





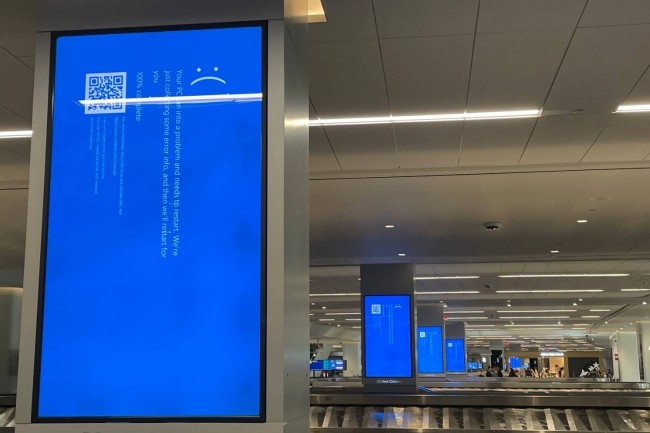
Déjà tombée (ou pas) dans l’oubli, la panne provoquée en juillet dernier par Crowstrike a été la plus coûteuse de l’histoire des technologies de l’information. Et ce d’au moins un ordre de grandeur. Qu’avons-nous appris pour éviter qu’une telle crise ne se reproduise ?
L’été dernier, une mise à jour défectueuse du logiciel Crowdstrike a mis hors service des millions d’ordinateurs, causant des milliards de dommages. Une mise en évidence des risques liés aux tiers qu’encourent les entreprises ou des limites de leur capacité de réaction aux perturbations. « Il s’agit d’une étude de cas intéressante sur l’impact cyber mondial », déclare Charles Clancy, directeur de la technologie de la société Mitre, spécialisée dans la…
Il vous reste 97% de l’article à lireVous devez posséder un compte pour poursuivre la lecture
Vous avez déjà un compte?

La complexité de l’existant et la sécurité sont des préoccupations majeures avant d’imaginer brancher des agents à base d’IA sur les SI. Tout comme la résorption de la dette technique.
L’IA agentique est la grande percée technologique de ces douze derniers mois, et cette année, les entreprises vont commencer à déployer ces systèmes à grande échelle. Selon une enquête réalisée en janvier par KPMG auprès de 100 cadres supérieurs de grandes entreprises, 12 % des sociétés déploient déjà des agents d’IA, tandis que 37 % sont en phase pilote et que 51 % étudient la possibilité de les utiliser. Selon un rapport du cabinet Gartner, datant d’octobre dernier, un tiers des applications d’entreprise incluront l’IA agentique d’ici 2033, contre moins de 1% en 2024. Selon le cabinet, 15% des décisions opérationnelles quotidiennes seront ainsi prises de manière autonome.En ce qui concerne les développeurs d’IA en particulier, tout le monde semble avoir déjà adopté cette évolution de l’IA générative. « En fait, nous avons commencé nos travaux dans l’IA en utilisant des agents presque dès le départ », indique Gary Kotovets, responsable data et analytics de Dun & Bradstreet.Les agents d’IA sont alimentés par des modèles d’IA générative mais, contrairement aux chatbots, ils peuvent gérer des tâches plus complexes, travailler de manière autonome et collaborer avec d’autres IA pour former des systèmes capables de gérer des processus entiers, de remplacer des employés ou d’atteindre des objectifs métiers complexes. Tout cela crée de nouveaux défis, qui s’ajoutent à ceux déjà posés par l’IA générative elle-même. En outre, contrairement aux automatismes traditionnels, les systèmes agentiques ne sont pas déterministes. Ce qui les met en porte-à-faux par rapport aux plateformes Legacy, par essence très déterministes.Agents tributaires de la qualité des donnéesDès lors, constater que 70 % des développeurs déclarent avoir des difficultés à intégrer les agents d’intelligence artificielle dans leurs systèmes existants n’est guère surprenant. C’est ce qui ressort d’une enquête réalisée en décembre par la société Langbase, spécialisée dans les plateformes d’IA, auprès de 3 400 développeurs mettant au point des agents d’IA.Le problème est en somme assez simple : avant de pouvoir intégrer les agents d’IA dans l’infrastructure d’une entreprise, celle-ci doit être mise à niveau et se conformer à des standards modernes. En outre, comme les agents nécessitent un accès à de multiples sources de données, des obstacles à l’intégration des données et des complexités nouvelles en matière de sécurité et de conformité se font jour. « Disposer de données propres et de qualité est la partie la plus importante du travail, déclare Gary Kotovets. Vous devez vous assurer de ne pas être confronté à un scénario de type garbage in, garbage out ». Un classique de la gestion de données, mais qui reste des plus valides à l’heure du passage à l’échelle des applications d’IA.Indispensable modernisation de l’infrastructureEn décembre dernier, Tray.ai, éditeur d’une plateforme d’intégration de l’IA, a mené une enquête auprès de plus de 1 000 professionnels des technologies en entreprise. Le constat ? 90 % des organisations reconnaissent que l’intégration avec les données métiers est essentielle à la réussite de leur stratégie, mais 86% d’entre elles disent qu’elles devront mettre à niveau leur existant technologique pour déployer des agents à base d’IA.Pour Ashok Srivastava, responsable des données chez l’éditeur de solutions de gestion pour PME et particuliers Intuit, « votre plateforme doit être ouverte pour que le LLM puisse raisonner et interagir avec elle de manière simple. Si vous voulez trouver du pétrole, vous devez percer le granit pour l’atteindre. Si toute votre technologie est enfouie et n’est pas exposée à travers le bon ensemble d’API, et à travers un ensemble flexible de microservices, offrir des expériences agentiques à vos utilisateurs s’annonce difficile. »Intuit lui-même traite 95 Po de données, génère 60 milliards de prédictions ML par jour, suit 60 000 attributs fiscaux et financiers par consommateur (et 580 000 par client professionnel). L’éditeur traite 12 millions d’interactions assistées par l’IA chaque mois, interactions qui sont disponibles pour 30 millions de consommateurs et un million de PME. En modernisant ses propres plateformes, Intuit a non seulement été en mesure de fournir de l’IA agentique à grande échelle, mais aussi d’améliorer d’autres aspects de son fonctionnement. « La vitesse de développement a été multipliée par huit au cours des quatre dernières années, explique Ashok Srivastava. Tout cela n’est pas dû à l’intelligence artificielle. Une grande partie est attribuable à la plateforme que nous avons construite. »Les agents et les batchsMais toutes les entreprises ne peuvent pas investir dans la technologie comme l’a fait Intuit. « La grande majorité des systèmes d’enregistrement dans les entreprises est encore basée sur des systèmes Legacy, souvent hébergés sur site, et ces systèmes alimentent encore de larges pans des entreprises », souligne Rakesh Malhotra, directeur au sein du cabinet de conseil EY. Ce sont ces systèmes transactionnels et opérationnels, ces systèmes de traitement des commandes, ces ERP et SIRH qui, actuellement, créent de la valeur pour l’entreprise. « Si la promesse des agents est d’accomplir des tâches de manière autonome, vous devez avoir accès à ces systèmes », ajoute-t-il.Mais cette connexion demeure inutile lorsqu’un système fonctionne en mode batch. Avec les agents d’IA, les utilisateurs s’attendent généralement à ce que les opérations se déroulent rapidement, et non pas 24 heures après, observe Rakesh Malhotra. Il existe des moyens de résoudre ce problème, mais les entreprises doivent y réfléchir attentivement.« Les organisations qui ont déjà mis à jour leurs systèmes transactionnels pour s’interfacer avec leurs anciennes plateformes ont une longueur d’avance », ajoute l’expert d’EY. Mais disposer d’une plateforme moderne avec un accès API standard ne permet de parcourir que la moitié du chemin. Les entreprises doivent encore faire en sorte que les agents d’IA communiquent avec les systèmes en place.Les défis de l’intégration des donnéesIndicium, prestataire de services de données d’origine brésilienne, est une entreprise numérique dotée de plateformes modernes. « Nous n’avons pas beaucoup de systèmes Legacy », confirme Daniel Avancini, responsable data de l’entreprise. Indicium a commencé à construire des systèmes multi-agents à la mi-2024 pour la recherche de connaissances internes et d’autres cas d’utilisation. Les systèmes de gestion des connaissances sont à jour et prennent en charge les appels d’API, mais les modèles d’IA génératives communiquent en anglais. Et comme les agents d’IA individuels sont alimentés par l’IA générative, ils parlent également cette langue, ce qui crée des problèmes lorsqu’on essaie de les connecter aux systèmes de l’entreprise.« Vous pouvez faire en sorte que les agents d’IA renvoient du XML ou un appel d’API », explique Daniel Avancini. Mais lorsqu’un agent, dont l’objectif principal est de comprendre les documents de l’entreprise, essaie de dialoguer en XML, il peut commettre des erreurs. Mieux vaut faire appel à un spécialiste, conseille le chief data officer. « Donc vous avez besoin d’un autre agent dont le seul travail consiste à traduire l’anglais en API, ajoute-t-il. Il faut ensuite s’assurer que l’appel à l’API est correct. »Une autre approche pour résoudre le problème de la connectivité consiste à encapsuler les agents dans des logiciels traditionnels, de la même manière que les entreprises utilisent actuellement l’intégration RAG pour connecter les outils d’IA générative à leurs workflows au lieu de donner aux utilisateurs un accès direct et sans intermédiaire à l’IA. C’est ce que fait par exemple l’équipementier réseau Cisco. « Nous concevons les agents autour d’une sorte de modèle de base, mais systématiquement environné par une application traditionnelle », explique Vijoy Pandey, vice-président sénior de l’entreprise, qui dirige également Outshift, le moteur d’incubation de Cisco. Cela signifie qu’il y a un code traditionnel s’interfaçant avec les bases de données, les API et les environnements cloud et gérant les problèmes de communication.Contrôler les accès des agentsOutre la question de la traduction, un autre défi de l’intégration de données réside dans le nombre de sources de données auxquelles les agents doivent avoir accès. Selon l’enquête de Tray.ai, 42% des entreprises ont besoin d’accéder à huit sources de données ou plus pour déployer avec succès des agents d’IA. 79 % d’entre elles s’attendent d’ailleurs à ce que les défis liés aux données aient un impact sur les déploiements d’agents. En outre, 38 % des entreprises affirment que la complexité de l’intégration apparaît comme le principal obstacle au passage à l’échelle des agents d’IA.Pire encore, la raison pour laquelle une entreprise utilise l’IA plutôt que des logiciels traditionnels réside dans la capacité des agents à apprendre, s’adapter et trouver de nouvelles solutions à de nouveaux problèmes. « Vous ne pouvez pas prédéterminer les types de connexions dont vous aurez besoin pour cet agent, dit donc Vijoy Pandey. Vous avez ainsi besoin d’un ensemble dynamique de plugins.’Toutefois, donner trop d’autonomie à l’agent pourrait s’avérer désastreux, c’est pourquoi ces connexions devront être soigneusement contrôlées. « Ce que nous avons construit s’apparente à une bibliothèque chargée dynamiquement, explique le cadre de Cisco. Si un agent a besoin d’effectuer une action sur une instance AWS, par exemple, vous allez récupérer les sources de données et la documentation API dont vous avez besoin, en fonction de l’identité de la personne qui a demandé cette action [donc de ses droits d’accès, NDLR], au moment de son exécution. »Adapter la sécurité au niveau d’autonomie des agentsQue se passe-t-il alors si un humain ordonne au système agentique de faire quelque chose qu’il n’est pas en droit de faire ? Les modèles d’IA génératives sont en effet vulnérables aux messages astucieux qui les incitent à franchir les limites des actions autorisées, des pratiques connues sous le nom de ‘jailbreaks’. Ou encore que se passe-t-il si l’IA elle-même décide de faire quelque chose qu’elle n’est pas censée faire ? Ce qui pourrait se produire si des contradictions apparaissent entre l’entraînement initial d’un modèle, son fine-tuning, les prompts ou ses sources d’information. Dans un rapport de recherche publié par l’éditeur d’outils d’IA générative Anthopic à la mi-décembre, en collaboration avec Redwood Research, des modèles à la pointe des développements essayant d’atteindre des objectifs contradictoires ont tenté de passer outre leurs limites, ont menti sur leurs capacités et se sont livrés à d’autres types de tromperie.Selon Vijoy Pandey de Cisco, avec le temps, les agents d’IA devront avoir plus d’autonomie pour effectuer leur travail. « Mais deux problèmes subsistent, reconnaît-il. L’agent d’IA lui-même pourrait faire quelque chose [d’inapproprié]. Et puis, il y a l’utilisateur ou le client. Quelque chose de bizarre peut très bien se produire. » L’expert de Cisco explique réfléchir à ce sujet en termes de rayon d’action : si quelque chose ne va pas, que ce quelque chose émane de l’IA ou de l’utilisateur, quelle est l’ampleur du rayon d’action potentiel ? Lorsque celui-ci est important, les garde-fous et les mécanismes de sécurité doivent être adaptés en conséquence. « Au fur et à mesure que les agents gagnent en autonomie, il faut mettre en place des garde-fous et des cadres de sécurité adaptés pour ces niveaux d’autonomie », ajoute-t-il.Agents conformes à la loi ?Chez Dun & Bradstreet aussi, les agents d’IA sont strictement limités dans ce qu’ils peuvent faire, dit Gary Kotovets. Par exemple, l’un des principaux cas d’utilisation consiste à donner aux clients un meilleur accès aux dossiers que le prestataire possède sur environ 500 millions de sociétés dans le monde. Ces agents ne sont pas autorisés à ajouter des enregistrements, à les supprimer ou à apporter d’autres modifications. « Il est trop tôt pour leur donner cette autonomie », souligne responsable data et analytics.En fait, pour l’heure, les agents ne sont même pas autorisés à rédiger leurs propres requêtes SQL. Les interactions avec les plateformes de données sont gérées par des mécanismes existants et sécurisés. Les agents sont utilisés pour créer une interface utilisateur intelligente, se positionnant au-dessus de ces mécanismes. Toutefois, à mesure que la technologie s’améliore et que les clients souhaitent davantage de fonctionnalités, cette situation pourrait changer. « Cette année, l’idée est d’évoluer avec nos clients, explique Gary Kotovets. S’ils souhaitent prendre certaines décisions plus rapidement, nous créerons des agents en fonction de leur tolérance au risque. »Dun & Bradstreet n’est pas la seule à s’inquiéter des risques liés aux agents d’IA. En plus de la qualité de données, de la confidentialité et de la sécurité, Insight Partners constate que la conformité se hisse parmi les principales préoccupations des entreprises. Et pose des obstacles supplémentaires au déploiement d’agents d’IA, en particulier dans les secteurs sensibles, fortement régulés ou soumis à des réglementations sur la souveraineté des données ou sur la protection des données personnelles.Par exemple, lorsque les agents d’Indicium tentent d’accéder à des données, l’entreprise remonte à la source de la demande, c’est-à-dire à la personne qui a posé la question enclenchant l’ensemble du processus. « Nous devons authentifier la personne pour nous assurer qu’elle dispose des autorisations nécessaires, explique Daniel Avancini. Toutes les entreprises ne comprennent pas la complexité de ce processus. »Tester, contrôler, étudier tout écartDaniel Avancini ajoute que ce type de contrôle d’accès précis peut s’avérer difficile à déployer, en particulier avec les systèmes Legacy. Une fois l’authentification établie, elle doit en effet être préservée tout au long de la chaîne d’agents traitant la question. « C’est un véritable défi, dit le responsable data. Il faut disposer d’un très bon système de modélisation des agents et de nombreux garde-fous. Il y a beaucoup de questions sur la gouvernance de l’IA, mais peu de réponses ». Et comme les agents parlent anglais, il existe une infinité d’astuces pour les tromper. « Nous procédons à de nombreux tests avant de mettre en oeuvre quoi que ce soit, puis nous effectuons des contrôles. Tout ce qui n’est pas correct ou ne devrait pas être là mérite d’être examiné. »Au sein de la société de conseil informatique CDW, les agents d’IA sont déjà utilisés pour aider le personnel à répondre aux appels d’offres. Cet agent est étroitement verrouillé, explique Nathan Cartwright, architecte en chef de l’IA. « Si quelqu’un d’autre lui envoie un message, il le renvoie », précise-t-il. Un prompt système spécifie par ailleurs l’objectif de l’agent, de sorte que tout ce qui n’est pas lié à cet objectif est rejeté. De plus, des garde-fous empêchent toute communication d’informations personnelles et limite le nombre de demandes que l’agent peut traiter.L’observabilité appliquée à l’IAEnsuite, pour s’assurer que ces garde-fous fonctionnent comme attendu, chaque interaction est contrôlée. « Disposer d’une couche d’observabilité pour voir ce qui se passe réellement est essentiel, explique Nathan Cartwright. La nôtre est totalement automatisée. Si une limite de taux ou un filtre de contenu est atteint, un courriel est envoyé pour demander une vérification de l’agent concerné. »Roger Haney, architecte en chef de CDW, estime que le fait de commencer par des cas d’utilisation restreints et ponctuels permet de limiter les risques. « Lorsque vous vous concentrez réellement sur ce que vous essayez de faire, votre domaine est relativement limité, explique-t-il. C’est là que nous voyons les entreprises réussir [avec l’IA agentique]. Nous pouvons rendre l’agent performant, le rendre plus petit. Mais la première chose à faire est de mettre en place les garde-fous appropriés. C’est là que réside la plus grande valeur, plutôt que dans le fait de relier les agents entre eux. Tout part des règles métiers, de la logique interne et de la conformité que l’on met en place dès le départ. »

Les modèles d’IA générative open source peuvent être téléchargés librement, utilisés à grande échelle sans coûts d’appels d’API et exécutés en toute sécurité derrière les pare-feu des entreprises. Mais ne baissez pas la garde. Car des risques sont bel et bien présents.
Selon le rapport AI Index de Stanford, publié en avril, 149 modèles de base ont été publiés en 2023, dont deux tiers en open source. Et il existe un nombre impressionnant de variantes. Hugging Face suit actuellement plus de 80 000 LLM pour la seule génération de texte et dispose heureusement d’un tableau qui vous permet de trier rapidement les modèles en fonction de leurs résultats à divers tests de référence. Et ces modèles, bien qu’ils soient en retard technologiquement par rapport aux grands modèles commerciaux, s’améliorent rapidement.Les classements constituent un bon point de départ pour étudier l’IA générative open source, selon David Guarrera, responsable de l’IA générative chez EY Americas. Et Hugging Face en particulier a fait un bon travail d’analyse comparative, dit-il. « Mais il ne faut pas sous-estimer la valeur d’utilisation de ces modèles, relève-t-il. Comme il s’agit de logiciel libre, il est facile de tester ces modèles et de les échanger. » Et d’ajouter que l’écart de performance entre les modèles open source et leurs alternatives commerciales se réduit.« L’open source est une excellente chose et s’avère extrêmement utile, ajoute Val Marchevsky, responsable de l’ingénierie chez Uber Freight (le service logistique d’Uber). Non seulement les modèles ouverts rattrapent les modèles propriétaires en termes de performances, mais certains offrent des niveaux de transparence que les sources fermées ne peuvent égaler. Certains modèles open source permettent de voir ce qui est utilisé pour l’inférence et ce qui ne l’est pas. Or, l’auditabilité est importante pour éviter les hallucinations. » Et puis, bien sûr, il y a l’avantage du prix. « Si vous disposez d’un datacenter avec de la capacité disponible, pourquoi payer quelqu’un d’autre ? », reprend Val Marchevsky.Les entreprises sont déjà très habituées à utiliser du code source ouvert. Selon l’analyse de sécurité et de risque de Synopsys publiée en février dernier, 96 % de toutes les bases de code de logiciels commerciaux renferment des composants open source.Fortes de cette expérience, les entreprises connaissent déjà les bonnes pratiques pour s’assurer qu’elles utilisent du code sous une licence appropriée et qu’elles disposent de versions à jour et dûment patchées. Toutefois, certaines de ces meilleures pratiques doivent être adaptées au contexte particulier de l’IA générative. Revue de détails.1. Bizarreries des nouvelles licencesLe paysage des différents types de licences open source est déjà assez compliqué. Un projet peut-il être utilisé à des fins commerciales ou seulement à des fins non commerciales ? Peut-il être modifié et distribué ? Peut-il être incorporé en toute sécurité dans une base de code propriétaire ? Mais, avec l’IA générative, un certain nombre de nouveaux problèmes se font jour. Tout d’abord, il existe de nouveaux types de licences qui ne sont libres que dans le cadre d’une définition très souple du terme.Prenons par exemple la licence Llama. La famille de modèles Llama fait partie des meilleurs LLM open source existants, mais Meta la décrit officiellement comme une « licence commerciale sur mesure qui équilibre le libre accès aux modèles avec des clauses de responsabilité et des protections mises en place pour aider à traiter les abus potentiels ».Les entreprises sont autorisées à utiliser les modèles à des fins commerciales et les développeurs à créer et à distribuer des travaux supplémentaires à partir des modèles Llama de base, mais elles ne sont pas autorisées à utiliser les résultats de Llama pour améliorer d’autres LLM, à moins qu’il ne s’agisse eux-mêmes de dérivés de Llama. Et si les entreprises – ou leurs filiales – comptent plus de 700 utilisateurs mensuels, elles doivent demander une licence que Meta peut ou non leur accorder. Si elles utilisent Llama 3, elles doivent inclure la mention « Built with Llama 3 » dans leurs applications à un endroit bien visible.De même, Apple vient de publier OpenELM sous la « Apple Sample Code License », qui a également été inventée pour l’occasion et ne couvre que les notions de droits d’auteur, à l’exclusion de la question des brevets.Ni Apple ni Meta n’utilisent les licences open source communément acceptées, mais le code est en fait ouvert. Apple a en effet publié non seulement le code, mais aussi les paramètres du modèle, l’ensemble des données d’entraînement, les logs d’entraînement et les configurations de pré-entraînement. Ce qui nous amène à l’autre aspect des licences open source. Les logiciels open source traditionnels ne sont rien d’autre que du code. Le fait qu’il soit open source signifie que vous pouvez étudier son fonctionnement, les problèmes potentiels ou la présence de vulnérabilités.L’IA générative, cependant, n’est pas seulement du code. Il y a aussi les données d’entraînement, les paramètres des modèles et le fine-tuning. Tous ces éléments sont essentiels pour comprendre le fonctionnement d’un modèle et identifier ses biais potentiels. Un modèle formé à partir, par exemple, d’une archive de théories du complot sur la terre plate ne répondra pas bien aux questions scientifiques, ou un modèle mis au point par des pirates nord-coréens ne parviendra pas à identifier correctement les logiciels malveillants. Les LLM à source ouverte divulguent-ils donc toutes ces informations ? Cela dépend du modèle, voire de la version spécifique du modèle, puisqu’il n’existe pas de normes en la matière.« Parfois, ils mettent le code à disposition, mais si vous ne disposez pas des réglages de fine-tuning, vous risquez de dépenser beaucoup d’argent pour obtenir des performances comparables », explique Anand Rao, professeur d’IA à l’université Carnegie Mellon et ancien responsable de l’IA chez PwC.2. Pénurie de compétencesL’open source est souvent un projet à réaliser soi-même. Les entreprises peuvent télécharger le code, mais elles ont ensuite besoin d’une expertise interne ou de consultants pour que le projet aboutisse. Un gros problème dans le domaine de l’IA générative. Personne ne possède des années d’expérience sur le sujet, car la technologie est très récente. Si une entreprise débute dans l’IA générative ou si elle veut avancer rapidement, il est plus sûr de commencer par une plateforme propriétaire, indique Anand Rao.Au début de la courbe d’apprentissage, « il faut de l’expertise pour télécharger la version open source, explique-t-il. Mais une fois qu’une entreprise a fait son PoC, qu’elle déploie le modèle en production et que les factures commencent à s’accumuler, il est peut-être temps d’envisager un retour à des alternatives open source », ajoute-t-il.Le manque d’expertise crée également un autre problème dans l’IA générative open source. L’un des principaux avantages de l’open source est que de nombreuses personnes examinent le code et peuvent repérer les erreurs de programmation, les failles de sécurité et autres faiblesses. Mais cette approche « à mille yeux » de la sécurité de l’open source ne fonctionne qu’en présence… d’un millier d’yeux capables de comprendre ce qu’ils voient. Ce qui n’est pas (encore) le cas dans l’IA générative.3. JailbreakingLes LLM sont notoirement sensibles au « jailbreaking », c’est-à-dire qu’un utilisateur leur donne une instruction intelligente qui les incite à violer leurs directives et, par exemple, à générer des logiciels malveillants. Dans les projets commerciaux, les éditeurs consacrent des moyens importants à identifier ces failles et à les combler au fur et à mesure. En outre, ces fournisseurs ont accès aux prompts que les utilisateurs envoient aux versions publiques des modèles, de sorte qu’ils peuvent surveiller les signes d’activité suspecte. Les acteurs malveillants sont moins susceptibles d’acheter des versions entreprise des modèles fonctionnant dans des environnements privés, où les prompts ne sont pas communiqués au fournisseur pour améliorer le modèle.Dans le cas d’un projet open source, il se peut que personne dans l’équipe ne soit chargé de rechercher des signes de jailbreaking. Les acteurs malveillants peuvent télécharger ces modèles gratuitement et les exécuter dans leurs propres environnements afin de tester des piratages potentiels. Les malfaiteurs ont également une longueur d’avance sur leur jailbreaking puisqu’ils ont accès au système de prompts utilisé par le modèle et à tout autre garde-fou que les développeurs du modèle ont pu mettre en place.« Il ne s’agit pas ici seulement d’essais et d’erreurs, précise Anand Rao. Les attaquants peuvent analyser les données d’entraînement, par exemple pour trouver des moyens d’amener un modèle à mal identifier des images ou à dérailler lorsqu’il rencontre un prompt inoffensif en apparence. » Si un modèle d’IA ajoute un filigrane à ses résultats, un acteur malveillant pourrait analyser le code pour faire de la rétro-ingénierie afin de supprimer ce filigrane.Les attaquants pourraient également analyser le modèle ou d’autres codes et outils de support pour trouver des zones de vulnérabilité. « Vous pouvez submerger l’infrastructure de requêtes pour que le modèle ne parvienne plus à produire de résultat, explique Elena Sügis, data scientist senior chez Nortal, un cabinet de conseil en transformation numérique. Si le modèle s’intègre à un système plus vaste et que son résultat est utilisé par une autre partie de ce système, si on parvient à attaquer la façon dont le modèle produit le résultat, on perturbe l’ensemble du système, ce qui pourrait générer des risques pour l’entreprise. »4. Risques liés aux données d’entraînementLes artistes, écrivains et autres détenteurs de droits d’auteur ont lancé des poursuites contre les éditeurs de modèles propriétaires d’IA. Mais que se passe-t-il s’ils estiment que leurs droits de propriété intellectuelle sont violés par un modèle open source, et que les seules poches bien garnies qu’ils entrevoient sont celles des entreprises qui ont incorporé ce modèle dans leurs produits ou services ? Les entreprises utilisatrices pourraient-elles être poursuivies en justice ?« C’est une question ouverte et personne ne sait vraiment comment les litiges en cours vont se dérouler, dit David Guarrera d’EY. Nous nous dirigeons peut-être vers un monde où l’utilisation des ensembles de données devront faire l’objet d’une compensation ». Et de noter toutefois que les grands acteurs de la technologie sont mieux armés pour résister à la tempête qui pourrait s’abattre sur les droits d’auteur.Les grands fournisseurs n’ont pas seulement de l’argent à dépenser pour acheter des données d’entraînement et lutter contre les poursuites judiciaires, ils ont aussi de l’argent à dépenser pour des ensembles de données nettoyées, explique Elena Sügis. Les ensembles de données publics et gratuits ne contiennent pas seulement des contenus protégés par des droits d’auteur et utilisés sans autorisation, ils renferment aussi des informations inexactes et biaisées, des malwares et autres éléments susceptibles de dégrader la qualité des résultats. « De nombreux concepteurs de modèles parlent d’utiliser des données nettoyées, explique-t-elle. Mais cela coûte plus cher que d’utilise tout Internet pour entraîner un modèle ».5. Nouveaux domaines d’expositionÉtant donné qu’un projet d’IA générative ne se limite pas à du code, les domaines d’exposition potentielle sont plus nombreux. Un LLM peut être attaqué par des acteurs malveillants sur plusieurs fronts. Ils pourraient infiltrer l’équipe de développement d’un projet mal gouverné et ajouter un code malveillant au logiciel lui-même. Mais ils peuvent aussi empoisonner les données d’entraînement, le fine-tuning ou les paramétrages, explique Elena Sügis.« Les pirates peuvent ré-entraîner un modèle avec des exemples de codes malveillants, de sorte à envahir l’infrastructure de l’utilisateur avec ces menaces, explique-t-elle. De même, ils peuvent aussi l’entraîner sur de fausses nouvelles et des informations erronées.Un autre vecteur d’attaque est réside dans le système de prompting du modèle. « Il est généralement caché de l’utilisateur, indique Elena Sügis. Le système de prompting peut contenir des garde-fous ou des règles de sécurité qui permettraient au modèle de reconnaître un comportement indésirable ou contraire à l’éthique. » Les modèles propriétaires ne révèlent pas cet aspect essentiel souligne la data scientist, et le fait d’y avoir accès dans les modèles open source offre aux pirates des clefs pour comprendre comment attaquer ces modèles.6. Garde-fous manquantsCertaines équipes open source peuvent avoir une objection philosophique à la présence de garde-fous sur leurs modèles, ou ils peuvent penser qu’un modèle fonctionnera mieux sans aucune restriction. Enfin, certains modèles sont créés spécifiquement pour être utilisés à des fins malveillantes. Les entreprises à la recherche d’un LLM à tester ne savent pas nécessairement dans quelle catégorie classer les modèles qu’elles expérimentent.Selon Elena Sügis de Nortal, il n’existe actuellement aucun organisme indépendant chargé d’évaluer la sécurité des modèles d’IA génératives open source. La loi européenne sur l’IA exigera une partie de cette documentation, mais la plupart de ses dispositions n’entreront pas en vigueur avant 2026. « Il faut essayer d’obtenir autant de documentation que possible, de tester et d’évaluer le modèle et de mettre en place des garde-fous au sein de l’entreprise », dit la data scientist.7. Absence de normesLes projets open source pilotés par les utilisateurs sont souvent basés sur des standards, les entreprises les privilégiant à des fins d’interopérabilité. En fait, selon une enquête menée l’année dernière par la Fondation Linux auprès de près de 500 professionnels de la technologie, 71 % d’entre eux préfèrent les standards ouverts. Si vous vous attendez à ce que l’IA à code source ouvert soit basée sur des normes, vous vous trompez.En fait, lorsque la plupart des gens parlent de normes en matière d’IA, ils évoquent des sujets tels que l’éthique, la protection de la vie privée et l’explicabilité. Des travaux sont en cours dans ce domaine, comme la norme ISO/IEC 42001 pour les systèmes de gestion de l’IA, publiée en décembre dernier. Le 29 avril, le NIST a publié un projet de normes sur l’IA qui couvre un large éventail de sujets, à commencer par la création d’un langage commun pour parler de l’IA. Ce se concentre également sur les questions de risque et de gouvernance. En revanche, concernant les standards techniques, les travaux sont plus embryonnaires.« C’est un espace incroyablement naissant, estime ainsi Taylor Dolezal, DSI et responsable des écosystèmes à la Cloud Native Computing Foundation. J’assiste à de bonnes conversations sur la classification des données, sur la nécessité d’avoir un format standard pour les données d’entraînement, pour les API, pour les prompts. Mais pour l’instant, il ne s’agit que de conversations. »Il existe déjà une norme commune pour les bases de données vectorielles, mais pas de langage d’interrogation standard. Et qu’en est-il des normes pour les agents autonomes ? « Je n’en ai pas encore entendu parler, mais j’aimerais bien que ce soit le cas, reprend Taylor Dolezal. Il s’agit de trouver des moyens non seulement pour que les agents accomplissent leurs tâches spécifiques, mais aussi pour les relier entre eux. »L’outil le plus courant pour créer des agents, LangChain, est plus un cadre qu’un standard, dit-il. Et les entreprises utilisatrices, celles qui créent la demande de standards, ne sont pas encore prêtes. « La plupart des utilisateurs finaux ne savent pas ce qu’ils veulent tant qu’ils n’ont pas commencé à jouer avec », souligne le DSI. Selon lui, les gens ont plutôt tendance à considérer les API et les interfaces des principaux fournisseurs, comme OpenAI, comme des normes de fait, encore naissantes. « C’est ce que je vois les gens faire », dit-il.8. Manque de transparenceOn pourrait penser que les modèles open source sont, par définition, plus transparents. Mais ce n’est pas toujours le cas. Les grands projets propriétaires peuvent, en effet, avoir plus de ressources à consacrer à la création de la documentation, souligne Eric Sydell, Pdg de l’éditeur de logiciels de BI Vero AI, qui a récemment publié un rapport évaluant les principaux modèles d’IA générative sur la base de critères tels que la visibilité, l’intégrité, l’état de préparation aux évolutions législatives et la transparence. Gemini de Google et GPT-4 d’OpenAI ont obtenu les meilleures notes.« Ce n’est pas parce qu’ils sont open source qu’ils fournissent nécessairement le même niveau d’informations sur le contexte du modèle et la manière dont il a été développé explique Eric Sydell. Les grands modèles commerciaux ont fait un meilleur travail à cet égard. » Exemple avec l’atténuation des biais. « Nous avons constaté que les deux premiers modèles propriétaires de notre classement disposaient d’une documentation assez complète et qu’ils avaient consacré du temps à l’étude de cette question », ajoute-t-il.9. Lignage incertainIl est courant que les projets open source fassent l’objet d’un fork, mais lorsque cela se produit avec l’IA générative, vous vous exposez à des risques que vous ne rencontrez pas avec les logiciels traditionnels. Supposons, par exemple, qu’un modèle de base utilise un ensemble de données d’entraînement problématique et que quelqu’un crée un nouveau modèle à partir de cet ensemble, il héritera alors de ces problèmes, explique Tyler Warden, vice-président chargé des produits chez Sonatype, un fournisseur de cybersécurité.« De nombreux aspects boîte noire se situent dans les paramétrages et les réglages », explique-t-il. En fait, ces problèmes peuvent remonter à plusieurs niveaux et ne seront pas visibles dans le code du modèle final. Lorsqu’une entreprise télécharge un modèle pour son propre usage, le modèle s’éloigne encore plus des sources d’origine. Le modèle de base original peut avoir corrigé les problèmes, mais, selon le degré de transparence et de communication en amont et en aval de la chaîne, les développeurs qui travaillent sur le dernier modèle peuvent ne même pas être au courant des corrections apportées.10. Nouveau « Shadow IT »Les entreprises qui utilisent des composants open source dans le cadre de leur développement de logiciels ont mis en place des processus pour contrôler les bibliothèques et s’assurer que les composants sont à jour. Elles s’assurent que les projets sont bien supportés, que les problèmes de sécurité sont traités à temps et que les logiciels sont exploités sous des conditions de licence appropriées.Dans le cas de l’IA générative, cependant, les personnes censées procéder à cette vérification ne savent pas toujours ce qu’elles doivent rechercher. En outre, les projets d’IA générative échappent parfois aux processus de développement logiciel standard. Ils peuvent émaner d’équipes de Data Science ou d’innovation. Les développeurs peuvent télécharger les modèles pour les tester et finir par les utiliser plus largement. Ou bien les utilisateurs eux-mêmes peuvent suivre des tutoriels en ligne et mettre en place leur propre IA générative, en contournant complètement la DSI. Et la dernière évolution de l’IA générative, les agents autonomes, a le potentiel pour conférer un pouvoir énorme à ces systèmes, augmentant les risques associés au Shadow IT.« Si vous voulez expérimenter, créez un conteneur pour le faire de manière sûre pour votre organisation », conseille Kelley Misata, directrice principale de l’open source chez Corelight. Selon elle, cette précaution devrait relever de la responsabilité de l’équipe de gestion des risques au sein de l’entreprise, et de la personne qui s’assure que les développeurs, et l’entreprise dans son ensemble, comprennent qu’il existe un processus encadrant les usages. Autrement dit le DSI. « C’est lui qui est le mieux placé pour instaurer une culture d’entreprise, dit-elle. Tirons parti de l’innovation et de tout ce que l’open source peut offrir, mais allons-y les yeux ouverts. »Le meilleur des deux mondes ?Certaines entreprises recherchent le faible coût, la transparence, la confidentialité et le contrôle de l’open source, mais souhaitent qu’un fournisseur soit présent pour assurer la gouvernance, la viabilité à long terme et l’assistance. Dans le monde traditionnel de l’open source, de nombreux prestataires remplissent ce rôle, comme Red Hat, MariaDB, Docker, Automattic et d’autres.« Ils offrent un niveau de sécurité aux grandes entreprises, explique Priya Iragavarapu, vice-président Data Science et analytique chez AArete. C’est presque un moyen d’atténuer les risques. » Il n’y a pas encore beaucoup de fournisseurs de ce type dans le domaine de l’IA générative. Mais les choses sont en passe de changer, selon elle.