





Le site de partage de code a présenté Agent HQ, une plateforme réunissant les différents agents IA de développement. L’objectif est de rationaliser les flux de travail des entreprises et d’améliorer la gouvernance, la sécurité et la productivité.
Face à la prolifération des agents IA de codage, Github a eu l’idée de réunir la plupart d’entre eux dans une plateforme nommée Agent HQ. Elle propose aux développeurs de gérer et d’orchestrer ces solutions provenant d’OpenAI (Codex), Anthropic (Claude Code), Google (Gemini Code Assist) et d’autres dans l’environnement GitHub. Cette initiative devrait intéresser les entreprises qui cherchent à gouverner, auditer et adapter la programmation basée sur l’IA dans leurs flux de travail DevOps existants plutôt que d’utiliser des outils distincts.
Un chef d’orchestre avec plusieurs fonctionnalités
Dans ce cadre, la plateforme introduit des fonctionnalités centralisées de contrôle des missions, de surveillance de la qualité du code et de gouvernance. Les DSI et les responsables du développement disposent ainsi d’une meilleure visibilité sur la manière dont l’IA contribue à la création, à la révision et au déploiement du code au sein de leur entreprise. « Agent HQ s’étend à VS Code avec d’autres façons de planifier et de personnaliser le comportement des agents », souligne GitHub dans un blog. Il ajoute, « la plateforme s’appuie sur des fonctionnalités dédiées pour l’entreprise comme un plan de contrôle dédié pour régir l’accès à l’IA et comportement des agents et un tableau de bord de métriques pour comprendre l’impact de l’IA sur le travail de développement ».
Selon GitHub, la véritable « force » d’Agent HQ provient du contrôle de mission, qui fournit une interface cohérente entre GitHub, VS Code, les terminaux mobiles et l’interface en ligne de commande (CLI). Ainsi, les utilisateurs peuvent diriger, surveiller et gérer toutes les tâches pilotées par l’IA. Les développeurs peuvent également créer des agents personnalisés dans VS Code à l’aide de fichiers de configuration qui définissent des règles et des normes de codage spécifiques au projet, ce qui offre aux entreprises de contrôler plus précisément le fonctionnement de l’IA dans leurs flux de travail. La portée de la plateforme est étendue grâce à des intégrations avec des outils tels que Slack, Jira, Microsoft Teams et Azure Boards, faisant de GitHub une plaque tournante pour la collaboration basée sur l’IA entre les équipes logicielles d’entreprise.
Consolider un marché en effervescence
Selon les analystes, la dernière initiative de GitHub positionne l’entreprise comme une couche d’orchestration essentielle pour les outils de développement de prochaine génération basés sur l’IA. Plutôt que d’ajouter un autre agent de codage autonome, GitHub tente de les unifier sous un modèle commun de gouvernance et de flux de travail. Selon IDC, les développeurs ne passent qu’environ 16 % de leur temps à l’écriture de nouveau code, le reste du temps étant consacré à des tâches opérationnelles, d’arrière-plan ou de maintenance. Les outils alimentés par l’IA générative et agentique sont considérés comme un levier majeur pour améliorer la productivité en automatisant les tâches routinières et en laissant les développeurs se concentrer sur des tâches à plus forte valeur ajoutée. « L’arrivée d’un nombre d’acteurs toujours plus grand dans le domaine de l’IA rend le travail des développeurs toujours plus difficile, les obligeant à passer sans cesse d’un outil ou d’un agent à un autre », a expliqué Sharath Srinivasamurthy, vice-président associé de la recherche chez IDC. « La plupart des entreprises disposent de plusieurs plateformes de développement (et d’agents), ce qui leur complique la vie. À cet égard, Agent HQ servira de source unique pour tous les outils de codage d’IA agentique. »
La consolidation des agents au sein de GitHub offre également plus de flexibilité aux entreprises, car elles peuvent combiner et associer des agents en fonction de la spécialisation des tâches, des performances ou des coûts, créant ainsi un écosystème plus ouvert et plus adaptable. Une telle interopérabilité pourrait affaiblir les modèles traditionnels de verrouillage vis-à-vis des fournisseurs et déplacer le marché vers des plateformes qui privilégient l’orchestration plutôt que l’exclusivité. « Cette architecture préserve les primitives de base de GitHub (par exemple, Git, les requêtes pull, CI/CD) tout en permettant à divers agents de collaborer de manière transparente dans le cadre d’un modèle de gouvernance commun », a fait remarquer Biswajeet Mahapatra, analyste principal chez Forrester. « En prenant en charge l’interopérabilité multi-agents et en évitant les silos propriétaires, Agent HQ réduit la dépendance à l’égard d’un seul fournisseur. » D’autres ont fait remarquer que l’écosystème plus large de l’IA s’oriente résolument vers la création de frameworks permettant aux agents d’interopérer, ce qui pourrait entraîner une fragmentation alors que les entreprises évaluent le framework à adopter. « Agent HQ de GitHub pourrait très bien résoudre ce problème pour les DevOps, du fait de sa capacité à gérer un parc complexe multi-agents avec un cadre de gouvernance et de politiques solide, doté d’un tableau de bord d’audit et de mesures », a fait valoir Neil Shah, vice-président de la recherche chez Counterpoint Research. « Cela pourrait transformer les pratiques DevOps, depuis la planification automatisée jusqu’à l’évaluation du code généré par l’IA, en passant par les pipelines CI/CD et les garde-fous de sécurité. »
Répondre aux besoins de gouvernance et de conformité
Agent HQ arrive à un moment où les DSI sont confrontés à des défis de gouvernance et de conformité croissants, les agents d’IA étant désormais profondément intégrés dans les workflows des logiciels d’entreprise. L’adoption rapide de l’IA générative et agentique a élargi les capacités, mais elle a également introduit d’autres niveaux de complexité en matière de surveillance et de sécurité. M. Srinivasamurthy a fait remarquer que si un grand nombre d’entreprises investissent massivement dans l’IA, rares sont celles qui ont la maturité nécessaire pour gérer et gouverner efficacement ces systèmes à grande échelle. « Seules 8 % environ des entreprises sont prêtes à gouverner l’IA agentique à grande échelle », a-t-il souligné. « À mesure que les agents d’IA se multiplient, les DSI pourraient être confrontés à des défis similaires aux problèmes de gouvernance rencontrés par le passé avec le SaaS, notamment des interfaces fragmentées, des comportements incohérents et des autorisations qui se chevauchent », a pointé M. Mahapatra. « Les systèmes d’IA agentique ont également tendance à manquer de traçabilité claire pour les décisions et les actions, ce qui rend la conformité et la responsabilité plus complexes. »
L’autonomie croissante de ces agents introduit des risques supplémentaires. Sur ce point, le plan de contrôle centralisé de GitHub, qui comprend la gestion des identités, la journalisation des audits et l’application des politiques, peut aider les DSI à mettre en place des centres de gouvernance unifiés pour gérer les agents d’IA dans toutes les équipes et tous les projets. « Les plateformes comme GitHub intègrent également des workflows agentiques avec des capacités de sécurité et de conformité de niveau entreprise, ce qui permet aux entreprises de se conformer plus facilement à des normes comme l’AI Risk Management Framework du NIST et l’EU AI Act européen », a ajouté M. Mahapatra.

En complément des puces réseaux Tomahawk Ultra et 6, Broadcom lance Jericho4 pour offrir des interconnexions évolutives, sécurisées et sans perte pour les infrastructures IA distribuées.
Dans la gamme des puces réseaux pour datacenter, Broadcom est devenu une référence en ciblant les charges de travail HPC et IA. Le fournisseur vient de dévoiler la puce de commutation Ethernet Fabric Jericho4 capable de connecter plus d’un million de XPU (unités de traitement comprenant les GPU, TPU et autres accélérateurs d’IA). Ce composant vient compléter les Tomahawk 6 et Ultra annoncés en juin dernier pour des interconnexions à grande échelle. Gravé en 3 nm, la puce comprend plusieurs…
Il vous reste 91% de l’article à lireVous devez posséder un compte pour poursuivre la lecture
Vous avez déjà un compte?
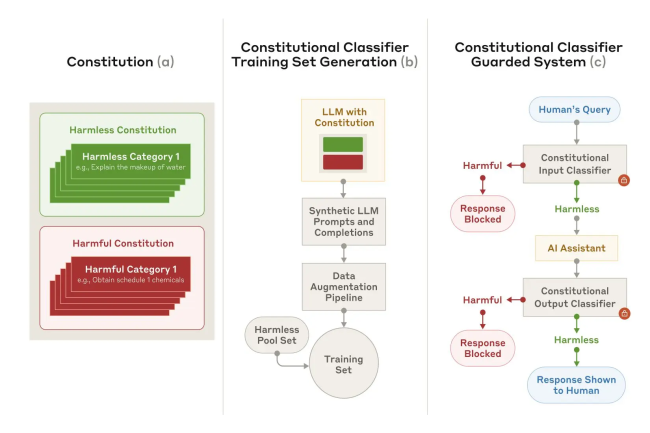
Les modèles d’IA sont de plus en plus la cible de techniques pour leur faire dire de mauvaises réponses. Pour répondre à ce problème, Anthropic lance un framework capable de filtrer les contournements des garde-fous.
La mise en place de garde-fous dans les modèles d’IA n’est pas la réponse parfaite pour éviter de générer du mauvais contenu. Anthropic vient de s’attaquer à ce problème face à la multiplication des techniques pour contourner ces barrières. Ces méthodes aussi appelées jailbreak, « exploitent le LLM en l’inondant d’invites excessivement longues, tandis que d’autres manipulent le style d’entrée, par exemple en utilisant des majuscules inhabituelles », souligne la…
Il vous reste 90% de l’article à lireVous devez posséder un compte pour poursuivre la lecture
Vous avez déjà un compte?
Les modèles d’IA sont de plus en plus la cible de techniques pour leur faire dire de mauvaises réponses. Pour répondre à ce problème, Anthropic lance un framework capable de filtrer les contournements des garde-fous.
La mise en place de garde-fous dans les modèles d’IA n’est pas la réponse parfaite pour éviter de générer du mauvais contenu. Anthropic vient de s’attaquer à ce problème face à la multiplication des techniques pour contourner ces barrières. Ces méthodes aussi appelées jailbreak, « exploitent le LLM en l’inondant d’invites excessivement longues, tandis que d’autres manipulent le style d’entrée, par exemple en utilisant des majuscules inhabituelles », souligne la…
Il vous reste 90% de l’article à lireVous devez posséder un compte pour poursuivre la lecture
Vous avez déjà un compte?

L’incident dans le service de communication interne de Disney, lié à une cyberattaque, souligne la nécessité de renforcer la sécurité des outils de collaboration sur le lieu de travail.
Selon un article du Wall Street Journal (https://www.wsj.com/business/media/internal-disney-communications-leaked-online-after-hack-b57baaeb), les communications internes de Walt Disney sur Slack ont fait l’objet d’une fuite en ligne, exposant des informations sensibles sur les campagnes publicitaires, la technologie des studios et les entretiens des candidats. Le groupe de pirates informatiques NullBulge a revendiqué la responsabilité de l’attaque, déclarant, dans un billet de blog, qu’il avait publié plus d’un téraoctet de données provenant des canaux Slack de Disney, dont du code informatique et des informations sur des projets confidentiels. « Les données divulguées remontent au moins à 2019 et révèlent des échanges sur la gestion du site web de l’entreprise Disney, le développement de logiciels et l’évaluation des candidats à l’emploi », a indiqué le WSJ.
Spéculations sur la méthode
Les experts en cybersécurité ont souligné que, lors d’incidents récents, les pirates avaient pénétré dans les comptes Slack en exploitant des clés API volées ou fuitées. « Les développeurs intègrent souvent Slack dans leurs outils d’automatisation et, ce faisant, laissent parfois échapper accidentellement ces clés sur des sites de partage de code comme GitHub ou des plateformes d’API comme Postman », a déclaré Rahul Sasi, CEO de CloudSEK. « Par exemple, dans la fuite de Disney, les pirates ont pu avoir accès à des salons de discussion publics parce que, par défaut, les clés d’API de Slack ont généralement accès aux salons publics de Slack ».
D’autres ont ajouté que, même s’il était trop tôt pour expliquer pourquoi une violation aussi massive avait pu se produire, il y a peu de chance que des facteurs courants comme la faiblesse des mots de passe, le phishing et l’ingénierie sociale aient pu compromettre de multiples canaux Slack. « La cause la plus probable pourrait être une mauvaise configuration de la sécurité ou des faiblesses dans les diverses intégrations de tiers permises par Slack pour étendre les fonctionnalités », a avancé Chandrasekhar Bilugu, directeur technique de SureShield. « Quelle que soit la raison, les attaquants semblent avoir exploité la grande quantité de données stockées indéfiniment par la politique de stockage et de conservation des données de Slack. »
Les stratégies d’atténuation en question
L’incident met en évidence la nécessité de renforcer la sécurité des outils de collaboration sur le lieu de travail et d’améliorer les technologies de surveillance et de détection des menaces afin de prévenir les violations de données de grande ampleur. « Les entreprises peuvent, avec des outils d’analyse du comportement, établir des comportements de référence sur les utilisateurs et les systèmes », a rappelé M. Bilugu. « Grâce à une surveillance continue, les écarts par rapport aux activités normales peuvent être signalés et permettre de détecter d’éventuelles exfiltrations de données et l’accès non autorisé à des informations sensibles. Les entreprises peuvent s’appuyer sur des solutions de protection contre la perte de données (Data Loss Prevention, DLP) pour empêcher le transfert non autorisé de données sensibles en dehors du réseau de l’entreprise ».
Ces solutions utilisent l’inspection du contenu et l’analyse contextuelle pour identifier, surveiller et protéger les données sensibles, y compris le chiffrement et l’application de politiques. « Avec l’adoption croissante des environnements cloud, les entreprises devraient envisager des solutions avancées de surveillance de la sécurité dans le cloud qui offrent une visibilité sur l’infrastructure, les applications et les données basées sur le cloud », a préconisé M. Bilugu. « Ces outils offrent une surveillance en temps réel et une détection des menaces adaptées aux environnements cloud et peuvent aider à identifier les violations de données potentielles et l’exfiltration dans les systèmes basés dans le cloud. »
Dans cet accord sur le règlement d’un recours collectif sur les données d’utilisateurs suivis en mode « Incognito » évalué à plus de 5 milliards de dollars, Google s’engage également à améliorer ses politiques de divulgation.
Google a accepté de détruire des milliards d’enregistrements de données, réglant ainsi un recours collectif qui accusait la firme de Mountain View de suivre clandestinement les utilisateurs qui croyaient naviguer en mode privé. Les plaignants avaient évalué le règlement à plus de 5 milliards de dollars, mais selon les termes de l’accord, Google ne versera aucun dédommagement. Les utilisateurs peuvent cependant demander individuellement une indemnisation à l’entreprise. Déposée en 2020, la plainte affirmait que Google collectait des données sur les utilisateurs de son navigateur web Chrome même lorsqu’ils activaient la fonction « Incognito », censée empêcher ce genre de suivi. Malgré l’option de navigation privée, les outils de Google sur les sites web, y compris ses technologies publicitaires, continuaient à collecter des données sur les utilisateurs.
Dans l’accord sur le règlement conclu en décembre, Google s’engage également à améliorer ses politiques de divulgation. Avec ce règlement, l’entreprise accepte de reformuler ses déclarations pour informer les utilisateurs que « Google » recueille des données de navigation privées, notamment en divulguant explicitement ce fait dans ses politiques de confidentialité et sur l’écran d’accueil « Incognito » qui apparaît automatiquement au début de chaque session Incognito », indique un document déposé dans le district nord de la Californie. « Les plaignants ont obtenu un règlement par lequel Google a déjà commencé à mettre en œuvre ces changements, sans attendre l’approbation finale du tribunal ».
En outre, au cours des cinq prochaines années, Google permettra aux utilisateurs en mode incognito de bloquer les cookies de tiers, ce qui constitue une avancée significative en matière de protection de la vie privée des utilisateurs. « Le règlement de l’affaire Google Chrome s’inscrit dans une tendance plus large de plaintes déposées par les consommateurs concernant l’utilisation de leurs données d’une manière inattendue », a déclaré Stephanie Liu, analyste principale chez Forrester. Le principal motif de cette action en justice était lié au fait que Google affirmait que le mode Incognito permettait « de naviguer en toute confidentialité » (Google a reformulé sa présentation en réponse à la plainte). Les utilisateurs ont fait valoir qu’ils ne s’attendaient pas à ce que Google recueille des volumes de données sur ces sessions de navigation prétendument privées.
La protection de la vie privée au cœur de l’actualité
Les préoccupations relatives à la protection de la vie privée en ligne sont de plus en plus importantes, et les risques sont considérables alors que l’IA est de plus en plus intégrée dans les plateformes technologiques. Les experts mettent en garde contre le fait que les collecteurs de données et les courtiers qui échangent des informations sur les utilisateurs établissent des profils personnels exhaustifs. En cas de faille de sécurité, ces données sensibles pourraient être échangées sur le dark web, ce qui créerait un risque sérieux d’usurpation d’identité. L’an dernier, un rapport du ministère américain de la Sécurité intérieure, l’US Department of Homeland Security, a révélé que plusieurs agences gouvernementales américaines s’étaient livrées à une utilisation non autorisée des données de localisation des smartphones, en violation des normes de protection de la vie privée.
Ces agences ont acquis des données de localisation et des identifiants publicitaires (AdID) par le biais de transactions avec des courtiers en données qui ont compilé ces informations dans de nombreuses applications. « De même, les plaintes, les actions en justice et les mesures réglementaires se sont multipliées à l’encontre des entreprises qui collectent ou partagent les données de leurs clients de manière fortuite », a indiqué Mme Liu. « L’augmentation du nombre de plaintes et de recours collectifs axés sur la protection de la vie privée montre que les consommateurs sont de plus en plus conscients de l’importance de la protection de la vie privée et qu’ils agissent en conséquence ». Selon l’analyste de Forrester, la transparence est aujourd’hui essentielle. Les entreprises doivent expliquer comment les données sont partagées et utilisées. « Et pour les entreprises qui envisagent d’élargir discrètement leurs politiques de confidentialité ou leurs conditions de service, la Federal Trade Commission (FTC) a déjà averti que cette pratique pourrait être déloyale ou trompeuse », a rappelé Mme Liu. « Ces décisions doivent tenir compte du client, savoir s’il sera d’accord avec la façon dont nous utilisons ou partageons ses données. Si la réponse est négative, il faudra retourner à la case départ ».
Une année parsemée de procès
Selon Bloomberg, sur le plan juridique, l’année 2024 sera difficile pour Google. Un procès important devant un jury est prévu en septembre, où Google devra répondre des allégations du Ministère américain de la Justice et d’un groupe de procureurs généraux d’État qui accusent Google d’avoir enfreint les lois antitrust en monopolisant la publicité numérique. De plus, dans un autre procès prévu en mars 2025, le Texas et plusieurs autres États accusent le géant technologique de pratiques déloyales en matière de technologie publicitaire. Enfin, un procès fédéral antitrust, portant sur le monopole illégal de Google sur le marché de la recherche en ligne, devrait s’achever en mai avec les plaidoiries finales face à un juge de Washington.

Google a apporté plusieurs changements dans ses services en Europe. Résultats des recherches, consentement pour le partage de données et API pour la portabilité des données, sont au programme. Un moyen de préparer l’entrée en vigueur du digital market act (DMA).
En mars prochain, l’Union européenne va réguler un peu plus les grands acteurs de l’IT, dont Google. Ce dernier vient d’annoncer plusieurs évolutions de ses services en Europe pour se conformer au digital market act (DMA). Par exemple, sur les résultats de recherche, la firme va donner la priorité aux comparateurs. Un changement important, car la société a fait l’objet en 2017 d’une amende de 2,42 milliards d’euros pour avoir donné la priorité à son propre service de comparaison de prix et donc d’avoir abusé de sa position dominante.
Dans les prochaines semaines, « nous allons introduire des espaces dédiés comprenant des liens vers des comparateurs et des raccourcis de requête en haut de la page de recherche pour aider les gens à affiner leur recherche » souligne Google dans un blog. Il ajoute, « pour des catégories comme les hôtels, nous allons aussi commencer à tester un espace dédié aux sites de comparaison et aux fournisseurs directs afin d’afficher des résultats individuels plus détaillés, notamment des photos, des classements par étoiles, etc ». Dans le cadre de ces mises à jour, Google supprimera également certains éléments de sa page de recherche, et en particulier la fonction Google Flights.
Une bannière de consentement en plus et une API de portabilité des données
Parmi les autres changements, Google prévoit d’ajouter des bannières de consentement dans plusieurs services pour personnaliser le contenu et les publicités. « Au cours des prochaines semaines, nous présenterons aux utilisateurs européens une bannière de consentement supplémentaire pour leur demander si certains services peuvent continuer à partager des données à ces fins », peut-on lire dans le blog.
Toujours sur les données, une API nommée Data Portability va être proposée auprès des développeurs « pour répondre aux nouvelles exigences concernant le transfert de vos données vers une application ou un service tiers ». Enfin, sur les terminaux Android, les utilisateurs auront la possibilité via une page dédiée (choice screen) de sélectionner le navigateur et le moteur de recherche de leur choix.