






Le spécialiste de l’accès réseau a annoncé des débits de 300 Gbt/s pour sa plateforme SASE. Cloudbrink en profite aussi pour étendre son empreinte internationale avec des partenariats en Amérique latine, en Corée et en Afrique.
Quelle que soit la technologie de réseau, le débit est toujours un élément à prendre en compte. C’est le cas en particulier pour les technologies de sécurité, où ce sujet a longtemps été quelque peu contraint et limité par les coûts de l’inspection et du chiffrement. Pour répondre à cette problématique, Cloudbrink affirme avoir franchi une étape en atteignant un débit de 300 Gbps dans les centres de données pour sa technologie SASE.
Fondée en 2019 avec un financement de 25 millions de dollars à ce jour, Cloudbrink a conçu une plateforme définie par logiciel qui intègre la fonctionnalité VPN traditionnelle, l’accès réseau Zero Trust (ZTNA) et des services de passerelle web sécurisée (SWG) dans une architecture SASE homogène optimisée pour les environnements de travail distribué. Le dirigeant de Cloudbrink, Prakash Mana revendique plusieurs années d’expérience au sein d’entreprises telles que Pulse Secure et Citrix. « Au départ, nous pensions que, pour les entreprises, la mobilité serait la prochaine étape », a-t-il déclaré à Networkworld. Cependant, le CEO s’est rapidement rendu compte qu’en se concentrant sur les terminaux, sa startup passait à côté d’un point essentiel : l’évolution des besoins des travailleurs modernes. La pandémie de COVID-19 a accéléré cette transformation, poussant les entreprises à repenser les architectures réseau traditionnelles presque du jour au lendemain alors que l’ensemble du monde du travail devenait hybride. Ce changement a incité Cloudbrink à développer une plateforme capable d’offrir une expérience productive, sécurisée, ultra-rapide, depuis n’importe quel endroit où travaillaient les employés.
Accélération du trafic SASE
Pour développer sa base technique, Cloudbrink s’est intéressée aux expériences de travail mises en place au bureau par les entreprises, puis elle a étendu ces capacités aux travailleurs distants. La société a identifié trois éléments fondamentaux qui définissent les réseaux d’entreprise : une connectivité haute performance, un contrôle d’accès basé sur les rôles et une sécurité intégrale. Ces éléments de base sont fonctionnellement des enjeux types qui ne différencient pas vraiment à différencier Cloudbrink de sa myriade de concurrents sur le marché des SASE.
C’est donc au niveau technique que Cloudbrink a cherché à se différencier, grâce à une série d’innovations. Il y a d’abord une architecture edge distribuée en découplant le logiciel du matériel. La plateforme peut ainsi fonctionner dans 800 centres de données en tirant parti des clouds publics, des réseaux de télécommunications et de l’infrastructure edge. Selon Cloudbrink, cette approche réduit la latence du réseau de 300 millisecondes à une valeur comprise entre 7 et 20 millisecondes. Cette densité améliore considérablement les performances et la réactivité du TCP. Par ailleurs, la société propose une optimisation du protocole en développant ses propres algorithmes d’optimisation du SD-WAN. Ces algorithmes améliorent considérablement l’efficacité et les performances des connexions Internet public à haut débit. Enfin, Cloudbrink apporte une pile de sécurité intégrée. « Nous avons pu proposer des vitesses sécurisées sur des lignes standards pour notre plateforme en intégrant la sécurité à la pile de réseau elle-même », a indiqué Prakash Mana. Plutôt que de traiter la sécurité comme une surcouche distincte qui dégrade les performances, Cloudbrink a intégré les fonctions de sécurité directement dans la pile réseau.
La solution se compose de trois éléments principaux : un logiciel client pour les terminaux des utilisateurs, un plan de gestion du cloud et des connecteurs optionnels pour le datacenter afin d’accéder aux applications internes. Le client se connecte intelligemment à plusieurs nœuds de périphérie simultanément, ce qui assure la redondance et l’optimisation du routage spécifique à l’application.
Extension de la portée mondiale
Au-delà de ses efforts pour augmenter le débit, Cloudbrink a également étendu son empreinte mondiale. La startup a annoncé une expansion mondiale grâce à des accords de distribution et à l’ouverture d’un bureau au Brésil pour desservir les marchés émergents d’Amérique latine, de Corée du Sud et d’Afrique. L’expansion comprend des partenariats exclusifs avec WITHX en Corée, BAMM Technologies pour la distribution en Amérique latine et OneTic pour les marchés africains. La technologie FAST (Flexible, Autonomous, Smart and Temporary) Edges de l’entreprise, définie par logiciel, permet un déploiement rapide des points de présence en tirant parti de l’infrastructure existante de plusieurs opérateurs de télécommunications et fournisseurs de services cloud.
Vers une connectivité sécurisée et flexible (sans trop d’IA)
Alors que les entreprises continuent d’adopter des modes de travail hybrides, Cloudbrink se positionne comme une solution de dernière génération. L’entreprise prévoit de continuer à développer ses capacités d’accès sécurisé, en mettant particulièrement l’accent sur l’amélioration de la sécurité des connexions Internet publiques. La startup adopte notamment une approche mesurée de l’IA, qu’elle utilise de manière stratégique pour optimiser les connexions sans tomber dans l’exagération marketing. « Nous sommes des personnes et des opérateurs pragmatiques… évidemment, nous utilisons tous les récents algorithmes à notre disposition, mais l’IA générative ne peut pas être une fin en soi », a tempéré M. Mana. « Cela ne sert à rien de mettre cette technologie en avant pour le plaisir. C’est la raison pour laquelle nous essayons de résister à la tentation d’emprunter cette voie facile et de faire croire que l’IA générative est une réponse à tout. »

L’éditeur britannique spécialisé dans la cybersécurité ACDS créé un bureau en France et nomme à sa tête Franck Chevalier en tant que directeur général.
Déjà représenté en France par Franck Chevalier en tant que vice-président du groupe EMEA, l’éditeur britannique ACDS (Advanced Cyber Defence Systems) officialise son implantation en France en créant une entité dédiée et nomme Franck Chevalier à sa tête.Précisons qu’ACDS propose un outil de gestion de la surface d’attaque externe (EASM) qui consiste à découvrir et surveiller les points d’entrée sensibles aux attaques au sein de l’infrastructure IT, puis de les évaluer, les prioriser et les corriger. D’ailleurs, fait inquiétant, le rapport Cybersecurity Challenges in 2024 publié par ACDS montre que la moitié des professionnels de la sécurité pensent qu’il est probable qu’il existe des dispositifs connectés au réseau de leur entreprise dont ils n’ont pas connaissance, ce qui rend les organisations très vulnérables aux menaces.« Cette nomination reflète l’importance stratégique de la France au sein de nos opérations régionales et mondiales. En rapprochant la direction régionale de l’exécution locale, nous souhaitons accélérer la prise de décision, renforcer les synergies et consolider notre engagement envers les clients et les équipes de l’un de nos principaux marchés. Je suis impatient de travailler encore plus étroitement avec nos équipes pour trouver de nouvelles opportunités et soutenir la croissance à long terme de l’activité d’ACDS », déclare Franck Chevalier.Une expansion tous azimuts pour ACDSIl faut savoir que la création de l’entité française fait suite à l’expansion de l’éditeur dans les régions EMEA (Europe, Moyen Orient, Afrique) et APAC (Asie-Pacifique) l’année dernière grâce à des partenariats et des recrutements internes. Elle intervient aussi à un moment où la réglementation européenne s’intensifie, avec la directive NIS2 et la loi sur la résilience opérationnelle numérique (DORA), toutes deux transposées dans la législation en mars 2025.En outre, Franck Chevalier va travailler avec Ed Hume qui a été nommé en 2024 global managing director pour diriger la croissance mondiale de l’organisation. Ed Hume avait rejoint ACDS avec sa grande expérience de l’industrie, ayant occupé le poste de responsable des partenaires et des alliances chez Beyond Now, Sigma Systems et Convergys.
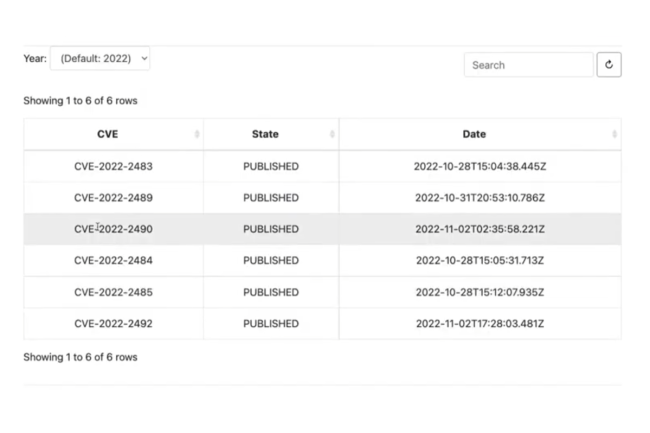
Selon une étude de Verizon, l’exploitation des failles, y compris les attaques sur les équipements de bordure de réseau, a dépassé le phishing.
L’édition 2025 du Data Breach Investigation Report (DBIR) de Verizon est toujours riche en enseignement. Ainsi, le rapport constate que l’implication de tiers dans les failles de sécurité et l’exploitation des vulnérabilités sont devenues ont fortement progressé. Une analyse de 22 000 incidents de sécurité, dont 12 195 violations de données confirmées dans 139 pays, a montré que l’abus d’informations d’identification (22 %) et l’exploitation des vulnérabilités (20 %, contre 14,9 % en 2024)…
Il vous reste 94% de l’article à lireVous devez posséder un compte pour poursuivre la lecture
Vous avez déjà un compte?

Pour renforcer les capacités de sa plateforme application delivery and security platform (ADSP), F5 a annoncé l’acquisition de Fletch, une start-up spécialisée dans l’IA agentique et la gestion des menaces.
Lancée récemment, la plateforme ADSP intègre des fonctionnalités traditionnelles d’équilibrage de charge et de gestion du trafic, associées à des outils de sécurité pour les applications et les API. Selon le fournisseur, cette solution vise à réduire la complexité et à simplifier les opérations, tout en garantissant une protection étendue pour un large éventail d’applications d’entreprise.
Fondée en 2020, Fletch développe des agents capables de collecter des renseignements sur les menaces et de fournir des analyses contextualisées. Leur intégration à la plateforme ADSP doit contribuer à réduire la complexité opérationnelle, tout en apportant des informations plus riches, un renseignement en temps réel et des recommandations de sécurité proactives, a expliqué Kunal Anand, directeur de l’innovation chez F5, dans un billet de blog. Ces agents s’intègrent par ailleurs à l’écosystème Security Copilot de Microsoft. « Les équipes de sécurité sont submergées par les données, les alertes et les journaux. Elles ont besoin d’un contexte exploitable pour gagner en efficacité », a-t-il souligné. Les modalités financières de l’acquisition n’ont pas été divulguées.
Une IA agentique pour alléger la charge des analystes
L’IA agentique, qui se distingue par sa capacité à agir de manière autonome, apporte un soutien précieux aux équipes de sécurité. Elle permet de réduire la fatigue liée aux alertes en hiérarchisant les menaces les plus critiques et en automatisant certaines actions, comme le blocage d’adresses IP malveillantes ou la clôture de tickets bénins. Intégrée à la plateforme ADSP, cette technologie aide les analystes à se concentrer sur les incidents les plus importants.
Grant Wernick, fondateur et CEO de Fletch, explique que cette approche offre plusieurs bénéfices majeurs. Elle améliore l’analyse de sécurité grâce à une corrélation intelligente des journaux, des renseignements sur les menaces et des alertes en temps réel, ce qui permet des évaluations de risques plus précises. Elle contribue également à réduire la fatigue des alertes en aidant les équipes à se focaliser sur les incidents prioritaires, plutôt que d’être submergées par des milliers d’alertes quotidiennes. Enfin, cette plateforme ne se contente pas de signaler les problèmes, elle propose aussi des recommandations proactives et des mesures correctives adaptées.
La vulnérabilité du moteur JavaScript Chrome V8 est considérée comme très grave et a été découverte par le groupe d’analyse des menaces de Google. Elle est actuellement exploitée par des pirates et nécessite une mise à jour dès que possible.
L’équipe de Google Chrome a publié une mise à jour pour corriger une vulnérabilité très grave qui est activement exploitée dans la nature. Le problème a également été atténué par une modification de configuration diffusée jeudi dernier aux utilisateurs de la version stable de Chrome, qui n’a pas nécessité de mise à jour du navigateur. Les exploits de Google Chrome sont des produits de grande valeur sur les marchés noir et gris, dont les prix atteignent des centaines de milliers de dollars. Cela s’explique par le fait qu’il est l’un des navigateurs les plus robustes et qu’il utilise des bacs à sable pour ajouter des obstacles supplémentaires aux attaquants. Pour contourner toutes ces défenses et parvenir à exécuter un code à distance sur un système via Chrome, il faut généralement enchaîner plusieurs failles.
Cette CVE-2025-5419, corrigé lundi dans Chrome 137.0.7151.68/.69 pour Windows et Mac et 137.0.7151.68 pour Linux, est la troisième faille de type zero day corrigée dans Chrome cette année. Les deux autres, CVE-2025-2783 et CVE-2025-4664, ont été corrigées respectivement en mars et en mai. Cela montre que les pirates ont tout intérêt à compromettre les utilisateurs de Chrome, malgré la difficulté. Ce dernier trou de sécurité a été signalé à l’équipe Chrome par des membres du Threat Analysis Group de Google, qui est principalement chargé de défendre l’infrastructure et les utilisateurs de Google contre les attaques bénéficiant de soutiens de niveau étatique. Cela suggère que ce problème a probablement été découvert dans la nature, bien que les détails n’aient pas encore été divulgués. La vulnérabilité est classée comme étant de gravité élevée, ce qui signifie qu’elle ne peut pas conduire à une exécution de code à distance sur le système d’exploitation sous-jacent et qu’elle doit probablement être combinée à une autre faille pour y parvenir.
Une exploitation possible en surfant simplement sur des sites
L’équipe de Chrome a décrit cette faille comme un problème de lecture/écriture de mémoire hors bande dans V8, qui est le moteur JavaScript et WebAssembly de Chrome. Ce moteur open source est également utilisé dans d’autres projets, notamment le moteur d’exécution Node.js et est conçu pour interpréter et exécuter du code JavaScript et WebAssembly. A noter que cette faille peut probablement être déclenchée à distance par des utilisateurs visitant simplement des pages web qui chargent du code malicieusement conçu. « L’accès aux détails des bogues et aux liens peut être restreint jusqu’à ce qu’une majorité d’utilisateurs soit mise à jour avec un correctif », a indiqué Google dans son bulletin. « Nous maintiendrons également des restrictions si le bogue existe dans une bibliothèque tierce dont dépendent d’autres projets, mais qui n’a pas encore été corrigée. »
Outre la CVE-2025-5419, la dernière mise à jour de Chrome corrige également un bogue de mémoire de gravité moyenne de type « use-after-free » dans Blink, le moteur de rendu du navigateur. Celui-ci a été signalé en privé par un chercheur qui a reçu une prime de 1 000 $. Le navigateur Chrome dispose d’un mécanisme de mise à jour automatique, mais les utilisateurs qui ne l’ont pas encore reçue et qui souhaitent déclencher la mise à jour manuellement peuvent accéder au menu Aide > À propos de Google Chrome pour déclencher une vérification de la mise à jour.

Échecs de connexion, problèmes d’IAM, perturbations du plan de contrôle… Tous les services IBM Cloud dont Watson AI et DNS Services étaient inaccessibles pendant des heures ce lundi dans toutes les régions.
IBM Cloud a subi lundi sa deuxième panne majeure en deux semaines, empêchant les utilisateurs du monde entier de se connecter, de gérer les ressources ou d’accéder aux services essentiels. L’incident, qui a duré plusieurs heures, a commencé à 11h05 le 2 juin. Il a perturbé 41 services, notamment IBM Cloud, AI Assistant, DNS Services, Watson AI, Global Search Service, Hyper Protect Crypto Services, les bases de données et le Security and Compliance Center. L’incident a été résolu mardi à 01h10. Selon le rapport d’IBM sur l’état de la situation, les utilisateurs n’ont pas pu se connecter à IBM Cloud via la console, le CLI ou l’API. Pendant cette période, ils n’ont pas pu non plus gérer ou approvisionner les ressources du cloud. De plus, des échecs d’authentification IAM se sont produits, l’accès au portail de support a été perturbé et les chemins de données pour les applications des clients peuvent avoir été affectés.
Big blue a commencé son enquête et pris des mesures d’atténuation préliminaires puis démarré un processus de récupération contrôlé pour restaurer le système. Après avoir terminé ses principales actions de restauration, et les utilisateurs ont pu vérifier l’état de leurs applications. L’événement a été classé de gravité 1 (Sev-1). Les clients ont reçu des courriels sur l’échec de l’authentification IAM, l’impossibilité d’accéder au portail de support, et les impacts potentiels sur les chemins de données des applications des clients. Le fournisseur n’a pas répondu immédiatement à une demande de commentaire.
Un incident similaire quinze jours avant
« Les interruptions de connexion au cloud, même si elles sont de courte durée, retardent l’accès aux applications clés, ralentissent la coordination interne et interfèrent avec les flux automatisés. Les pannes du cloud qui affectent la connexion des utilisateurs ou l’accès à la plateforme ne déclenchent pas toujours un chaos immédiat, mais elles introduisent des frictions qui s’aggravent rapidement », a déclaré Sanchit Vir Gogia, analyste en chef et directeur général de Greyhound Research. Selon M. Gogia, un impact multirégional ne se résume pas à un bogue d’authentification, mais pointe généralement vers un composant back-end partagé, comme une couche de résolution DNS globale, un contrôleur d’orchestration ou un service de télémétrie. « Contrairement aux pannes de calcul ou de stockage le plus souvent localisées, les faiblesses du plan de contrôle se répercutent sur les zones, rendant la panne plus difficile à contenir et plus perturbante pour les équipes qui gèrent des charges de travail distribuées. L’absence de découplage régional dans les fonctions de base de la plateforme reste une préoccupation pour les DSI qui doivent trouver des compromis de conformité, de performance et d’isolation », a poursuivi M. Gogia.
Le 20 mai, soit à peine plus de quinze jours avant, un incident similaire s’était déjà produit. Il avait duré deux heures et dix minutes et avait affecté 14 services, dont IBM Cloud, Client VPN for VPC, Code Engine et Kubernetes Service, entre autres. Au cours de cette panne globale de la plateforme cloud, les utilisateurs ont essuyé plusieurs échecs lorsqu’ils essayaient de se connecter via l’interface utilisateur (UI), l’interface de ligne de commande (CLI) et même l’authentification basée sur la clé API. « Quand les services de connexion ou d’IAM tombent en panne, les charges de travail critiques peuvent s’arrêter, déclenchant des perturbations en cascade à travers les services et les régions », a expliqué Prabhu Ram, vice-président du groupe de recherche sur l’industrie chez CMR.
Une question sur la résilience du cloud à se poser
De telles perturbations récurrentes mettent en évidence des implications plus larges de la stratégie informatique de l’entreprise, ce qui amène souvent les entreprises à se concentrer sur l’amélioration de la résilience de leur cloud au-delà des contrats avec les fournisseurs. « Pour atteindre une véritable résilience, les entreprises doivent s’employer en priorité à mettre en place des protections techniques solides, telles que des stratégies multi-cloud et des architectures géo-distribuées, et opter pour des protections contractuelles solides, y compris des accords de niveau de service (SLA) complets. Même si une seule panne n’entraîne pas nécessairement un changement immédiat, des pannes répétées ou une réponse inadéquate aux incidents peuvent obliger les entreprises à diversifier leurs fournisseurs de services cloud », a ajouté M. Ram.
Selon M. Gogia, aujourd’hui, le renforcement de la résilience va bien au-delà du stockage de secours et des centres de données secondaires. « Les entreprises investissent désormais dans l’observabilité multicouche, les outils d’orchestration multiplateforme et les voies d’accès secondaires qui restent disponibles même en cas d’interruption de la plateforme du fournisseur. Cela peut impliquer l’hébergement de portails d’administration légers en dehors du fournisseur principal, le déploiement d’une télémétrie en miroir dans une région distincte ou l’utilisation d’une gestion DNS indépendante. » Sans être catastrophiques, ces exemples récents de pannes du cloud constituent des tests de résistance utiles pour identifier les points faibles de l’architecture et de la politique.

Les licenciements dans le secteur technologique se poursuivent alors que l’adoption de l’IA et les pressions du marché entraînent un changement majeur vers d’autres compétences et domaines d’action. Pour les professionnels du recrutement, la demande en profils IT ne disparaît pas mais elle devient plus sophistiquée.
Imputés en grande partie à la combinaison d’un ralentissement économique et de l’adoption de l’automatisation via l’intelligence artificielle, les licenciements dans l’IT se sont poursuivis en 2025 aux Etats-Unis. De ce fait, près de quatre Américains sur dix pensent que l’IA générative pourrait diminuer le nombre d’emplois disponibles à mesure qu’elle progresse, selon une étude publiée en octobre par la Réserve fédérale de New York. De son…
Il vous reste 96% de l’article à lireVous devez posséder un compte pour poursuivre la lecture
Vous avez déjà un compte?
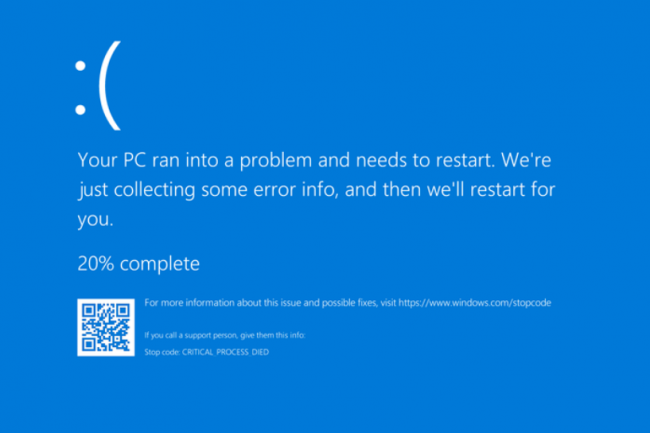
Depuis l’application du dernier patch tuesday de Microsot des utilisateurs rencontrent des difficultés au démarrage de leurs PC, notamment en environnements virtuels. Ils peuvent soufler : le fournisseur a proposé un correctif pour régler le souci.
Microsoft a publié ce week-end des mises à jour hors bande pour corriger le problème de démarrage des ordinateurs Windows 11 après application du Patch Tuesday du mois de mai. La mise à jour défectueuse affecte surtout les PC dans les environnements virtuels exécutant les versions 22H2/23H2 du système d’exploitation. Sur certains de ces systèmes, l’OS ne trouve pas le fichier crucial ACPI.sys au moment de l’installation de la mise à jour de sécurité Windows de mai (KB5058405). L’interface ACPI (advanced configuration and power interface) est un pilote système Windows essentiel qui permet à Windows de gérer les ressources matérielles et les états d’alimentation. En l’absence de ce fichier, Windows ne se charge pas et un message d’erreur portant le code 0xc0000098 s’affiche, indiquant le fichier manquant. Microsoft note que dans certains cas, le code du fichier peut être différent pour la même erreur. « Ce problème a été observé sur quelques terminaux physiques, mais principalement sur des modèles fonctionnant dans des environnements virtuels, y compris les VM Azure, Virtual Desktop et les machines virtuelles sur site hébergées sur Citrix ou Hyper-V », a précisé Microsoft.
Les correctifs – KB5027397 pour les PC fonctionnant avec la version 23H2, et KB5062170 pour les PC fonctionnant avec la version 22H2 – ne sont disponibles que via le catalogue Windows Update. Le fournisseur recommande aux personnes exploitant une infrastructure de bureau virtuel qui, pour une raison quelconque, n’ont pas encore installé les correctifs de sécurité du patch tuesday de mai 2025, d’appliquer plutôt la mise à jour hors bande. « Celle-ci contient toutes les améliorations et tous les correctifs inclus dans la mise à jour non sécurisée de mai 2025 de Windows, en plus de la résolution de ce problème », a encore expliqué Microsoft. Comme il s’agit d’une mise à jour cumulative, les administrateurs n’ont pas besoin d’appliquer une mise à jour précédente avant d’installer KB5062170. En effet, elle remplace toutes les mises à jour précédentes pour les versions concernées. L’installation de cette mise à jour nécessite un redémarrage de l’appareil. Selon le fournisseur, il est peu probable que les utilisateurs des éditions Windows Home ou Pro soient confrontés à ce problème, car il y a peu de chance qu’ils exécutent des machines virtuelles.
Les analyses de cause profonde pas toujours publiées
Microsoft, comme d’autres grands éditeurs de logiciels, teste beaucoup les correctifs avant de les publier. Cependant, selon Tyler Reguly, directeur associé de la recherche et du développement en matière de sécurité chez Fortra, ils ne peuvent pas tout détecter. « Il est impossible de tester tous les cas de figure et tous les scénarios », a-t-il répondu dans un courriel. « De plus, à un moment donné, les tests à grande échelle nécessitent des humains, et les humains font des erreurs », a-t-il ajouté. « Pour ma part, je voudrais toujours savoir si le patch de l’éditeur vient corriger une erreur humaine ou un cas de figure jugé improbable. Malheureusement, très peu de fournisseurs sont disposés à publier les résultats de leur analyse des causes profondes, les root cause analysis (RCA). Le mieux que l’on peut espérer, c’est une solution rapide et un accord tacite pour que cela ne se reproduise plus. Et dans le cas d’une erreur humaine, s’assurer qu’elle ne se reproduira plus peut signifier des changements de processus ou de politique », a encore écrit M. Reguly, alors que les cas limites peuvent résulter d’un tas de variables. « Quand on parle de matériel et de virtualisation au-dessus du matériel, un grand nombre de choses peuvent mal tourner », a-t-il souligné. « Dans ce cas, même si l’on peut espérer que les fournisseurs détectent tout, il faut admettre que cette attente est irréaliste », a-t-il reconnu.
« Certains avanceront que l’IA est la solution pour éviter cela, mais tant que notre technologie existera en dehors d’un jardin clos, et tant que les utilisateurs auront le choix de leurs technologies, des problèmes de ce type continueront à se poser. Les responsables IT doivent simplement trouver le moyen de réagir rapidement et calmement. Si j’étais directeur de la sécurité informatique, c’est ce que je surveillerai en priorité et, en cas de défaillance ou de compromission, je regarderai comment nous avons réagi et dans quel délai nous avons récupéré », a poursuivi M. Reguly. « C’est la raison d’être d’un plan de continuité des activités et, si des erreurs de ce type ont un impact considérable, il faut se demander si le plan de continuité des activités est aussi solide qu’il doit l’être. »
Régler un problème de complexité
« Même un code ayant fait l’objet de tests approfondis peut échouer au premier contact avec les systèmes de production », fait également remarquer Gene Moody, directeur technique chez Action1, fournisseur de solutions de gestion des correctifs. « Il ne s’agit pas d’une défaillance de l’assurance qualité, mais d’un problème de complexité. Les environnements de test, aussi complets soient-ils, ne peuvent pas reproduire les bizarreries des systèmes réels, les changements non documentés, les logiciels hérités, les pilotes obscurs ou les états de système corrompus. Un correctif peut se comporter différemment en fonction de ce qui est en cours d’exécution, de ce qui a été installé précédemment ou de la manière dont le système a été entretenu et géré. Les problèmes de timing, les dérives liées à l’infrastructure et les cas limites de configuration sont presque impossibles à prévoir en laboratoire. Et en production, les outils de sécurité, les agents de conformité ou même les mises à jour antérieures partiellement ratées peuvent tous saboter le comportement des correctifs », a-t-il affirmé. « C’est la raison pour laquelle un déploiement progressif, une télémétrie solide et un rollback rapide sont plus importants que n’importe quel test en laboratoire. Aucune simulation ne peut totalement couvrir la variabilité du monde réel. Les administrateurs doivent bien connaître leurs propres environnements pour pouvoir tester et récupérer leurs systèmes dans des circonstances imprévues causées par des correctifs instables. »
Reposant sur la plateforme Bedrock d’AWS, l’assistant d’IA générative Alie créé par Alcatel-Lucent Enterprise permet déjà une réduction de 50 % du nombre d’appels arrivant à son centre support.
Alcatel-Lucent Enterprise (ALE) vient de créer Alie, un chatbot d’IA générative à destination de ses partenaires intégrateurs et de ses clients. Pour Christian Muths, datascientist chez Alcatel-ucent Enterprise, cet assistant sert d’abord à faire gagner du temps en accélérant le traitement des demandes support et en améliorant l’efficacité des interactions entre les partenaires et les clients sur les solutions du fournisseur.
En termes d’usages, ce chatbot autorise plusieurs choses. Déjà il fait office de support en 24/7, les utilisateurs peuvent gérer leurs tickets d’assistance en les créant, les mettant à jour et les consultant de manière interactive, tout en recevant des notifications sur l’avancement de leur demande. Au besoin, cet outil alerte les équipes techniques lorsqu’une intervention est requise. De plus, cet assistant a cette capacité à suivre les commandes de produits, répondre aux questions des techniciens sur le terrain, fournir des informations sur les niveaux de stock ou encore effectuer des recherches dans la documentation technique des produits. A ce titre, 600 000 pages d’informations techniques ont été injecté. « Les utilisateurs peuvent poser des questions comme : comment installe-t-on un équipement wifi ? Le chatbot lui donnera la réponse et des références liées aux documents. Et toutes les informations sont mises à jour », donne en exemple Christian Muths qui rappelle l’importance de la qualité des données pour amener de la valeur.Un assistant construit depuis la plateforme AWS BedrockDe plus, Alie apporte des réponses personnalisées dans la langue d’origine de la requête grâce à sa capacité à rechercher des documents multilingues et à traduire les réponses de manière fluide.Pour construire son chatbot, ALE s’est basée sur la plateforme Bedrock d’AWS, laquelle permet de créer un agent en quelques étapes. « Bedrock nous facilite le développement et nous apporte plusieurs modèles de LLM, ces derniers étant mis à jour continuellement », souligne Nathan Kroichvili, développeur datascientist chez ALE. En parallèle ce chatbot est aussi animé par PythiALE, le moteur GenAI interne d’Alcatel-Lucent Enterprise.Les porte-paroles de la société insistent aussi sur la sécurité du chatbot qui a été créé dans le respect des normes ISO 27001 (sécurité des systèmes d’information) et ISO 9001 (gestion de la qualité des données) et de la conformité au RGPD.Déjà 4 000 utilisateurs revendiquésDe même, les informations contenues dans ses bases de données sont chiffrées avec des sauvegardes automatiques et planifiées pour prévenir toute perte. Alie est accessible depuis Rainbow, la plateforme de communication cloud d’ALE, 4 000 utilisateurs seraient déjà satisaits par son usage. Son adoption a été immédiate, « aucune formation n’a été nécessaire, par définition, cet assistant GenAI permet de s’exprimer en langage naturel, c’est donc immédiatement intuitif. La seule communication que nous faisons auprès des utilisateurs concerne les nouvelles fonctionnalités et mises à jour », précise Christian Muths. Depuis la mise en oeuvre de son chatbot, le fournisseur constate une réduction de 50 % du nombre d’appels arrivant à son centre de support.
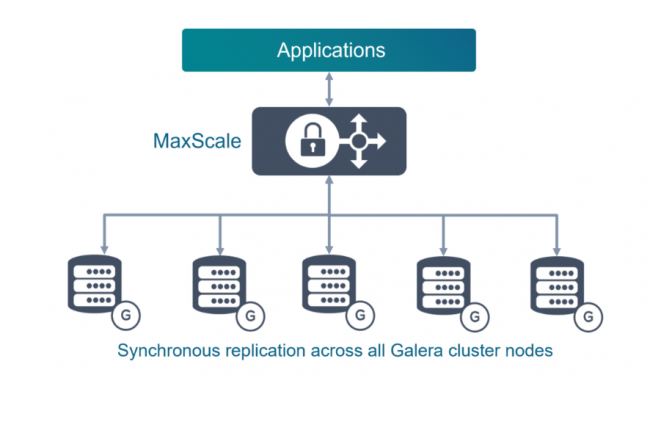
Selon les analystes, l’acquisition par MariaDB de Codership et de sa suite de réplication multi-maître synchrone pour les bases de données pourrait lui garantir des revenus récurrents. Tout en entravant la possibilité de voire émerger de futurs forks.
Le fournisseur en bases de données MariaDB, en difficulté, redouble d’efforts pour se remettre sur pied, ce qui est une bonne nouvelle pour les entreprises qui utilisent la base de données MariaDB ou celles qui souhaitent l’adopter. C’est du moins ce que pensent les analystes après l’annonce de l’acquisition du fournisseur finlandais de logiciels de réplication de données Codership. « Cette acquisition montre que, depuis son rachat par K1 en septembre dernier, MariaDB cherche à se transformer en plateforme de base de…
Il vous reste 91% de l’article à lireVous devez posséder un compte pour poursuivre la lecture
Vous avez déjà un compte?