






Après l’acquisition de la société britannique Howen, l’industriel américain de liquéfaction de gaz Chart Industries s’est retrouvé à la tête d’un imposant nombre de clouds. Pour en gérer la complexité, il a décidé de se tourner vers une plateforme de network as a service.
En mars 2023, le fabricant américain d’équipement pour le gaz industriel et l’énergie, au CA de plus de 6 Md$ (5,5 Md€), Chart Industries a acheté le Britannique Howden. Ce dernier est un des principaux fabricants d’équipements industriels de traitement de l’air et du gaz dont les résultats ont dépassé 3 Md£ (3,6 Md€). Cette opération d’envergure a, entre autres, fait plus que tripler le nombre de clouds de Chart Industries dans le monde, puisqu’il est passé de 40 à plus de 130. L’Américain a donc dû connecter et intégrer l’ensemble. Plutôt que d’investir dans des ressources coûteuses en interne, il a opté pour une plateforme de network as a service (NaaS), celle du Californien Alkira.Chart Industries travaille depuis environ un an à l’absorption des nombreuses infrastructures de Howden. Il affirme avoir intégré à son réseau, avec le NaaS, 90 sites beaucoup plus rapidement que ne l’aurait fait l’équipe IT. En particulier, en tenant compte des spécificités et défauts du réseau sur chaque site.Fusionner tous les clouds« Le plus gros atout de ce type de plateforme concerne bel et bien les fusions et acquisitions, explique Susan Tlacil, architecte réseau de Chart Industries. Nous avons été en mesure d’intégrer rapidement Howden sur notre dorsale cloud. Car, à chaque acquisition d’une entreprise, non seulement nous fusionnons les Google Cloud, Azure [de Microsoft] et AWS, mais nous pouvons également fusionner les tenants cloud, sur un seul réseau et un seul segment ».Le DSI et les équipes réseau n’ont pas eu à se soucier des problèmes de connectivité ou de l’exportation vers le hub Azure maison des imposantes quantités de documents Office 365 dont dispose Howen. L’industriel n’a pas non plus eu besoin de former le personnel ou d’embaucher davantage d’ingénieurs réseau pour auditer l’architecture réseau cloud unique à chaque site. « Azure, AWS et Google ont tous des protocoles réseau différents, poursuit l’architecte réseau. C’était un défi important pour nous, dont Alkira nous a protégés ».Alléger la charge IT liée aux acquisitionsChart Industries, qui migre progressivement son SI vers Azure depuis près de 5 ans, dispose déjà de la moitié de ses services dans le cloud. Il en ajoute chaque semaine, même s’il envisage un avenir multicloud. Il dispose d’une large gamme d’actifs informatiques sur site et en multicloud à gérer en raison de son activité en expansion dans le domaine du gaz liquéfié, dont la création et le stockage de pétrole et de gaz naturel, des produits gazeux d’hydrogène et d’azote et des réservoirs de dioxyde de carbone pour des clients du retail tels que la chaîne de restauration rapide Chick-fil-A.À l’origine, Chart Industries a fait appel à Alkira pour piloter à distance l’utilisation par ses clients de ses équipements de stockage sur le terrain, ce qui nécessite une maintenance et des contrôles de sécurité. La connexion des équipements IoT IP au VPN d’Alkira a fait gagner beaucoup de temps à l’industriel. S’il avait dû bâtir cette infrastructure lui-même, cela aurait nécessité beaucoup de matériel et la création d’un front-end par un développeur, ce qui « aurait probablement pris entre trois et six mois, selon Susan Tlacil. Avec le VPN, il a suffi de trois jours ! ».Connecter tous les datacenters et tous les cloudsLe principal fournisseur de dorsale de Chart Industries est Cisco, mais l’entreprise préfére Alkira pour connecter ses nombreux clouds, en particulier parce que la solution multicloud de l’éditeur présente une IHM et un comportement cohérents, quels que soient les plateformes, les régions et les environnements cloud. L’automatisation de l’intégration a été un des bénéfices principaux, selon l’industriel. Tout comme la prise en charge par la plateforme de la compréhension des différentes configurations techniques, mais aussi de la maintenance et des mises à niveau. Résultat : moins de ressources humaines et de temps passé, et davantage de fiabilité du réseau dans l’ensemble du groupe.L’industriel aimerait prolonger l’exploitation de la solution, afin de connecter tous les datacenters de l’entreprise à ses clouds, pour la reprise après sinistre en cas de panne du cloud par exemple, voire afin d’aller vers une réplication multicloud en temps réel. Autrement dit, une infrastructure réseau en NaaS qui puisse être étendue à n’importe quel service IT, qu’il soit sur le cloud ou on premise.
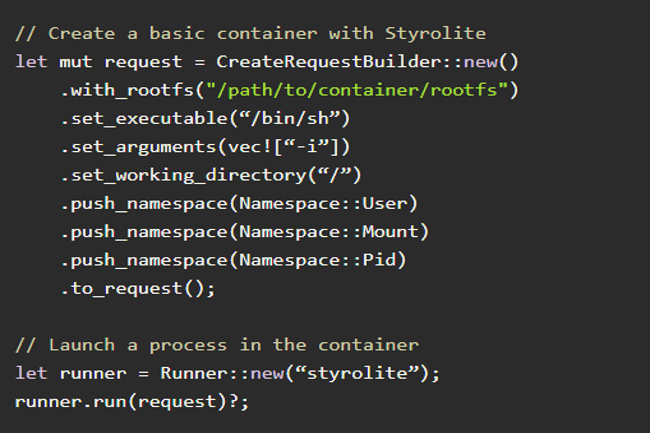
Cet outil de sandboxing programmable verrouille les namespaces du noyau Linux afin de fournir des zones de test légers pour les charges de travail basées sur des conteneurs.
Lancé récemment par Edera, le projet open source Styrolite contrôle plus strictement les interactions entre les conteneurs et les namespaces du noyau Linux, en intervenant à un niveau qui se situe en dessous de la couche où opèrent les runtimes de l’Open Container Initiative (OCI) comme containerd. Ces dernières années, alors que des incidents de sécurité du cycle de développement des logiciels, comme Log4j et XZ Utils, ont fait les gros titres de la sécurité des conteneurs, le runtime des conteneurs reste une cible attractive pour les pirates. À l’aide d’exploits qui ciblent les sous-systèmes de bas niveau du noyau, comme Dirty Cow et Dirty Pipe, les attaquants parviennent à s’échapper des conteneurs et à élever leurs privilèges.
Grâce à l’outil de sandboxing programmable Styrolite créé par Ariadne Conill, cofondatrice et ingénieure d’Edera, les équipes d’ingénierie des plateformes peuvent « mettre en quarantaine » les interactions entre les conteneurs et les espaces de noms Linux. Le nom est tiré d’une substance dure et transparente utilisée pour isoler un patient de son environnement dans l’œuvre de science-fiction Star Trek Next Generation. « Historiquement, le moteur d’exécution des conteneurs a fourni de très mauvaises garanties d’isolation », a expliqué Mme Conill. « Nous en sommes arrivés à un point où les gens ne comprennent tout simplement pas comment ces composants s’assemblent et pensent que les espaces de noms fournissent une véritable isolation », a-t-elle ajouté. « Or, c’est impossible, car ils existent en tant que sous-ensemble de l’état partagé du noyau. »
Espaces de noms Linux glissants
Les namespaces Linux permettent aux conteneurs de se disputer les ressources sous-jacentes dans les environnements multi-locataires. Mais alors que le réconciliation entre le conteneur et Kubernetes a besoin d’une certaine flexibilité pour placer les charges de travail côte à côte sur différents hôtes Linux à travers les clusters, les espaces de noms Linux n’ont jamais été conçus pour servir de frontières de sécurité. C’est la raison pour laquelle les attaques et les évasions de conteneurs sont si fréquentes. « L’outil Styrolite est comme une interface d’exécution de conteneur (CRI), mais il se concentre sur les interactions réelles des conteneurs avec le noyau », a expliqué Mme Conill. « Styrolite se focalise sur la sécurisation des processus qui sont au cœur du montage des images dans les espaces de noms, et en particulier le chronométrage, les montages et les collections de processus dans l’espace de noms des identifiants de processus. »
En gérant le cycle de vie de ces interactions fondamentales avec l’espace de noms, Styrolite offre aux ingénieurs un contrôle beaucoup plus granulaire sur les interactions des ressources des conteneurs, par le biais de la configuration de leurs images de conteneurs. Écrit en Rust et conçu comme un microservice, Styrolite « comble le fossé entre le paradigme moderne du cloud et les techniques de sécurité traditionnelles comme la sécurité basée sur la virtualisation », a ajouté Mme Conill. « Nous avons fait en sorte que Styrolite se comporte de la même manière que les composants OCI », a-t-elle poursuivi. « Essentiellement, nous avons transformé la gestion du bac à sable de conteneur en un microservice approprié qui fait exactement la même chose que ce que fait Kubernetes quand il utilise l’IRC pour se connecter à containerd ou à d’autres implémentations de l’IRC. »
Exécution des conteneurs dans un bac à sable
Styrolite n’est pas le premier outil de sandboxing des runtimes de conteneurs. Bubblewrap est le plus connu, et ce projet de sandboxing de conteneurs de bas niveau est communément utilisé pour les constructions Fedora et RPM. « Ces outils sont soit de trop haut niveau (comme l’IRC de Kubernetes), soit il faut les utiliser via des scripts shell », a précisé Mme Conill. « Si avec les CLI, on peut itérer rapidement, nous voulions construire une interface programmatique riche pour le spawning et la gestion des conteneurs. »
Les développeurs et les professionnels de la sécurité habitués à Bubblewrap remarqueront immédiatement que Styrolite gère les configurations de sécurité différemment. « Bubblewrap est un outil très radical, dont l’interface de ligne de commande complexe va parfois trop vite et peut entrainer une escalade des privilèges des hôtes par inadvertance », a fait remarquer Mme Conill. « C’est en naviguant dans ces configurations d’exécution sans les garde-fous appropriés que l’on peut accidentellement accorder à des conteneurs un accès complet au répertoire racine d’un hôte, alors que l’on essayait simplement de passer par le partage de fichiers », a ajouté Mme Conill qui estime qu’une prise de conscience générale est en cours dans le domaine de la sécurité des conteneurs et que des outils comme Styrolite sont essentiels pour améliorer la configurabilité de la sécurité par défaut.
Des chercheurs affirment que leur protocole donne une capacité de créer des nombres réellement aléatoires sur un ordinateur quantique actuel servant à des applications sécurisées pour des domaines variés allant de la finance à la cybersécurité.
Si la recherche dans l’informatique quantique se focalise sur la création d’un qbit logique et la réduction des taux d’erreur, les universitaires travaillent également sur les usages. Et en particulier sur la génération de nombres aléatoires, un procédé essentiel pour le chiffrement des données. Des chercheurs viennent d’indiquer avoir trouvé un protocole dans ce domaine et ainsi sécuriser différentes applications allant de la finance à la cybersécurité. Néanmoins, une analyste du secteur se montre prudente. « Les conclusions de l’équipe de JPMorgan sont intéressantes, mais ne seront pas applicables à court terme pour la plupart des responsables de la sécurité, à moins qu’ils ne soient responsables d’environnements hautement sécurisés », a déclaré Sandy Carielli, analyste principale chez Forrester Research. « La génération de nombres aléatoires quantiques existe depuis un certain temps et des RSSI peuvent déjà utiliser des produits dans ce domaine », a-t-elle rappelé, ajoutant que « une telle certification pourrait être un atout supplémentaire pour les environnements très réglementés. »
Pour protéger les solutions actuelles et en créer de nouvelles à l’aide d’ordinateurs quantiques, il faudra des applications capables de générer des nombres aléatoires imprévisibles pour les clés de chiffrement et impossibles à déchiffrer par les machines quantiques. « La génération de nombres aléatoires est à la base d’un chiffrement efficace, car elle est nécessaire pour créer des clés de manière optimale », a expliqué Mme Carielli. « Si un déficit du caractère aléatoire réduit le nombre de clés potentielles d’un facteur significatif, un attaquant peut utiliser la force brute ou deviner une clé », a-t-elle ajouté. « Au fil des ans, des problèmes liés à une mauvaise génération de nombres aléatoires ont entravé la mise en œuvre de la cryptographie. Il existe également de nombreuses méthodes de génération de nombres aléatoires réputées. L’utilisation d’un ordinateur quantique pour la génération de nombres aléatoires est certainement une option, mais elle pose aussi des questions de coût ou d’évolutivité. »
La création de nombres véritablement aléatoires possible
Selon les auteurs de l’article publié dans Nature, les recherches montrent que les ordinateurs quantiques peuvent résoudre des problèmes mieux que les techniques informatiques classiques, mais que les besoins en ressources des algorithmes quantiques connus pour ces problèmes les placent loin de la portée des machines quantiques actuelles ou à venir à court terme. Cependant, les chercheurs de JPMorganChase, Quantinuum, Argonne National Laboratory, Oak Ridge National Laboratory et de l’université du Texas à Austin, affirment que leur solution montre que les ordinateurs quantiques actuels et de court terme, basés sur des portes quantiques peuvent effectuer au moins une tâche utile sur le plan pratique : créer des nombres véritablement aléatoires. L’équipe y est parvenue en élaborant un protocole qui a fonctionné sur Internet avec un ordinateur quantique à ions piégés de 56 qubits de l’entreprise américaine Quantinuum. Selon un communiqué de JPMorganChase, les chercheurs ont tiré parti d’une tâche conçue à l’origine pour démontrer l’avantage quantique, connue sous le nom de random circuit sampling (RCS), pour exécuter un protocole d’expansion de caractère aléatoire certifié, qui produit plus d’aléatoire qu’il n’en prend en entrée. Selon eux, cette tâche est irréalisable par l’informatique classique.
Dans un billet de blog, JPMorganChase explique que le type du caractère aléatoire idéal présenterait les trois caractéristiques suivantes :
1. Provenir d’une source fiable et vérifiable2. Être assorti de garanties mathématiques rigoureuses3. Ne pas avoir été manipulé par un adversaire malveillant
C’est ce qu’on appelle un caractère aléatoire certifié ou certified randomness. Et, selon l’article, « il s’avère qu’un tel protocole est impossible à réaliser à l’aide d’ordinateurs conventionnels, mais qu’il peut l’être à l’aide d’un ordinateur quantique. » Ce procédé comprend deux étapes. Tout d’abord, il génère des circuits aléatoires de défi (les programmes quantiques sont appelés circuits) et les envoie à l’ordinateur quantique distant non fiable, qui doit alors renvoyer les nombres « aléatoires » obtenus. Cette méthodologie a également été testée par rapport aux meilleures techniques actuellement connues pour simuler des circuits aléatoires sur les supercalculateurs conventionnels les plus puissants du monde. Alors que le temps d’exécution quantique par défi était d’environ deux secondes, l’équipe a estimé que les circuits de défi ne pouvaient être simulés de manière classique qu’en 100 secondes environ.
Ensuite, pour vérifier que de véritables nombres aléatoires avaient été générés, le caractère aléatoire des résultats a été certifié mathématiquement à l’aide de superordinateurs classiques du département américain de l’énergie. « Lorsque j’ai proposé pour la première fois mon protocole de hasard certifié en 2018, je n’avais aucune idée du temps qu’il faudrait attendre pour en voir une démonstration expérimentale », a reconnu dans un communiqué Scott Aaronson, titulaire de la Schlumberger Centennial Chair of Computer Science et directeur du Quantum Information Center à l’Université du Texas à Austin. « Je suis ravi que JPMorganChase et Quantinuum se soient appuyés sur le protocole original et l’aient réalisé. C’est un premier pas vers l’utilisation d’ordinateurs quantiques pour générer des bits aléatoires certifiés pour des applications cryptographiques réelles », s’est-il félicité.
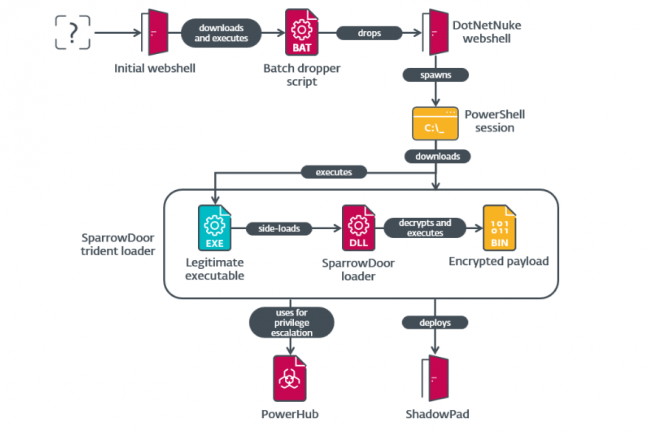
Le groupe de cybercriminels Salt Typhoon déploie deux variantes non documentées de la porte dérobée SparrowDoor avec des capacités améliorées de modularité et d’exécution de commandes parallèles.
Salt Typhoon, le célèbre groupe APT soutenu par la Chine, semble avoir mis à jour son arsenal avec des portes dérobées améliorées, alors même que les États-Unis augmentent la pression sur l’espionnage chinois. Selon Eset Research, qui suit le groupe malveillant en tant que FamousSparrow, celui-ci a déployé deux versions de sa porte dérobée SparrowDoor avec plus de modularité et une exécution parallèle des commandes. Ces deux versions de la backdoor « constituent un progrès notable par rapport aux versions précédentes, notamment en termes de qualité du code et d’architecture », explique Eset dans un billet de blog. « L’une d’entre elles ressemble à la porte dérobée que les chercheurs de Trend Micro ont appelée CrowDoor et qu’ils ont attribuée au groupe APT Earth Estries en novembre 2024. GhostSparrow – alias Salt Typhoon (Microsoft), Earth Estries (Trend Micro), Ghost Emperor (Kaspersky Labs) et UNC2286 (Mandiant) – a intensifié ses activités de cyberespionnage en pénétrant dans les réseaux de télécommunications américains et en accédant aux données de plus d’un million de personnes.
L’une des principales caractéristiques des deux variantes inédites signalées par Eset est leur capacité à exécuter des commandes en parallèle. Cela signifie que les dernières variantes peuvent exécuter des tâches en parallèle afin d’améliorer l’efficacité, d’échapper à la détection et de maintenir la persistance. « Le changement le plus important est la parallélisation des commandes qui prennent du temps, telles que les E/S de fichiers et le shell interactif », explique Eset. « Cela permet à la porte dérobée de continuer à traiter des commandes pendant que ces tâches sont exécutées. L’exécution simultanée d’opérations critiques mais chronophages vers d’autres commandes rend la détection et l’interruption plus difficiles, car les tâches telles que l’exfiltration de données ou la modification du système se poursuivent sans interruption, même si l’on tente d’analyser ou d’interrompre la porte dérobée. En outre, le caractère modulaire introduit dans la porte dérobée lui confère une capacité à mettre à jour dynamiquement les configurations, de passer d’un serveur C&C à un autre et d’exécuter des charges utiles personnalisées sans redéploiement, selon Eset
Des variantes inédites utilisées contre des entreprises américaines et mexicaines
Les chercheurs d’Eset ont déclaré avoir repéré les variantes de SparrowDoor lors d’une enquête sur un incident de sécurité survenu en juillet 2024 au sein d’un groupe de commerce financier opérant aux États-Unis. « En aidant l’entité concernée à remédier à la compromission, nous avons fait une découverte inattendue dans le réseau de la victime », ont déclaré les chercheurs. « Cette campagne est également la première fois que FamousSparrow a utilisé ShadowPad, une porte dérobée vendue dans le privé, connue pour n’être fournie qu’à des acteurs de menaces alignés sur la Chine. La campagne s’est étendue à l’intrusion dans un institut de recherche au Mexique, deux jours avant la compromission aux États-Unis. Lorsque les chercheurs ont introduit les techniques et les IoC dans un système de suivi, ils ont révélé d’autres activités, dont une attaque contre un institut gouvernemental au Honduras.
Contrairement à Microsoft qui affirme que Salt Typhoon recouvre la même chose que FamousSparrow et GhostEmperor, Eset n’a pas fait ce choix. « Il y a quelques chevauchements entre les deux, mais de nombreuses divergences », souligne l’entreprise. « D’après nos données et notre analyse des rapports publics, FamousSparrow semble constituer un groupe distinct ayant des liens éloignés avec les autres groupes mentionnés dans ce rapport […] À l’heure où nous écrivons ces lignes, Microsoft, qui a créé le groupe Salt Typhoon, n’a pas publié d’indicateurs techniques ni de détails sur les TTP utilisées par l’acteur de la menace, et n’a pas non plus fourni d’explication à cette attribution. Pour éviter de brouiller davantage les pistes, nous continuerons à suivre le groupe d’activités que nous considérons comme directement lié à SparrowDoor sous le nom de FamousSparrow jusqu’à ce que nous disposions des informations nécessaires pour évaluer de manière fiable ces demandes d’attribution. »
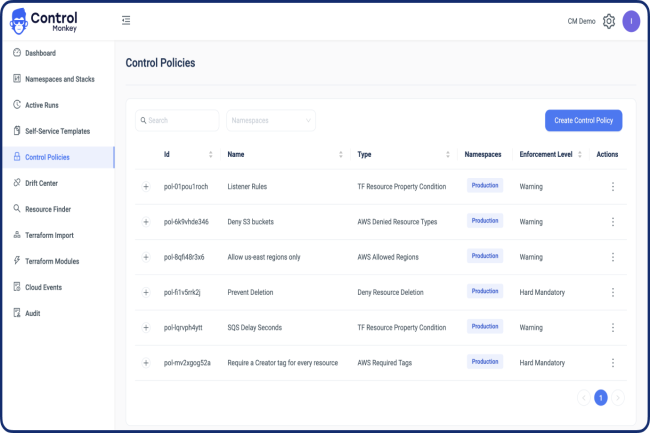
Après le Chaos Monkey, une méthode pour éprouver la résilience du système d’information, ControlMonkey veut apporter plus de maîtrise dans les procédures de reprise d’activité dans le cloud.
Le déploiement d’une infrastructure cloud comprend un grand nombre de composants différents. Combien d’entre eux sont réellement sauvegardés pour assurer une bonne reprise d’activité après un sinistre ? C’est une question à laquelle la start-up ControlMonkey, spécialisée dans l’automatisation de l’infrastructure cloud, tente de répondre. Fondée en 2022 et basée en Israël, elle propose une réponse automatisée et focalisée sur l’infrastructure, un point faible dans les plans de reprise d’activité plutôt orientés sur la protection des données ou des applications.
Cette fonctionnalité met à disposition une sauvegarde automatisée et une récupération en un clic des configurations réseau, des paramètres DNS, des configurations CDN, des pare-feu, des groupes de sécurité et d’autres composants de l’infrastructure qui sont essentiels pour la fourniture d’applications, mais souvent négligés dans la planification traditionnelle d’un PRA. ControlMonkey, dont le nom contraste délibérément avec le célèbre outil de test de résilience « Chaos Monkey » de Netflix, adopte une approche opposée. « Chaos Monkey apporte le chaos à votre cloud et ControlMonkey apporte le contrôle », a déclaré Aharon Twizer, CEO et cofondateur de ControlMonkey, à Network World.
Générer du code Terraform pour le PRA cloud
Habituellement, les entreprises se servent d’outils d’infrastructure as code (IaC) comme Terraform pour définir l’environnement de déploiement cloud. ControlMonkey ne cherche pas à remplacer ce dernier, mais plutôt à améliorer le PRA. « La plupart des entreprises ne disposent pas d’une couverture complète de l’ensemble de leur infrastructure dans le cadre de l’infra as code, ce qui entraîne de nombreux angles morts – vous ne savez pas ce que vous ne savez pas », a souligné le dirigeant. En outre, il a noté qu’il peut être difficile de maintenir l’IaC dans un état qui représente toujours la configuration existante. Il y a des choses comme la dérive, les gens qui changent des choses directement dans la console, et d’autres scénarios du monde réel qui ont un impact sur l’infrastructure.
Pour résoudre ce problème, ControlMonkey utilise des algorithmes d’IA pour générer du code Terraform, connu sous le nom de Hashicorp Configuration Language (HCL), pour les environnements cloud existants. Il aide ainsi les clients à atteindre une couverture de 100 % de l’IaC. Une approche de plus en plus courante dans ce domaine est connue sous le nom de GitOps, où les changements de configuration sont effectués dans le référentiel de contrôle de version Git, puis mis en service. ControlMonkey est également en mesure de s’intégrer aux référentiels Git afin d’offrir un meilleur contrôle des modifications de l’infrastructure as a code et des capacités de sauvegarde.
L’objectif de restaurer en un clic
Compte tenu de la complexité des configurations cloud, en particulier dans les environnements multicloud distribués avec des topologies de réseau compliquées, la restauration du service est souvent un exercice non trivial pour la reprise après sinistre. Aharon Twizer affirme que ControlMonkey peut le faire en un seul clic. « La façon dont ControlMonkey fonctionne est de scanner toute votre configuration réelle, génèrer du code Terraform à partir de celle-ci et fournir ensuite une restauration en un clic pour la configuration », a-t-il expliqué. Il ajoute « vous pouvez effectuer des recherches, déterminer quelle configuration a été modifiée et à quel moment, et la restaurer en un seul clic ». Selon lui, cette approche réduit le temps de récupération de 90 % par rapport aux efforts de reconstruction manuelle, une mesure essentielle pour les équipes d’exploitation du réseau qui s’efforcent de minimiser les temps d’arrêt.
La reprise après sinistre n’est pas seulement une procédure qu’il est bon d’avoir, elle fait aussi souvent partie de la conformité réglementaire. « Les normes SOC 2 et ISO 27001 prévoient notamment des plans de reprise après sinistre et de continuité des activités », fait remarquer le dirigeant. « La configuration de l’infrastructure est négligée et la plupart des solutions se concentrent sur les données, mais nous considérons que l’infrastructure as code est en train de devenir une priorité », conclut-il.
En cybersécurité, l’IA joue un double rôle : le gentil en aidant à détecter et à prévenir les menaces, à automatiser les processus de sécurité, à simuler et anticiper les cyberattaques puis à gagner du temps, et le méchant en aidant les cybercriminels à développer des malwares plus sophistiqués, à identifier plus rapidement les cibles ou encore à mener des attaques à grande échelle et en continu. C’est donc ce double visage de l’IA que nous allons détailler dans ce dossier. En soi, l’IA ou plutôt le machine learning est exploité depuis des années dans les solutions de sécurité et les SOC, mais l’arrivée de l’IA générative et les dernières avancées technologiques de l’IA permettent de franchir un pas supplémentaire dans la détection et la prédiction. Bien sûr, l’IA Gen pose aussi des problèmes éthiques et de conformité vis-à-vis des règlements existants, les DPO devront aussi s’y pencher. Enfin, la souveraineté ou du moins une IA de confiance sera-t-elle la solution pour disposer d’une IA plus sûre. (Crédit Freepik)

La dette technique ne concerne pas seulement l’infrastructure matérielle ou logicielle. Loin de là. L’accumulation historique de data, de procédures de sécurité, de développements d’IA et même d’une forme de culture d’entreprise peuvent aussi en faire partie. Les DSI devraient au moins être attentifs à 7 types de dette technique.
Les DSI sont constamment confrontés aux risques, au coût et à la complexité de la dette technique. Et bien que son impact puisse être quantifié globalement, cette dernière s’insinue aussi de manière plus subtile dans l’écosystème IT, rendant en réalité difficile la prise en compte de tous les problèmes et risques associés.Selon le cabinet d’analyse Forrester, près de 30% des responsables informatiques sont confrontés à des dettes élevées ou critiques, et 49 % à des niveaux modérés. Mais même un risque moins important (modéré à faible) peut se transformer en frein majeur s’il concerne une application clé, car il peut devenir un obstacle lorsque celle-ci doit être modernisée.Selon Accenture, les trois principales sources de dette technique se trouvent dans les applications, l’IA et l’architecture d’entreprise. Des enjeux considérables, mais le sont-ils moins si on parle de données, de sécurité, de culture d’entreprise ou d’autres domaines pour lesquels les raccourcis d’hier, pris par la DSI, deviennent les dettes d’aujourd’hui ? Par ailleurs, une autre question se pose : qu’est-ce qui distingue une dette qui provient d’une ‘réparation’ opportuniste d’une dette critique qui pourrait paralyser l’entreprise ?Pour faire face à ces enjeux, les DSI devraient considérer les sept formes de dette technique suivantes, comprendre pourquoi elles sont critiques et comment les traiter.1. Quand la dette de données nuit à la prise de décisionOn peut prendre l’exemple de cette entreprise qui a annoncé à son conseil d’administration une année rentable, pour découvrir au retour de vacances que des problèmes de qualité des données et des erreurs de calcul ont en réalité masqué des résultats déficitaires. Les DSI qui travaillent sur la transformation data driven de leur entreprise et s’appuient en particulier sur de la citizen data science sont les plus touchés par la dette de données, car une mauvaise interprétation ou un mauvais calcul de date, de montant ou de seuil peuvent conduire à de mauvaises décisions business. Les types de dettes de données incluent la dark data (inutilisée, inconnue ou inexploitée), les doublons et les données qui n’ont pas été intégrées dans le Master Data Management.Et dans ce contexte, l’utilisation des données de l’entreprise pour entraîner des LLM ou pour exploiter des agents IA ou encore d’autres modèles d’IA générative crée encore plus de risques. Les biais, les lacunes dans la classification ou les politiques d’autorisation inadéquates peuvent tous entraîner de mauvaises prises de décision, des risques liés à la conformité et des problèmes avec un impact sur les clients.Pour réduire cette dette data, les DSI peuvent assigner spécifiquement des responsabilités de gouvernance et d’analytique dans des équipes data agiles, via l’observabilité des données et la définition d’indicateurs de qualité.2. Quand le data management limite les performancesLa dette liée au data management peut survenir d’un seul coup ou, au contraire, s’accumuler au fil du temps, elle peut résulter d’un manque d’automatisation ou encore provenir d’une réponse à incident.- La dette soudaine : les services informatiques qui procèdent à du lift-and-shift de volumineuses bases de data vers le cloud sans optimiser l’architecture de ces bases, peuvent tout à fait générer une forte augmentation de la dette en data management qu’il leur faudra bien réduire au fil du temps.- La dette progressive : pour soutenir dans le temps l’augmentation continue de la taille, de la complexité et de l’utilisation de certaines bases, les DSI doivent en repenser le modèle et l’architecture.- L’absence d’automatisation : les administrateurs de bases de données consacrent trop de temps à des procédures d’exploitation restées manuelles et qui devraient être automatisées. C’est le cas de la création de sauvegardes, de l’administration des privilèges, de la synchronisation des données entre systèmes ou des opérations liées au provisionnement de l’infrastructure.- La réponse aux incidents : la lutte contre les problèmes quotidiens, le traitement d’incidents majeurs ou la recherche des causes profondes de ces problèmes empêchent les administrateurs de bases de données d’effectuer des tâches plus proactives.Pour réduire la dette de data management, les DSI peuvent commencer par mesurer le temps que les administrateurs de bases de données consacrent aux procédures d’exploitation manuelles et à la réponse aux incidents afin d’évaluer cette dette. Pour la réduire, ils peuvent automatiser les tâches, entamer la migration vers des offres de base de données as-a-service (DBaaS) et procéder à l’archivage des anciens data sets.3. Quand la dette de dépendance à l’Open Source pèse sur le devopsPour un développeur, il semble plus facile d’écrire du code que de revoir celui de quelqu’un d’autre et de comprendre comment il fonctionne. Et il lui semble souvent encore plus facile chercher et d’intégrer des bibliothèques et des composants Open Source, car le support à long terme du logiciel n’est pas sa préoccupation première lorsqu’il est contraint par les délais et des déploiements fréquents.De nombreuses équipes laissent ainsi s’accumuler des composants Open Source obsolètes, redondants ou non pris en charge, comme l’explique Mitchell Johnson, chief product development officer de l’éditeur d’outils de gestion de la supply chain logicielle Sonatype. « Une application moyenne contient 180 composants, et ne pas les mettre à jour génère un code volumineux, des failles de sécurité et une dette technique croissante ». Selon le rapport 2025 Open Source security and risk analysis de l’éditeur d’AST (application security testing) Black Duck, 81% des codes analysés contiennent des vulnérabilités à risque élevé ou critique, et 90% des composants sont en retard de plus de 10 versions par rapport à la mouture la plus récente.Pour traiter la question, les DSI doivent notamment rechercher la fréquence des mises à jour de code perturbant les systèmes, l’augmentation des alertes de sécurité ou le temps consacré à la résolution des conflits de dépendance. Pour réduire cette forme de dette, ils peuvent former les équipes DevOps spécifiques sur les risques de sécurité Open Source, établir des politiques de gouvernance sur l’évaluation et l’approbation des packages, et utiliser les outils SAST pour trouver les vulnérabilités de code.4. Quand la dette de l’IA se révèle inévitableMême si les DSI définissent une gouvernance pour la GenAI, l’évolution rapide des modèles, des réglementations associées et du potentiel de l’IA agentique vont forcément leur apporter des problèmes de dette liée à l’IA. La dette technique dans les systèmes d’IA se manifeste différemment de la dette IT traditionnelle, car il ne s’agit pas seulement de maintenir le code, mais aussi l’ensemble du cycle de vie de la gouvernance des données et des modèles, selon Eric Johnson, DSI de l’éditeur de gestion d’incidents dans le cloud PagerDuty. « Les entreprises qui développent des solutions d’IA personnalisées risquent de créer de nouvelles formes de dette technique plus coûteuses et complexes à dénouer que les défis architecturaux habituels. La clé est d’établir des bases solides de gouvernance de la data et d’infrastructure avant de se lancer ».Alors que de nombreuses formes de dette technique entraînent des problèmes continus de maintenance, la dérive d’un modèle d’IA est un exemple de dette incrémentale. Et une partie de cette dette pourrait même contraindre les DSI à démanteler et remplacer certaines IA lorsque les nouveaux modèles présentent des améliorations importantes en matière de précision, de performance ou de coût, rendant les modèles précédents obsolètes. Une autre inquiétude provient de la possibilité de voir les réglementations demander un réentraînement holistique des modèles, ce qui obligerait les DSI à se tourner vers d’autres solutions pour rester conformes.Face à cette forme de dette, les DSI peuvent investir dans des tests de régression et des méthodes de gestion du changement associées aux workflows augmentés à grande échelle par l’IA.5. Quand la dette d’architecture s’érode et crée du legacyIl est possible de remédier à certaines formes de dette applicative en modernisant les applications, en les faisant migrer vers de nouvelles plateformes ou en utilisant des outils d’IA pour documenter et expliquer le code existant. Parmi les sources les plus importantes de dette architecturale, on peut citer :- une forte personnalisation du code dans les ERP ou autres systèmes d’entreprise ;- l’intégration de systèmes point à point sans data fabric ou plateforme d’intégration ;- les microservices et les API déployés sans normes de sécurité, de test, de versioning ni standards d’observabilité ;- les architectures multicloud configurées pour un déploiement précoce, et dont la maintenance engendre des coûts, du temps et un fort besoin d’expertise ;Les DSI à la tête d’architectures tentaculaires doivent envisager des simplifications et l’établissement de pratiques d’observabilité de l’architecture. Ils doivent notamment créer des indicateurs de performance de l’architecture et de la plateforme en agrégeant le monitoring applicatif, l’observabilité, la qualité du code, le TCO, les temps de cycle DevOps et les mesures relatives aux incidents, afin d’évaluer l’impact complet de l’architecture sur l’activité de l’entreprise.Les évolutions technologiques créent une dette d’architecture que tous les DSI doivent gérer au fil du temps, s’ils ne veulent pas qu’elle devienne insoutenable. L’un des domaines qu’ils peuvent maîtriser, c’est le niveau de personnalisation des applications pour éviter la complexité des règles métier gravées dans le code. Ils peuvent aussi repenser les règles d’architecture, en indiquant clairement la répartition du pouvoir de décision en la matière entre les équipes de développement agiles et les architectes d’entreprise.6. Quand la dette de sécurité dans les implémentations d’IA est inexplicableLa dette de sécurité se présente sous de nombreuses formes, telles que l’absence de politiques applicables, l’inadéquation de la formation des utilisateurs finaux et l’incapacité à modifier les pratiques de sécurité en shift left dans les pratiques DevOps. Les RSSI doivent alors gérer des cycles sans fin de rattrapage de failles, tout en s’occupant des menaces en cours.Mais avec les modèles d’IA, la question est encore moins simple. Bien que les organisations puissent prendre des mesures pour empêcher l’utilisation d’informations confidentielles pour les entraîner, il est difficile de savoir quelles informations privées se trouvent dans le modèle ou s’il existe des options pour les supprimer. Les modèles d’IA générative peuvent introduire des vulnérabilités dans le modèle lui-même, renfermer des violations de données ou être sensibles à des adversarial attacks (manipulations du modèle pour le pousser à l’erreur) qui peuvent s’accumuler.Giovanni Lanzani, directeur data de la SSII Xebia, donne l’exemple d’un chatbot bancaire pour les clients. « Il faudrait un framework de GenAI à grande échelle pour cette instance afin de mettre en oeuvre de solides garde-fous contre les injections de prompts et d’éviter de donner de mauvais conseils financiers ou de dénigrer la banque, par exemple. Ce framework devrait aussi s’occuper d’anonymiser toutes les informations personnelles identifiables afin que le chatbot hébergé dans le cloud ne puisse pas être alimenté par ce type de données ».Les DSI devraient être plus attentifs à la gouvernance de la sécurité de l’IA. Les pratiques DevSecOps ont, en effet, longtemps été à la traîne dans les chaînes automatisées de CI/CD (intégration continue/distribution continue), alors que les entreprises ont rapidement adopté la citizen Data Science, laissant ainsi de côté d’indispensables pratiques de gouvernance data. Or, lorsqu’il s’agit d’IA, cela peut entraîner des risques inacceptables, d’autant que les agents d’IA sont déployés dans des applications d’entreprise ou mis en contact direct des clients.7. Quand la dette culturelle accentue les problèmesDans une démarche de transformation numérique, le plus difficile est d’embarquer des ‘early adopters’, de favoriser la gestion du changement et de faire face aux réticences des détracteurs. La GenAI vient alourdir la dette culturelle des organisations à mesure que les experts métiers quittent le marché du travail et transmettent insuffisamment de savoir aux employés susceptibles d’assumer leurs responsabilités. La dette culturelle peut aussi avoir des impacts négatifs spécifiquement liés à l’IA, comme l’absence de pratiques d’ingénierie adaptées, la résistance à l’innovation, le manque de partage des connaissances tacites et l’incapacité à adopter des pratiques modernes.Les DSI qui ne veulent pas utiliser l’IA comme un simple moteur de productivité, mais comme un outil de transformation, doivent aussi reconnaître l’importance des craintes de perte d’emploi associées à cette technologie, et guider les employés dans l’utilisation de l’IA pour augmenter, et pas seulement automatiser, leurs capacités.De façon générale, alors que les DSI sont sous pression pour accélérer la mise en oeuvre de l’IA, laisser derrière soi une dette technique trop importante peut devenir un frein à l’innovation et à la transformation.
Une vulnérabilité débouchant sur des problèmes de contrôle d’accès inappropriés dans VMware Tools pour Windows a été corrigée par Broadcom. Avec à la clé un risque d’escalade de privilèges sur les machines virtuelles concernées.
Broadcom a averti ses clients de l’existence d’une faille de sécurité de type contournement d’authentification affectant VMware Tools pour Windows. Identifiée sous le nom de CVE-2025-22230, cette vulnérabilité tire parti d’un contrôle d’accès inapproprié et pourrait entraîner une escalade de privilèges sur le système affecté. « Une vulnérabilité de contournement d’authentification dans VMware Tools pour Windows a été signalée à l’éditeur », a déclaré Broadcom dans un avis de sécurité. « Des mises à jour sont disponibles pour remédier à cette faille dans les produits VMware concernés. »
L’outil concerné est une suite d’utilitaires conçus pour améliorer les performances et les fonctionnalités des machines virtuelles basées sur Windows et exécutées sur les hyperviseurs du spécialiste de la virtualisation (ESXi ou Workstation). La faille s’est vue attribuer un score CVSS de 7,8 sur 10 et est considérée d’importance élevée car elle peut être exploitée dans le cadre d’attaques peu complexes sans aucune interaction avec l’utilisateur. « Un acteur malveillant disposant de privilèges non administratifs sur une VM invitée peut avoir la possibilité d’effectuer certaines opérations à privilèges élevés au sein de cette VM », a déclaré Broadcom dans un bulletin de sécurité.
Les versions Linux et macOS de VMware Tools épargnées
Bien que le fournisseur n’ait pas mentionné les privilèges exacts pouvant être obtenus à la suite d’un exploit réussi, les risques courants associés à un privilège de niveau admin/root sur les machines virtuelles vulnérables comprennent l’évasion de VM pour attaquer l’hôte, le déplacement latéral vers d’autres machines virtuelles, ainsi que la création et le contrôle de machines virtuelles malveillantes. Ce trou de sécurité a été signalé à VMware par Sergey Bliznyuk de Positive Technologies. L’avis de Broadcom indique que la brèche n’a pas de solution de contournement et que les clients doivent appliquer les correctifs déployés mardi dernier pour se prémunir contre son exploitation. Les produits concernés comprennent toutes les versions 11.x et 12.x des outils VMware pour Windows, et sont corrigés dans la version 12.5.1. Les outils VMware pour Linux et macOS ne sont pas concernés et les clients n’ont rien à faire.
Au début du mois, VMware avait déjà comblé trois vulnérabilités critiques affectant ses produits ESXi, Workstation et Fusion, qui étaient activement exploitées dans la nature par des attaquants. Ses solutions constituent une cible attrayante pour les acteurs de la menace en raison de leur utilisation intensive dans les SI des entreprises, le cloud et les centres de données. L’exploitation de ces produits peut donner la possibilité aux attaquants d’obtenir des accès à privilèges, de perturber les services critiques et de faciliter les mouvements latéraux dans les environnements virtualisés.
La société française Vaultys annonce l’ouverture de son protocole d’identification décentralisée VaultysID à la communauté open source. Cette décision intervient après un audit de sécurité mené par Amossys, entreprise agréée par l’Anssi.
Depuis mars 2025, le code source de VaultysID, solution d’identification auto-souveraine développée par Vaultys, est disponible en open source. Ce choix stratégique s’inscrit dans une volonté de renforcer la transparence, la collaboration et la sécurité autour de l’identité numérique, à un moment où les questions de souveraineté numérique et de gestion des données personnelles occupent une place croissante dans les débats publics et professionnels. VaultysID repose sur un protocole d’authentification sans mot de passe, basé sur des mécanismes de chiffrement décentralisé. La solution permet aux utilisateurs et aux entreprises de gérer leur identité numérique de manière indépendante, sans avoir recours à des intermédiaires centralisés. Elle vise également à offrir un niveau d’authentification fort, en s’appuyant sur des standards reconnus au niveau international. Afin d’apporter des garanties de sécurité sur le protocole, Vaultys a sollicité un audit externe de la part d’Amossys, filiale du groupe Almond. L’entreprise est notamment certifiée Cesti (Centre d’Évaluation de la Sécurité des Technologies de l’Information) et qualifiée Passi RGS–LPM par l’Anssi. L’audit réalisé par Amossys a porté sur la robustesse du protocole d’authentification, sans que le communiqué de presse publié par l’éditeur ne fasse état de vulnérabilités majeures identifiées. Le rapport complet de cet audit est mis à disposition sur les sites web de Vaultys et d’Amossys, une initiative saluée pour sa transparence.
De l’open source pour afficher sa fiabilité
Selon François-Xavier Thoorens, co-fondateur et CEO de Vaultys, cette publication représente un engagement fort en faveur de la cybersécurité : « La publication en open source de notre solution marque une étape clé dans notre engagement pour un Internet plus sûr et respectueux de la vie privée. […] L’audit réalisé par Amossys garantit un haut niveau de sécurité et de fiabilité et renforce la confiance de l’écosystème. » VaultysID ambitionne également de fédérer une communauté technique autour de son développement. En publiant son code sur la plateforme GitHub, l’entreprise espère favoriser les contributions de développeurs, chercheurs et experts en cybersécurité. Cette ouverture vise à créer un environnement collaboratif pour améliorer de manière continue la sécurité, l’interopérabilité et l’adaptabilité de la solution.
En ouvrant VaultysID à la communauté open source, Vaultys opère un changement notable dans sa politique de développement, tout en mettant en avant la fiabilité de son protocole grâce à un audit indépendant. Cette démarche s’inscrit dans un mouvement plus large de renforcement de l’autonomie numérique et de sécurisation des systèmes d’authentification, dans un contexte où la cybersécurité reste un enjeu structurant pour les entreprises comme pour les citoyens.A propos de VaultysCréée en 2022 par Jean Williamson et François-Xavier Thoorens, Vaultys développe des solutions d’authentification issues des technologies du Web 3, dans une logique de renforcement de la protection des données personnelles et de simplification des processus d’accès aux systèmes d’information. La société cible principalement les entreprises et organisations publiques souhaitant intégrer des solutions souveraines et résilientes face aux cybermenaces croissantes.
Une dernière mise à jour de sécurité pour Chrome comble une vulnérabilité déjà exploitée par des pirates. Google a annoncé la disponibilité du patch pour les systèmes Windows mais pas encore pour d’autres systèmes d’exploitation.
Google a publié la version 134.0.6998.177/178 de Chrome pour Windows qui corrige une faille de sécurité déjà exploitée par des acteurs malveillants. Il est probable que les fabricants d’autres navigateurs basés sur Chromium suivent rapidement tandis que les mises à jour de Chrome pour macOS, Linux et Android n’ont pas encore été annoncées. Dans le billet de blog, la responsable du programme technique pour Chrome Srinivas Sista indique que cette faille référencée en tant que CVE-2025-2783 (score CVSS 8,3) a été découverte par des chercheurs en sécurité de Kaspersky qui l’ont signalée à la firme de Mountain View.
Celle-ci considère ce trou de sécurité comme présentant un risque élevé. Il s’agit d’un bogue exploitable dans Mojo sur Windows qui se produit dans des circonstances non spécifiées. Mojo fait référence à une collection de bibliothèques d’exécution fournissant un mécanisme indépendant de communication inter-processus (IPC). La vulnérabilité a été signalée à Google le 20 mars par Boris Larin et Igor Kuznetsov, experts en sécurité chez Kaspersky.
Des mises à jour de sécurité pour Brave Vivaldi et Microsoft Edge attendues
Il y a une semaine, Google a publié une mise à jour de sécurité pour Chrome qui a comblé deux autres failles. En général, Chrome se met à jour automatiquement lorsqu’une récente version est disponible. Vous pouvez déclencher manuellement l’actualisation en vous rendant dans le menu Aide > À propos de Google Chrome. A noter que le fournisseur prévoit de publier Chrome 135 au cours de la semaine prochaine.
Les éditeurs d’autres navigateurs basés sur Chromium – le moteur de Chrome – sont désormais tenus d’incrémenter ces mises à jour. Brave, Vivaldi et Microsoft Edge devraient ainsi être actualisés dans le courant de la semaine.