuera à s’exécuter après la fin du travail, et que les modifications apportées aux fichiers (tels que les programmes sur le chemin, etc.) persisteront au-delà du flux de travail actuel », ont déclaré les chercheurs. « Cela signifie également que les workloads futurs s’exécuteront sur ce même runner ». Il s’agit donc d’une bonne cible pour déployer un cheval de Troie qui se connecte aux attaquants et recueille toutes les informations sensibles exposées par les futures exécutions du flux de travail. Mais qu’utiliser comme trojan qui ne serait pas détecté par les produits antivirus ou dont les communications ne seraient pas bloquées ? L’agent runner Actions lui-même, ou plutôt une autre instance de cet agent non liée à une entreprise utilisant PyTorch mais une instance GitHub contrôlée par les attaquants. « Notre technique Runner on Runner (RoR) utilise les mêmes serveurs pour C2 que le runner existant, et le seul binaire que nous laissons tomber est le binaire officiel de l’agent d’exécution GitHub qui est déjà en cours d’exécution sur le système. Au-revoir les protections EDR et pare-feu », a déclaré John Stawinski.
Le Graal de l’extraction de jetons d’accès sensibles
Jusqu’à cette étape, les attaquants ont réussi à faire tourner un programme trojan très furtif dans une machine qui fait partie de l’infrastructure de développement de l’organisation et qui est utilisée pour exécuter des tâches sensibles dans le cadre de son pipeline CI/CD. L’étape suivante est la post-exploitation : il s’agit d’essayer d’exfiltrer des données sensibles et de les faire pivoter vers d’autres parties de l’infrastructure. Les flux de travail comprennent souvent des jetons d’accès à GitHub lui-même ou à d’autres services tiers. Ceux-ci sont nécessaires pour que les tâches définies dans le workload s’exécutent correctement. Par exemple, l’agent de construction a besoin de privilèges de lecture pour vérifier d’abord le référentiel et peut également avoir besoin d’un accès en écriture pour publier le binaire résultant en tant que nouvelle version ou pour modifier les versions existantes. Ces jetons sont stockés sur le système de fichiers du runner à différents endroits comme le fichier de configuration .git ou dans des variables d’environnement et peuvent évidemment être lus par le « trojan » furtif qui s’exécute avec les privilèges root. Certains, comme GITHUB_TOKEN, sont éphémères et ne sont valables que pendant l’exécution du flux de travail, mais les chercheurs ont trouvé des moyens de prolonger leur durée de vie. Même s’ils n’avaient pas trouvé ces méthodes, de nouveaux workloads avec des tokens nouvellement générés peuvent être exécutés en permanence sur un dépôt très actif comme PyTorch, leur potentiel en réserve est donc conséquent.
« Le dépôt PyTorch utilisait des secrets GitHub pour permettre aux runners d’accéder à des systèmes sensibles pendant le processus de publication automatisé », a déclaré John Stawinski. « Le référentiel utilisait de nombreux secrets, notamment plusieurs jeux de clés AWS et des jetons d’accès personnels GitHub (PAT) ». Les PAT disposent souvent de nombreux privilèges et constituent une cible attrayante pour les attaquants, mais dans ce cas, ils ont été utilisés dans le cadre de workloads ne s’exécutant pas sur le runner auto-hébergé compromis. Cependant, les chercheurs ont trouvé des moyens d’utiliser les jetons GitHub éphémères qu’ils ont pu collecter pour placer du code malveillant dans des flux de travail s’exécutant sur d’autres runners et contenaient ces PAT. « Il s’avère que vous ne pouvez pas utiliser un GITHUB_TOKEN pour modifier les fichiers de flux de travail », selon John Stawinski. « Cependant, nous avons découvert plusieurs solutions de contournement exotiques pour ajouter du code malveillant à un flux de travail en utilisant un GITHUB_TOKEN. Dans ce scénario, weekly.yml faisait appel à un autre workload utilisant un script en dehors du répertoire .github/workflows. Nous pouvons ajouter notre code à ce script dans notre branche. Ensuite, nous pourrions déclencher ce flux de travail sur notre branche, ce qui exécuterait notre code malveillant. Si cela vous semble déroutant, ne vous inquiétez pas, c’est également le cas pour la plupart des programmes de récompense des bugs ».
En d’autres termes, même si un attaquant ne peut pas modifier un workflow directement, il peut être en mesure de modifier un script externe appelé par ce flux de travail afin d’obtenir de cette façon son code malveillant. Les dépôts et les flux de travail CI/CD peuvent devenir assez complexes avec de nombreuses interdépendances, de sorte que de tels petits oublis ne sont pas rares. Même sans les PAT, le seul GITHUB_TOKEN doté de privilèges en écriture aurait été suffisant pour empoisonner les versions de PyTorch sur GitHub, et les clés AWS extraites séparément auraient pu être utilisées pour ouvrir une porte dérobée sur les versions de PyTorch hébergées sur le compte AWS de l’entreprise. « Il y avait d’autres ensembles de clés AWS, des PAT GitHub et diverses informations d’identification que nous aurions pu voler, mais nous pensions que nous avions une démonstration claire de l’impact à ce stade », ont fait savoir les chercheurs. « Compte tenu de la nature critique de la vulnérabilité, nous voulions soumettre le rapport dès que possible avant que l’un des 3 500 contributeurs de PyTorch ne décide de conclure un accord avec un acteur malveillant étranger ».
Des actions pour atténuer les risques liés aux flux de travail CI/CD
Les éditeurs de logiciels peuvent tirer de nombreux enseignements de cette attaque : des risques associés à l’exécution de runners d’actions GitHub auto-hébergés dans des configurations par défaut aux workflows exécutant des scripts en dehors de leur répertoire. Ou encore ceux liés aux jetons d’accès à privilèges et aux applications légitimes transformées en chevaux de Troie comme d’autres chercheurs l’ont aussi trouvé avec l’agent AWS System Manager et la solution SSO et de gestion des terminaux de Google pour Windows. « La sécurisation et la protection des runners relèvent de la responsabilité des utilisateurs finaux, et non de GitHub. C’est pourquoi GitHub recommande de ne pas utiliser de runners auto-hébergés sur des dépôts publics », a indiqué John Stawinski. « Apparemment, tout le monde n’écoute pas GitHub, y compris GitHub ».
Cependant, si les runners auto-hébergés sont nécessaires, les sociétés devraient au moins envisager de changer le paramètre par défaut de « require approval for first-time contributors » en « require approval for all outside collaborators ». C’est également une bonne idée de rendre les runners auto-hébergés éphémères et d’exécuter les workflows à partir des fork PR uniquement sur les runners hébergés sur GitHub. Ce n’est pas la première fois que l’utilisation non sécurisée des fonctionnalités de GitHub Actions génère des risques pour la sécurité de la chaîne d’approvisionnement des logiciels. D’autres services et plateformes CI/CD ont également présenté leurs propres vulnérabilités et des configurations par défaut non sécurisées. « Les problèmes liés à ces voies d’attaque ne sont pas propres à PyTorch », ont expliqué les chercheurs. « Ils ne sont pas non plus propres aux dépôts ML ou même à GitHub. Nous avons démontré à plusieurs reprises les faiblesses de la chaîne d’approvisionnement en exploitant les vulnérabilités de CI/CD dans les organisations technologiques les plus avancées du monde sur plusieurs plateformes CI/CD, et celles-ci ne représentent qu’un petit sous-ensemble de la plus grande surface d’attaque ».
Des attaques sophistiquées utilisent des techniques et des outils furtifs et évasifs contre des serveurs GitLab les rendant vulnérables à de l’exécution de code à distance. Avec, à la clé pour les pirates, du cryptominage et de la monétisation de bande passante via un logiciel proxy.
Des chercheurs de Sysdig mettent en garde contre une campagne d’attaque en cours contre des serveurs GitLab vulnérables entraînant le déploiement de logiciels malveillants de cryptojacking et de proxyjacking. Les attaques utilisent des logiciels malveillants multi-plateformes, des rootkits de noyau et de multiples couches d’obfuscation et tentent d’échapper à la détection en abusant de services légitimes. « Cette opération était beaucoup plus sophistiquée que la plupart des attaques observées par le Sysdig TRT », ont déclaré les chercheurs de la société de sécurité Sysdig dans un dernier rapport. « De nombreux attaquants ne se soucient pas du tout de la furtivité, mais cet attaquant a apporté un soin particulier à l’élaboration de son opération. Les techniques et outils furtifs et évasifs utilisés dans cette opération rendent la défense et la détection plus difficiles ».
Les attaquants à l’origine de la campagne d’attaques, que Sysdig a baptisée LABRAT, recherchent des serveurs GitLab vulnérables à un problème de sécurité critique connu, répertorié en tant que CVE-2021-22205. Cette faille provient d’une mauvaise validation des fichiers images lorsque GitLab les traite avec ExifTool et peut entraîner l’exécution de code à distance. Elle a été corrigée en avril 2021 dans les versions 13.8.8, 13.9.6 et 13.10.3, mais les exploits pour cette faille sont toujours activement utilisés dans les attaques, ce qui signifie que les pirates trouvent suffisamment de serveurs non corrigés pour justifier leur utilisation.
Le service TryCloudflare dans la boite à outils des pirates
Une fois qu’ils ont obtenu l’exécution du code à distance, les attaquants exécutent une commande curl pour télécharger et exécuter un script malveillant pour un serveur de commande et de contrôle (C2) avec un nom d’hôte trycloudflare.com. TryCloudflare est un service gratuit fourni par Cloudflare pour donner la capacité aux utilisateurs d’évaluer les différentes fonctionnalités de la plateforme. Les attaquants sont connus pour en abuser pour obfusquer l’emplacement réel de leur serveur C2, puisque le CDN de Cloudflare agit comme un proxy entre les deux. Une fois exécuté sur un système, le script vérifie si le processus watchdog est en cours d’exécution et tente de le tuer, supprime les fichiers des infections précédentes, désactive les mesures de défense de Tencent Cloud et d’Alibaba, télécharge d’autres binaires malveillants, met en place de nouveaux services système, modifie les tâches cron pour obtenir la persistance, collecte les clés SSH stockées localement qui sont ensuite utilisées pour effectuer un mouvement latéral vers d’autres systèmes.
Pour obfusquer leur communication avec les serveurs C2, les attaquants ont déployé le tunnel CloudFlare, une puissante solution de tunnelisation du trafic qui permet aux utilisateurs d’exposer des services locaux via le réseau sécurisé de Cloudflare sans modifier les paramètres du pare-feu ni procéder à une redirection de port. Des chercheurs de GuidePoint Security ont récemment signalé une augmentation du nombre d’attaques utilisant le tunnel CloudFlare et TryCloudflare. Dans certaines de ces attaques, les LABRAT ont hébergé leurs binaires malveillants sur un serveur GitLab privé qui est en ligne depuis septembre 2022 mais qui a été continuellement mis à jour. On ne sait pas à ce stade si les attaquants sont propriétaires de ce serveur ou s’il s’agit d’un serveur compromis utilisé à mauvais escient pour héberger leurs fichiers.
Un ensemble d’outils avancés utilisés
Dans les différentes attaques LABRAT qu’ils ont étudiées, les chercheurs de Sysdig ont constaté que l’acteur malveillant à l’origine de cette campagne utilisait de nombreux outils prêts à l’emploi. L’un d’entre eux est open source, Global Socket (GSocket), pour que deux systèmes situés dans des réseaux privés différents communiquent l’un avec l’autre sans qu’il ne soit nécessaire d’activer le suivi de port. Cela est possible grâce à un réseau de serveurs proxy qui utilisent le chiffrement et peuvent également acheminer le trafic via Tor, ce qui rend très difficile la découverte de l’autre machine. Dans ce cas, GSocket a été utilisé comme une porte dérobée pour que les attaquants accèdent à distance au système et envoient des commandes. Pour obtenir la persistance et déployer GSocket en tant que service qui s’active au redémarrage du système, les attaquants ont essayé d’exploiter la vulnérabilité d’élévation de privilèges PwnKit (CVE-2021-4034) sur les systèmes Linux.
Les chercheurs ont également trouvé des preuves que les attaquants impliqués dans la campagne LABRAT ont utilisé un rootkit open source appelé hiding-cryptominers-linux-rootkit conçu pour cacher les fichiers et les processus ainsi que leur utilisation de l’unité centrale et destiné à masquer les activités de cryptomining. En effet, LABRAT est en fin de compte une attaque à but lucratif et l’un des moyens utilisés par les attaquants pour monétiser les serveurs piratés a consisté à déployer une variante personnalisée du programme de minage de crypto-monnaie open source XMRig. Ce programme a été déployé par un loader écrit dans le langage de programmation Go, qui s’est assuré que le programme de minage de crypto-monnaies était déployé en tant que service se faisant passer pour le service légitime sshd (démon SSH).
Monétiser l’attaque via IPRoyal
Une deuxième méthode pour gagner de l’argent a consisté à déployer un outil associé au service IPRoyal pour que les utilisateurs partagent leur bande passante avec d’autres, moyennant paiement, en déployant un logiciel proxy sur leurs machines. Cette méthode d’exploitation de systèmes compromis est de plus en plus courante et a été baptisée proxyjacking. Les chercheurs ont également trouvé des fichiers associés à un autre service de proxy appelé ProxyLite. L’outil fourni par ce service est écrit en .NET Core, ce qui le rend multi-plateformes, et il utilise des techniques d’obfuscation avancées qui semblent être conçues pour rendre la détection et l’analyse plus difficiles.
« Le cryptomining et le proxyjacking ne devraient jamais être considérés comme des logiciels malveillants nuisibles et être éliminés nécessitant de reconstruire le système sans avoir mené une enquête approfondie », ont averti les chercheurs de Sysdig. « Comme nous l’avons vu dans cette opération, les logiciels malveillants ont la capacité de se propager automatiquement à d’autres systèmes à l’aide de clés SSH. Nous avons également constaté par le passé, avec SCARLETEEL, que les attaquants installent des cryptomineurs, mais volent également la propriété intellectuelle s’ils en ont l’occasion ». Le rapport de Sysdig contient divers indicateurs de compromission associés à cette campagne en cours, tels que les noms et les hachages de fichiers, les URL malveillants et les adresses IP qui peuvent être utilisés pour construire des détections.
Une dernière campagne de phishing via Microsoft 365 cible les dirigeants d’entreprise et utilise EvilProxy pour déjouer l’authentification multifactorielle.
Une campagne de phishing sur Microsoft 365 a ciblé plus de 100 entreprises depuis le mois de mars et a réussi à compromettre des comptes appartenant à des cadres supérieurs. Les attaquants ont utilisé EvilProxy, une boîte à outils de phishing qui utilise des tactiques de proxy inverse pour contourner l’authentification multifactorielle (MFA). « Contrairement à ce que l’on pourrait penser, il y a eu une augmentation des prises de contrôle de comptes parmi les locataires qui disposent d’une protection MFA », ont déclaré les chercheurs de la société de sécurité Proofpoint dans un billet de blog. « D’après nos données, au moins 35 % de tous les utilisateurs compromis au cours de l’année écoulée avaient activé le MFA ». Proofpoint signale une augmentation de 100 % des incidents réussis de prise de contrôle de comptes dans le cloud au cours des six derniers mois, les attaquants améliorant leurs techniques et filtrant même les cibles compromises en fonction de leur rôle organisationnel, ce qui semble être une méthode automatisée. Sur les centaines de comptes auxquels les attaquants ont accédé, 39 % étaient des cadres supérieurs, 17 % des directeurs financiers et 9 % des présidents et directeurs généraux. En ce qui concerne les cadres et le personnel de niveau inférieur, les attaquants se sont concentrés sur les utilisateurs ayant accès à des actifs financiers ou à des informations sensibles.
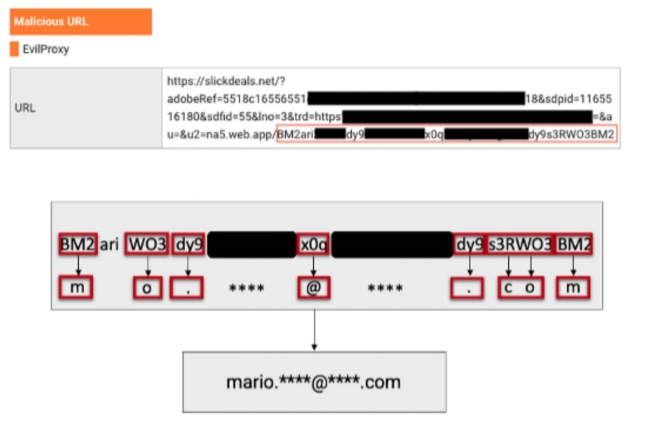
Les messages de phishing se faisaient passer pour des courriels automatisés générés par des services ou des applications de confiance tels que le système de gestion des frais professionnels Concur, DocuSign et Adobe Sign. Ils prétendaient contenir des notes de frais à approuver ou des documents à signer. Les URL incluses dans les courriels frauduleux conduisaient les victimes à travers une série de redirections. Tout d’abord, un script de redirection ouvert à partir d’un site web légitime, tel que YouTube ou SlickDeals. Ensuite, les navigateurs des victimes ont été redirigés à plusieurs reprises vers diverses pages et erreurs 404 dans le but probable de disperser le trafic et de rendre plus difficile la découverte par des outils automatisés. « Afin de dissimuler l’adresse électronique de l’utilisateur aux outils d’analyse automatique, les attaquants ont utilisé un codage spécial de l’adresse électronique de l’utilisateur et se sont servis de sites web légitimes qui avaient été piratés pour télécharger leur code PHP afin de décoder l’adresse électronique d’un utilisateur particulier », ont déclaré les chercheurs. « Après avoir décodé l’adresse électronique, l’utilisateur était redirigé vers le site web final – la page d’hameçonnage proprement dite, conçue sur mesure pour l’organisation de la cible ».
EvilProxy et la montée en puissance des outils de phishing en tant que service
La page de phishing, qui se faisait passer pour une page de connexion à Microsoft 365, a été créée à l’aide d’EvilProxy, un service de phishing qui fournit aux utilisateurs une interface graphique simple pour exécuter et gérer leurs campagnes et qui fait tout le travail en arrière-plan. EvilProxy fonctionne comme un reverse proxy, c’est-à-dire que le service se place entre l’utilisateur et la véritable page de connexion, relayant les demandes et les réponses dans les deux sens. Du point de vue de la victime, c’est comme si elle interagissait avec le vrai site web, mais l’attaquant peut voir tout ce qui est transmis entre les deux parties, y compris les identifiants de connexion et les codes MFA. EvilProxy prétend pouvoir contourner le MFA sur Apple, Gmail, Facebook, Microsoft, Twitter, GitHub, GoDaddy et d’autres sites populaires. Les outils comme EvilProxy s’inscrivent dans une tendance récente où les kits de phishing sont fournis en tant que service, ce qui permet même aux cybercriminels peu qualifiés de mettre en place une puissante campagne de phishing. Il leur suffit de choisir quelques options sur une interface de type pointer-cliquer. « Cette interface relativement simple et peu coûteuse a ouvert la voie à des activités de phishing MFA réussies », ont déclaré les chercheurs de Proofpoint.
Les attaquants à l’origine de la campagne observée par Proofpoint ont clairement donné la priorité aux cibles VIP dont les comptes ont été accédés quelques secondes après la compromission de leurs informations d’identification, tandis que les comptes moins intéressants n’ont jamais été réellement accédés même si leurs propriétaires sont tombés dans le piège de l’attaque par hameçonnage. Pour mettre en place un accès persistant aux comptes de grande valeur, les attaquants ont utilisé une application de Microsoft 365 appelée My Sign-Ins qui permet aux utilisateurs de gérer leurs organisations et leurs appareils, et de voir leurs sessions d’authentification. Plus important encore, l’application donne également aux utilisateurs la capacité de modifier les paramètres de sécurité de leur compte, y compris de changer ou d’ajouter des méthodes d’authentification multifacteurs. Les attaquants ont ajouté leur propre application d’authentification avec des mots de passe à usage unique basés sur le temps – codes TOTP – en plus du Microsoft Authenticator de l’utilisateur, qui utilise des notifications push sur l’appareil mobile. Cela leur permettait d’accéder au compte ultérieurement si la victime ne modifiait pas son mot de passe. « Les attaquants sont connus pour étudier la culture, la hiérarchie et les processus des organisations qu’ils ciblent, afin de préparer leurs attaques et d’améliorer leurs taux de réussite », ont déclaré les chercheurs. « Afin de rentabiliser leur accès, les attaquants ont été vus en train d’exécuter des fraudes financières, d’exfiltrer des données ou de participer à des transactions de piratage en tant que service (HaaS), en vendant l’accès à des comptes d’utilisateurs compromis ».
Des moyens de défense à activer
Pour se défendre contre de telles attaques, Microsoft conseille aux organisations de mettre en œuvre des méthodes d’AMF qui ne peuvent pas être interceptées par des techniques de proxy, telles que les clés USB physiques compatibles avec la norme FIDO2 ou l’authentification basée sur des certificats. Les politiques d’accès conditionnel peuvent également être utilisées pour évaluer les demandes de connexion en fonction de l’identité et de l’emplacement de l’appareil et pour mettre en œuvre une évaluation continue de l’accès afin de détecter lorsque des tokens d’authentification valides existants ne sont pas utilisés à partir des appareils ou des applications pour lesquels ils ont été émis.
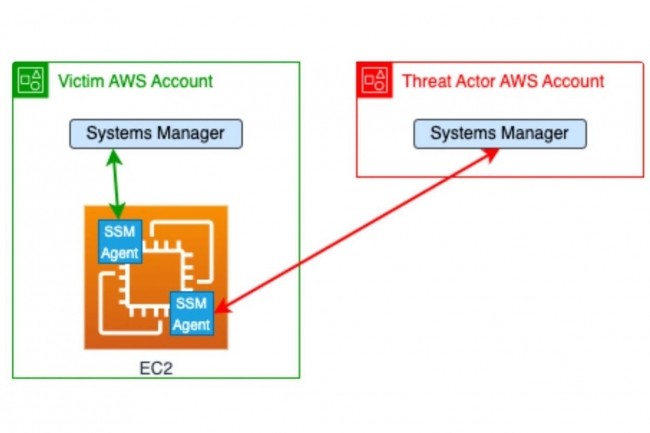
Des chercheurs en sécurité ont découvert que l’agent Systems Manager d’AWS peut être détourné pour lancer des attaques informatiques à distance. A l’origine, il est utilisé pour gérer et surveiller des environnements cloud et virtualisés.
Depuis de nombreuses années, les attaquants sont passés de l’utilisation de logiciels malveillants automatisés et personnalisés à des attaques qui impliquent un piratage pratique par le biais d’utilitaires qui existent déjà sur les ordinateurs. Cette approche, connue sous le nom de « living of the land », s’étend également à l’infrastructure cloud en exploitant les services et les outils que les fournisseurs mettent à disposition dans le cadre de leur écosystème. Des chercheurs de la société de réponse aux incidents Mitiga ont récemment montré comment l’agent AWS Systems Manager (SSM) pouvait être détourné par des attaquants et transformé en cheval de Troie d’accès distant (RAT). L’agent SSM est un outil que les clients du fournisseur américain peuvent déployer sur des instances EC2, des serveurs sur site, ainsi que des machines virtuelles dans d’autres clouds pour les gérer et les surveiller via son service Systems Manager.
« Le concept est simple : lorsqu’un attaquant réussit à obtenir l’exécution initiale sur un terminal qui a déjà un agent SSM installé, plutôt que de télécharger une porte dérobée ou un RAT commercial ou développé en interne, il peut l’exploiter pour contrôler le terminal, le transformant effectivement en un RAT lui-même », ont déclaré les chercheurs de Mitiga dans leur rapport. « En exécutant des commandes à partir d’un compte AWS distinct, détenu par des personnes malveillantes, les actions effectuées par l’agent SSM resteront cachées dans le compte AWS d’origine, ne laissant aucune trace de l’intrusion ».
Les raisons qui poussent à détourner un agent SSM
L’agent SSM est un outil puissant pour l’exécution de commandes à distance et la collecte de données sur la machine, comme le ferait un cheval de Troie. La différence est que l’agent SSM est open source, développé et signé numériquement par Amazon, et qu’il est préinstallé sur de nombreuses instances machines (AMI) que les clients peuvent déployer sur leurs instances EC2 comme Amazon Linux, SuSE Linux Enterprise, MacOS et Windows Server. Il est également présent dans certaines images système fournies par des tiers sur le marché AWS ou développées par la communauté. Le principal avantage pour les attaquants est que l’agent SSM est déjà inscrit sur la liste blanche de nombreuses solutions de détection et de réponse à incidents (EDR) ou d’antivirus susceptibles d’être déployées sur un serveur géré par AWS. Aucun des 71 moteurs antivirus de VirusTotal n’a signalé le binaire comme étant malveillant.
En outre, comme l’agent SSM peut être configuré pour communiquer avec un compte AWS spécifique, il apporte aux attaquants une option simple de commande et de contrôle sans avoir à développer ou à déployer une infrastructure supplémentaire qui serait généralement nécessaire pour héberger une interface de contrôle RAT. Tout ce dont ils ont besoin, c’est d’un compte AWS. L’interface PowerShell, native de Windows et conçue pour automatiser les tâches administratives, pourrait être utilisée en parallèle. Étant donné que PowerShell est si puissant et qu’il s’accompagne de son propre langage de script, il a été adopté au fil des ans par un très grand nombre d’attaquants, ce qui a obligé Microsoft à ajouter de plus en plus d’avertissements, de protections et d’alertes de sécurité. Néanmoins, il existe encore des frameworks entiers de post-exploitation et de mouvement latéral écrits en PowerShell, ainsi que des logiciels malveillants dont le code source est ouvert.
Faire tourner de multiples instances d’agents SSM
L’utilisation de l’agent SSM comme cheval de Troie ou porte dérobée n’est pas une idée nouvelle. D’autres ingénieurs cloud et chercheurs en sécurité ont mis en garde contre son potentiel d’abus. Cependant, Mitiga est allé plus loin en montrant comment détourner l’agent de manière plus subtile et même sans avoir d’accès root. La façon la plus directe d’abuser de l’agent SSM dans un scénario post-compromission où l’attaquant a déjà des privilèges root ou admin sur la machine, est d’arrêter le service et de le démarrer avec un nouveau code d’activation qui le lierait à un compte AWS contrôlé par l’attaquant et activerait son mode hybride. Dans ce cas, l’agent sera en mesure de mettre en place un mécanisme de persistance pour redémarrer le système. Le problème de cette approche est que le propriétaire du compte sous lequel tourne l’instance EC2 compromise pourra immédiatement se rendre compte que quelque chose ne va pas car il perdra l’accès SSM à cette machine sur son propre compte une fois que l’agent aura été détourné.
Pour résoudre ce problème, Mitiga a cherché des moyens de ne pas toucher à l’agent original et d’exécuter une deuxième instance malveillante se connectant au compte de l’attaquant. Bien que l’agent soit conçu pour ne pas s’exécuter s’il existe déjà un processus d’agent SSM, cela peut être contourné de plusieurs façons : en tirant parti de la fonctionnalité des espaces de noms Linux pour exécuter l’agent dans un espace de noms différent, ou en activant le mode « conteneur » pour la deuxième instance de l’agent qui ne nécessite pas de privilèges root. Le mode conteneur est limité car il ne dispose pas du module RunCommand mais il permet aux attaquants d’ouvrir une session à distance pour accéder à la machine.
Déploiement d’un deuxième processus d’agent SSM
Sur les machines Windows, les chercheurs ont réussi à lancer un deuxième processus d’agent SSM en configurant certaines variables d’environnement pour placer la configuration dans un emplacement différent. Ironiquement, une façon de déployer une seconde instance d’agent SSM sans avoir les privilèges root sur la machine elle-même est d’utiliser l’instance SSM existante et d’émettre des commandes à travers elle pour configurer la seconde, puisque l’agent fonctionne déjà avec des privilèges élevés. Cela nécessite un accès au compte AWS de la victime qui est déjà utilisé pour gérer la machine via SSM. Cela dit, la nécessité d’avoir un compte AWS pour contrôler un agent SSM détourné n’est pas forcément intéressante pour tous les attaquants.
Tout d’abord, s’ils utilisent le même compte pour contrôler plusieurs machines appartenant à différentes victimes, il suffit qu’un seul d’entre eux découvre la compromission, la signale à AWS et le compte sera suspendu. Il s’avère que l’agent SSM dispose de deux options de configuration appelées http_proxy et https_proxy qui peuvent être utilisées pour acheminer le trafic de l’agent SSM vers une adresse IP contrôlée par l’attaquant au lieu d’une adresse Amazon. Les chercheurs de Mitiga ont pu construire un serveur fictif qu’un pirate pourrait exécuter de son côté pour tirer parti de la fonction RunCommand sans s’appuyer sur le service SSM d’AWS.
Détecter et empêcher les attaques par l’agent SSM
Les chercheurs ont publié quelques indicateurs de compromission qui pourraient être utilisés pour détecter que deux instances d’agent SSM sont en cours d’exécution. Ils recommandent également de supprimer l’agent SSM de la liste d’autorisation de tout antivirus ou solution EDR afin qu’ils puissent analyser son comportement et ajouter des techniques de détection de ce type de détournement à leur solution SIEM.
« L’équipe de sécurité d’AWS a proposé une solution pour restreindre la réception des commandes du compte/organisation AWS d’origine à l’aide du point de terminaison Virtual Private Cloud pour Systems Manager », ont déclaré les chercheurs. « Si vos instances EC2 se trouvent dans un sous-réseau privé sans accès au réseau public via une adresse EIP publique ou une passerelle NAT, vous pouvez toujours configurer le service Systems Manager via un point de terminaison VPC. Ce faisant, vous pouvez vous assurer que les instances EC2 ne répondent qu’aux commandes émanant des mandants de leur compte AWS ou de leur organisation d’origine. Pour mettre en œuvre cette restriction de manière efficace, reportez-vous à la documentation relative à la politique des points d’extrémité VPC ».

Des attaques menées par le groupe de cybercriminels roumain Diicot ont été repérées et semblent principalement axées sur le cryptojacking. Mais l’acteur malveillant emploie également des botnets et des attaques par force brute à d’autres fins en s’appuyant sur une déclinaison du malware Mirai.
Selon des chercheurs en sécurité de Cado Labs, un groupe de cybercriminels se faisant appeler Diicot effectue des attaques massives par force brute et déploie une variante du botnet Mirai IoT sur des terminaux compromis. Le cybergang déploie également une charge utile de minage de crypto-monnaies sur des serveurs dotés d’un processeur de plus de quatre cœurs. « Bien que Diicot soit traditionnellement associé à des campagnes de cryptojacking, Cado Labs a découvert des preuves du déploiement par le groupe d’un agent de botnet basé sur Mirai, nommé Cayosin », ont déclaré les chercheurs de Cado Security dans une analyse de la campagne d’attaque récente et en cours du groupe. « Le déploiement de cet agent visait les routeurs utilisant le système d’exploitation OpenWrt basé sur Linux et destiné aux dispositifs embarqués ».
Diicot existe depuis au moins 2021 et s’appelait auparavant Mexals. Les chercheurs ont de fortes raisons de penser que le groupe est basé en Roumanie après avoir enquêté sur des chaînes de caractères trouvées dans ses charges utiles de logiciels malveillants, ses scripts et ses messages contre des groupes de pirates informatiques rivaux. Même son nouveau nom imite l’acronyme du Directorate for Investigating Organized Crime and Terrorism (DIICOT), un organisme roumain chargé de l’application de la loi qui, dans le cadre de son mandat de lutte contre le crime organisé, enquête également sur la cybercriminalité et engage des poursuites.
Des campagnes malveillantes au long cours
Lors des campagnes précédentes, documentées pour la première fois par l’éditeur d’antivirus Bitdefender en 2021, le groupe s’est principalement concentré sur le cryptojacking, une pratique consistant à détourner la puissance de calcul pour le minage de crypto-monnaies. Le groupe avait l’habitude de cibler les serveurs Linux dont les identifiants SSH étaient faibles en utilisant des scans de masse personnalisés et centralisés et des scripts de force brute essayant différentes combinaisons de noms d’utilisateur et de mots de passe. Si un serveur était compromis avec succès, le groupe déployait une version personnalisée du logiciel open source XMRig pour miner du Monero.
Les campagnes malveillantes se sont poursuivies, mais au début de l’année, des chercheurs d’Akamai ont noté le changement de nom du groupe et la diversification de sa boîte à outils d’attaque, avec l’ajout d’un ver SSH écrit en Golang et le déploiement d’une variante de Mirai appelée Cayosin. Mirai est un botnet qui se propage de lui-même et qui est conçu pour infecter les dispositifs de réseau intégrés. Il est apparu en 2016 et a été responsable de certaines des plus grandes attaques DDoS observées à l’époque. Le code source du botnet a ensuite été publié en ligne, ce qui a permis aux cybercriminels de développer de nombreuses autres variantes améliorées sur cette base.
Une série d’outils malveillants sur-mesure
La campagne d’attaque étudiée par Cado Security utilise un grand nombre des tactiques documentées par Bitdefender et Akamai et semble avoir commencé en avril 2023, lorsque le serveur Discord utilisé pour la commande et le contrôle a été créé. L’attaque commence par l’outil de force brute SSH Golang que le groupe appelle aliases. Celui-ci prend une liste d’adresses IP cibles et de paires nom d’utilisateur/mot de passe, puis tente de forcer l’authentification. Si le système compromis exécute OpenWRT, un système d’exploitation open source basé sur Linux pour les périphériques réseau tels que les routeurs, les attaquants déploieront un script appelé bins.sh qui est responsable de la détermination de l’architecture du processeur du périphérique et du déploiement d’un binaire Cayosin compilé pour cette architecture sous le nom cutie. Si le système n’utilise pas OpenWRT, aliases déploie l’une des nombreuses charges utiles binaires Linux créées à l’aide d’un outil open source appelé shell script compiler (SHC) et emballées avec UPX. Toutes ces payload servent de chargeurs de malware et préparent le système au déploiement de la variante XMRig.
L’une des charges utiles SHC exécute un script bash qui vérifie si le système dispose de quatre cœurs de processeur avant de déployer XMRig. Le script modifie également le mot de passe de l’utilisateur sous lequel il est exécuté. Si l’utilisateur est root, le mot de passe est fixé à une valeur codée en dur, mais si ce n’est pas le cas, celui-ci est généré dynamiquement à partir de la date actuelle. Le payload intègre également un autre exécutable SHC appelé .diicot ajoutant une clé SSH contrôlée par l’attaquant à l’utilisateur actuel afin de garantir un accès futur et de s’assurer que le service SSH est en cours d’exécution et enregistré en tant que service. Le script télécharge ensuite la variante personnalisée de XMRig et l’enregistre sous le nom Opera avec son fichier de configuration. Il crée également un script cron pour vérifier et relancer le processus Opera s’il n’est pas en cours d’exécution. L’outil de payload récupère un autre exécutable SHC « update » qui met en place l’outil de force brute de l’alias sur le système, et une copie du scanner de réseau Zmap sous le nom « chrome ». L’exécutable update diffuse également un script shell appelé « history » exécutant lui-même la mise à jour et créant ensuite un script cron garantissant que les exécutables history et chrome sont exécutés sur le système.
Des outils qui ne se limitent pas au cryptojacking
Le scanner chrome Zmap est exécuté sur un bloc réseau généré par l’outil de mise à jour et enregistre les résultats dans un fichier appelé bios.txt. Les cibles de ce fichier sont ensuite utilisées par des alias pour effectuer des attaques SSH par force brute avec une liste de noms d’utilisateur et de mots de passe que l’outil de mise à jour génère également. « L’utilisation de Cayosin démontre la volonté de Diicot de mener une variété d’attaques (pas seulement du cryptojacking) en fonction du type de cibles qu’ils rencontrent », ont déclaré les chercheurs du Cado. « Cette découverte est cohérente avec les recherches d’Akamai, ce qui suggère que le groupe continue d’investir des efforts d’ingénierie dans le déploiement de Cayosin. Ce faisant, Diicot a acquis la capacité de mener des attaques DDoS, car c’est l’objectif principal de Cayosin d’après les rapports précédents ».
Face à ces menaces, les entreprises devraient s’assurer qu’elles mettent en œuvre un renforcement de leurs connexions SSH pour leurs serveurs. Cela signifie utiliser une authentification par clé plutôt que par mot de passe et utiliser des règles de pare-feu pour restreindre l’accès SSH aux seules adresses IP de confiance. Selon les chercheurs, la détection d’un scan Diicot à partir d’un système devrait être simple au niveau du réseau, car il est assez bruyant.