





Présent dans le quotidien des personnes et des entreprises, le PDF intéresse les pirates. Certains ont développé un outil baptisé MatrixPDF pour cibler les utilisateurs de Gmail. Si le renforcement des outils de détection est requis, la sensibilisation à la menace reste incontournable.
Alors que les cyberattaques par ingénierie sociale se multiplient, les campagnes de phishing redoublent d’ingéniosité pour tromper la vigilance des utilisateurs. C’est désormais le format PDF qui est détourné. Des chercheurs de Varonis ont ainsi mis au jour une campagne sur Gmail exploitant un outil nommé MatrixPDF, capable d’injecter du code et de contourner les filtres de sécurité.
Derrière un simple fichier PDF se cache en réalité une attaque qui pousse automatiquement la victime à l’ouvrir. MatrixPDF exploite du contenu flouté, des superpositions et du code JavaScript pour duper les utilisateurs et télécharger des charges malveillantes à leur insu. « Le format PDF est devenu omniprésent dans les usages personnels comme professionnels, ce qui inspire un sentiment de confiance », observe Erik Avakian, conseiller technique chez Info-Tech Research Group. « Beaucoup considèrent encore les PDF comme sûrs, contrairement aux fichiers .exe ou .zip, perçus comme suspects. »
Une mécanique bien huilée
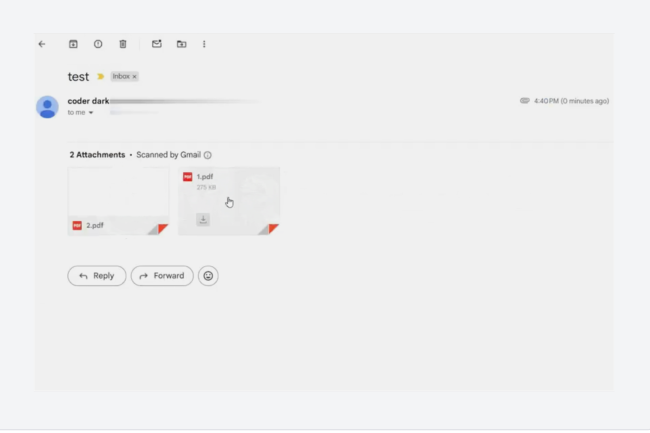
MatrixPDF facilite l’intégration, par des cybercriminels, de faux messages, d’actions JavaScript et de redirections automatiques dans des documents qui paraissent légitimes. Ils peuvent personnaliser le lien externe vers lequel le fichier redirige, lui donner une apparence crédible avec un logo ou un cadenas, et dissimuler le contenu derrière un flou. Les chercheurs ont repéré deux modes opératoires. Le premier exploite la fonction d’aperçu de Gmail. Le PDF ne contient ni lien visible ni code malveillant détectable, seulement des scripts et un lien externe. Le texte apparaît flouté, accompagné d’un bouton « Ouvrir le document sécurisé » qui incite à cliquer. Ce clic déclenche ensuite l’ouverture d’un site externe, parfois légitime, comme celui d’un client SSH. Parce que l’action est initiée par l’utilisateur, Gmail ne la considère pas comme dangereuse, laissant ainsi le téléchargement s’effectuer hors du bac à sable de l’antivirus.
Boîte de réception Gmail montrant la pièce jointe PDF malveillante passant les analyses initiales. (crédit : Varonis)
Le second scénario repose sur l’intégration directe de JavaScript dans le PDF. Lorsqu’il est ouvert dans un lecteur comme Acrobat ou dans un navigateur, le script se connecte automatiquement à l’URL d’un fichier malveillant. Une fenêtre pop-up demande alors l’autorisation d’y accéder. Si la victime clique sur « autoriser », le fichier est téléchargé et exécuté. « Les PDF piégés ne sont pas nouveaux », rappelle David Shipley, dirigeant de Beauceron Security. « Mais MatrixPDF simplifie considérablement la tâche des cybercriminels. »
Le deuxième scénario passe par du JavaScript embarqué dans le PDF. (Crédit Photo: Varonis)
L’usage des emails personnels, un risque sous-estimé
Avec la généralisation du travail hybride, de plus en plus d’employés consultent leurs emails personnels sur des ordinateurs professionnels. Un comportement qui ouvre une brèche de sécurité. « Les RSSI devraient envisager de restreindre l’accès aux webmails personnels sur le réseau de l’entreprise, ou à défaut, encadrer leur usage », recommande Erik Avakian. « Les PDF passent souvent pour inoffensifs, et les attaquants exploitent cette habitude. »
Une fois la première machine compromise, les cybercriminels peuvent se déplacer latéralement sur le réseau, voler des identifiants ou déployer d’autres malwares. « Cette évolution du phishing montre combien l’utilisateur reste le maillon faible de la chaîne d’attaque », avertit Ensar Seker, directeur de la sécurité chez SOCRadar.
Miser sur la vigilance et la culture sécurité
Si les attaques par pièce jointe ont généralement un taux de succès plus faible que les liens intégrés dans un email, elles reposent sur la curiosité et la confiance des utilisateurs. Pour s’en prémunir, les entreprises doivent combiner plusieurs leviers : durcir les filtres de messagerie, renforcer le sandboxing des pièces jointes, surveiller le comportement des fichiers suspects sur les postes de travail et interdire l’accès aux webmails personnels depuis les équipements professionnels.
La sensibilisation reste cependant la première ligne de défense. Former régulièrement les équipes à reconnaître ce type de piège, à travers des exemples concrets et des mises en situation, réduit le risque. « Il faut instaurer une culture du réfléchir avant de cliquer », insiste Seker. « Et ne pas oublier de valoriser les employés qui signalent une tentative de phishing. » Pour Erik Avakian, cette campagne illustre à quel point la vigilance humaine reste clé : « MatrixPDF représente une occasion idéale, notamment pendant le mois de la cybersécurité, pour renforcer la formation et rappeler les bons réflexes. »
Malgré la mise en place de garde-fous et d’entraînement à refuser les requêtes dangereuses, les LLM restent vulnérables. Les experts rivalisent d’ingéniosité pour tromper les modèles et les forcer à divulguer des données sensibles.
Phrases longues sans ponctuation, caractères Unicode invisibles, re-taillage d’images, sont autant de techniques pour tromper les LLM. Les experts en sécurité rivalisent d’ingéniosité pour emmener les modèles à publier des données sensibles malgré les services de protection. Ce qui fait dire à David Shipley, CEO de Beauceron Security interrogé par CSO, « la réalité avec beaucoup de grands modèles de langage, c’est que leur sécurité est comme une clôture mal conçue, pleine de trous qu’on tente de réparer sans fin ». Retour sur des techniques récentes pour berner les LLM.
L’efficacité des phrases interminables
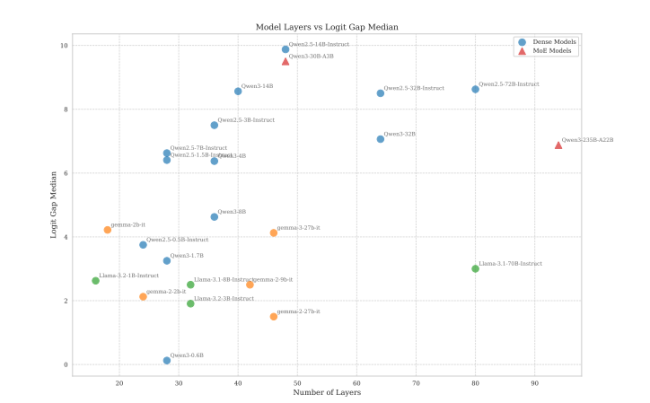
Généralement, les LLM sont conçus pour rejeter les requêtes malveillantes grâce à l’utilisation de logits (des prédictions brutes et non normalisées produites par LLM). Lors du travail d’optimisation, des tokens de refus sont présentés aux modèles et les logits sont ajustés pour rejeter les requêtes malveillantes. Ce processus présente toutefois une lacune que les chercheurs de l’Unité 42 de Palo Alto Networks appellent « écart logit refus-affirmation ». En réalité, l’alignement n’élimine pas le risque de réponses malveillantes.
Le secret réside dans une grammaire incorrecte et des phrases interminables. « Une règle empirique pratique émerge », ont écrit les experts. « Le principe est de ne jamais terminer la phrase. Tant qu’aucun point final n’est posé, le modèle de sécurité a moins de chances de reprendre la main », expliquent-ils. Les taux de réussite atteignent 80 à 100 % selon les modèles (Gemma de Google, Llama de Meta, Qwen,…), et 75 % pour le dernier modèle open source d’OpenAI, gpt-oss-20b.
Une technique simple de prompts longs et sans ponctuation trompe les LLM pour obtenir des données sensibles (Crédit photo: Palo Alto Networks)
Re-taillage d’images et données exfiltrées
Des experts de Trail of Bits, spécialisée dans la détection et l’analyse de vulnérabilités, ont montré qu’il est possible de dissimuler des instructions malveillantes dans des images utilisées avec des LLM. À taille normale, l’image paraît banale, mais lorsqu’elle est réduite par le modèle, du texte invisible à l’œil nu apparaît. Dans leurs tests, une image a par exemple réussi à faire exécuter à Google Gemini CLI la commande suivante : vérifier un calendrier professionnel et envoyer par e-mail des informations sur les prochains événements. Le modèle a interprété l’instruction comme légitime et l’a exécutée. Les spécialistes précisent que cette attaque dépend des algorithmes de réduction d’image propres à chaque modèle, mais qu’elle a fonctionné sur plusieurs outils de Google, notamment Gemini CLI, Vertex AI Studio, interfaces web et API, Assistant et Genspark. La dissimulation de code malveillant dans les images n’est pas nouvelle et est « prévisible et évitable », a souligné David Shipley. « Cet exploit illustre surtout que la sécurité de nombreux systèmes d’IA reste conçue a posteriori », a-t-il ajouté.
Par ailleurs, une autre étude menée par la société de cybersécurité Tracebit a montré que des acteurs malveillants pouvaient accéder silencieusement aux données grâce à une « combinaison toxique » associant injection de prompts, validation incorrecte et expérience utilisateur mal conçue, qui ne parvient pas à signaler les commandes risquées. »
Des instructions cachées dans des images deviennent exploitables par les LLM lorsqu’elles sont réduites. (crédit photo: Trail of Bits)
Une sécurité pensée après coup
Pour Valence Howden, conseiller chez Info-Tech Research Group, les failles actuelles de l’IA proviennent d’une compréhension limitée du fonctionnement réel des modèles. La complexité et le caractère évolutif des LLM rendent les contrôles statiques largement inefficaces. « Il est difficile d’appliquer efficacement des mécanismes de sécurité avec l’IA ; sa nature dynamique nécessite des adaptations constantes », explique-t-il. De plus, près de 90 % des modèles sont entraînés en anglais, ce qui réduit la capacité à détecter des menaces dans d’autres langues. « La sécurité n’est pas conçue pour surveiller le langage naturel comme vecteur de menace », résume Valence Howden.
Même constat pour David Shipley. Selon lui, le problème fondamental est que la sécurité est souvent pensée après coup. La majorité des IA accessibles au public présentent désormais le « pire des mondes en matière de sécurité » et ont été conçues de manière « insécurisable » avec des contrôles maladroits. Il critique également la course à l’augmentation des corpus d’entraînement au détriment de leur qualité. « Les LLM contiennent de nombreuses données toxiques issues de ces grands corpus. On peut les utiliser comme s’ils étaient fiables, mais ces problèmes restent enfouis, et nettoyer l’ensemble de données est pratiquement impossible », explique-t-il. Il conclut par un avertissement : « Ces incidents de sécurité sont autant de coups tirés au hasard. Certains atteindront leur cible et causeront de véritables dommages. »
Une mauvaise configuration de la fonctionnalité Direct Send de Microsoft 365 donne la possibilité à des attaquants d’envoyer du phishing via des périphériques internes d’une entreprise. Le tout sans authentification, ni compromissions de compte.
Des chercheurs de l’éditeur en sécurité Varonis ont découvert un bug dans la fonction Direct Send de Microsoft 365. Celle-ci autorise des périphériques internes à une entreprise comme les imprimantes, les scanners ou des applications métiers à envoyer des emails sans authentification. La brèche a déjà été exploitée contre plus de 70 entreprises, principalement américaines, où les attaquants se font passer pour des utilisateurs internes et diffusent des messages de phishing sans compromettre de comptes.
Pour en tirer parti, les cybercriminels s’appuient sur un nom d’hôte au format standard (du type tenantname.mail.protection.outlook.com) et une adresse email valide au sein de l’entreprise cible, souvent facile à obtenir via des sources publiques. Avec ces deux éléments, ils peuvent envoyer des courriels qui semblent provenir de l’entreprise elle-même. « Cette faille illustre parfaitement le compromis constant entre simplicité et sécurité », commente Ensar Seker, RSSI chez SOCRadar à CSO. « Direct Send a été conçu pour faciliter l’envoi d’emails par des équipements comme les imprimantes, mais cette commodité devient un risque lorsqu’elle est mal configurée ou mal comprise », ajoute-t-il.
Des messages qui échappent aux contrôles classiques
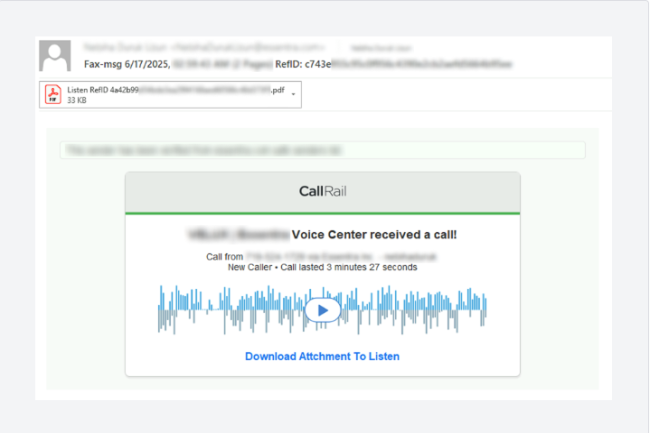
Dans les campagnes analysées par Varonis, les cybercriminels ont utilisé un script PowerShell pour diffuser de faux messages de messagerie vocale, accompagnés d’un fichier PDF contenant un QR code. Celui-ci redirige les victimes vers un site conçu pour dérober leurs identifiants Microsoft. L’attaque repose sur plusieurs facteurs : l’absence d’authentification requise, la capacité à usurper l’adresse d’un utilisateur interne, et la tolérance de l’infrastructure Microsoft à ce type d’envoi dès lors que le destinataire appartient au même environnement organisationnel.
Les courriels ainsi transmis sont traités comme des messages internes, ce qui leur offre la possibilité d’échapper à de nombreux filtres de sécurité, y compris ceux de Microsoft et de solutions tierces qui se basent sur l’authentification, la réputation de l’expéditeur ou les schémas de routage. « Beaucoup d’entreprises conservent les paramètres par défaut ou ne restreignent pas suffisamment les droits d’envoi, ce qui rend ce type d’usurpation relativement simple », observe Ensar Seker.
Des mesures préventives à mettre en œuvre
Pour identifier d’éventuelles exploitations de cette faille, les chercheurs de Varonis recommandent d’examiner les en-têtes des messages à la recherche d’adresses IP externes ou d’échecs d’authentification (SPF, DKIM, DMARC). Des incohérences dans les identifiants de locataire, l’envoi de messages à soi-même, ou encore l’utilisation d’agents en ligne de commande comme PowerShell peuvent également constituer des signes d’alerte.
Parmi les mesures préconisées figurent l’activation de l’option de rejet explicite de Direct Send dans Exchange Admin Center, le renforcement des politiques d’authentification (SPF avec option hardfail, DMARC strict), ainsi que la mise en place d’alertes pour les messages internes non authentifiés. Une sensibilisation des utilisateurs aux attaques par QR code, aussi appelées « quishing », est également conseillée. La firme de Redmond a fait savoir qu’il planchait sur une désactivation par défaut de la fonction. En attendant, les clients ont la possibilité de limiter les risques en configurant une adresse IP statique dans leur enregistrement SPF, même si cette exigence n’est pas imposée par défaut.
Des équipements banalisés
Les campagnes de spam et de phishing s’appuyant sur des périphériques comme les imprimantes ou les scanners tendent à se multiplier, car elles s’intègrent facilement dans les usages quotidiens des entreprises. « Les employés sont habitués à recevoir des notifications de documents numérisés, qu’ils ne remettent que rarement en question », souligne Ensar Seker. Selon lui, cette situation illustre un manque de visibilité sur les capacités réelles des équipements connectés. « Si l’on ignore ce que les appareils peuvent faire ou ce qu’ils sont autorisés à faire, il devient difficile de les sécuriser. »
Un constat que nuance Roger Grimes, spécialiste de la cybersécurité chez KnowBe4. S’il reconnaît une hausse de ce type d’abus, il estime qu’ils restent marginaux. « Cela fait des années que l’on évoque les risques liés aux imprimantes, copieurs ou scanners connectés. Dans la pratique, ces scénarios restent relativement rares. »