





Plusieurs vulnérabilités dans Ingress Nginx Controller ouvrent la voie à de l’injection de configurations et d’exécution de codes malveillants dans des clusters Kubernetes. Avec pour conséquence d’exposer tous leurs secrets et de les rendre vulnérables à une prise de contrôle.
Le projet Kubernetes (de la CNCF) a publié des correctifs pour cinq vulnérabilités dans un composant populaire largement utilisé Ingress Nginx Controller servant à acheminer le trafic externe vers les services Kubernetes. Si elle est exploitée, un des failles pourraient permettre à des attaquants de prendre complètement le contrôle de clusters de conteneurs entiers. « Sur la base de notre analyse, environ 43 % des environnements cloud sont vulnérables, nos recherches ayant permis de découvrir plus de 6 500 clusters, y compris des entreprises du Fortune 500, qui exposent publiquement les contrôleurs Kubernetes Ingress à l’Internet public – ce qui leur fait courir un risque critique immédiat », écrivent les chercheurs de la société de sécurité cloud Wiz – racheté par Google 32 Md$ – qui ont trouvé et signalé les failles. Collectivement baptisées IngressNightmare par l’équipe de recherche, ces brèches sont répertoriées en tant que CVE-2025-1097, CVE-2025-1098, CVE-2025-24514 et CVE-2025-1974. Elles ont été corrigées dans les versions 1.12.1 et 1.11.5 d’Ingress Nginx Controller (Ingress-Nginx) publiées lundi. Une cinquième faille, répertoriée sous le nom de CVE-2025-24513, a également été identifiée et corrigée dans les mêmes versions.
Un risque d’injection de configuration non authentifiée
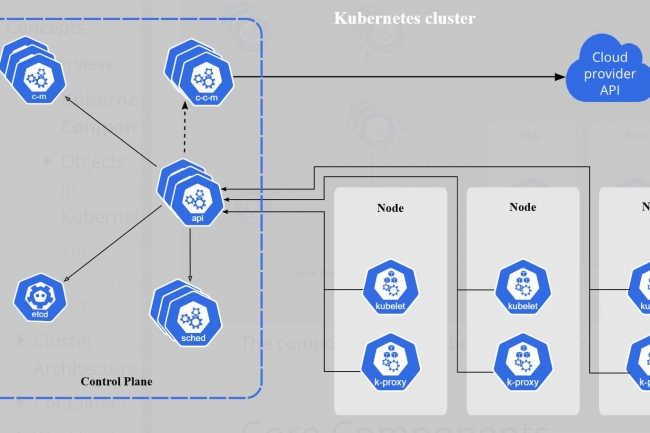
L’une des fonctions de Kubernetes exposant les charges de travail à l’internet est appelée ingress et permet aux administrateurs d’acheminer le trafic entrant vers différents services sur la base de règles définies via l’API de Kubernetes. Il existe de nombreux contrôleurs d’ingress, mais Ingress-Nginx, qui s’appuie sur le serveur web et le proxy inverse Nginx, est l’un des plus populaires et est couramment utilisé comme exemple dans la documentation officielle. Selon Wiz, plus de 41 % des clusters Kubernetes ouverts sur Internet utilisent Ingress-Nginx.
Le contrôleur Ingress-Nginx sert à traiter les objets entrants, créer des configurations Nginx correspondantes basées sur ces objets, puis les valider et les utiliser pour décider comment et où acheminer les requêtes. Les failles découvertes par Wiz donnent à un attaquant la capacité d’injecter des paramètres de configuration qui, une fois validés, entraînent l’exécution d’un code arbitraire par le validateur Nginx. « Le traitement approprié de ces paramètres de configuration Nginx est crucial, car Ingress-Nginx doit proposer aux utilisateurs une flexibilité significative tout en les empêchant de tromper accidentellement ou intentionnellement Nginx pour qu’il fasse des choses qu’il ne devrait pas faire », a déclaré l’équipe Kubernetes dans un billet de blog. Le problème est que le pod Ingress-Nginx dispose de privilèges élevés et d’une accessibilité illimitée au réseau. Plus important encore, il a accès à tous les secrets du cluster par défaut, ce qui signifie qu’un attaquant réussissant à exécuter du code dans ce pod peut dérober ces secrets et prendre le contrôle de l’ensemble du cluster.
La vulnérabilité CVE-2025-1974 est la plus grave et affiche un score CVSS de 9,8. Elle propose à toute personne ayant accès au réseau Pod d’exploiter les autres vulnérabilités d’injection de configuration, qui nécessiteraient autrement des actions privilégiées pour être exploitées. « Combinée aux autres trous de sécurité d’aujourd’hui, la CVE-2025-1974 signifie que n’importe qui sur le réseau Pod a de bonnes chances de prendre le contrôle de votre cluster Kubernetes, sans avoir besoin d’informations d’identification ou d’accès administratif », ont averti les responsables de Kubernetes. « Dans de nombreux scénarios courants, le réseau Pod est accessible à toutes les charges de travail dans votre VPC, ou même à toute personne connectée à votre réseau d’entreprise ! C’est une situation très grave. »
Deux façons d’atténuer les faiblesses
En termes de remédiation, la meilleure solution consiste à mettre à jour le composant Ingress-Nginx vers l’une des versions corrigées. Les administrateurs peuvent déterminer s’il est utilisé dans leurs clusters en tapant : kubectl get pods -all-namespaces -selector app.kubernetes.io/name=ingress-Nginx Dans les situations où une mise à niveau immédiate de la version n’est pas possible, les administrateurs peuvent réduire les risques en supprimant la configuration ValidatingWebhookConfiguration appelée ingress-Nginx-admission et en supprimant l’argument -validating-webhook du Deployment ou DaemonSet du conteneur ingress-Nginx-controller. Si ingress-Nginx a été installé à l’aide de Helm, il peut être réinstallé avec controller.admissionWebhooks.enabled=false. Cela atténuera CVE-2025-1974 en particulier, ce qui rend beaucoup plus facile l’exploitation des autres vulnérabilités sans authentification. Cependant, le contrôleur de validation ne devrait pas rester désactivé pendant une longue période car il fournit des garanties contre les mauvaises configurations d’entrée pour les utilisateurs légitimes.
Quelques mois après l’acquisition des activités de protection des données de Veritas, Cohesity publie NetBackup 11.0, une mise à jour axée sur la cybersécurité, l’analyse des comportements utilisateurs et l’élargissement des charges de travail cloud prises en charge.
Suite au rachat d’une partie de l’entité sauvegarde de Veritas, Cohesity a annoncé la disponibilité mondiale de NetBackup 11.0. Cette mise à jour comprend plusieurs fonctionnalités destinées à renforcer la sécurité des données dans des environnements hybrides et multicloud. NetBackup 11.0 introduit notamment un chiffrement conçu pour résister aux attaques associées aux futurs ordinateurs quantiques, un renforcement des outils de surveillance des comportements utilisateurs, un système de notation du risque amélioré, ainsi qu’un support élargi des environnements cloud. Selon Vasu Murthy, vice-président senior et directeur produit de Cohesity, « ce lancement représente la version la plus puissante de NetBackup jamais développée pour se défendre contre les menaces sophistiquées actuelles et se préparer à celles à venir ». Anticiper le déchiffrement quantiqueLa fonctionnalité de chiffrement quantum-proof vise à limiter l’exposition à la menace dite du “harvest now, decrypt later, en assurant la confidentialité des données à long terme. Elle couvre l’ensemble des canaux de communication de NetBackup, incluant les données en transit, la déduplication côté serveur et côté client. La surveillance des comportements utilisateurs est également étendue à un spectre plus large d’activités inhabituelles. Cette capacité peut ralentir ou stopper une attaque en cours, même si des identifiants administrateurs ont été compromis. Cette approche permet d’agir en amont de la compromission effective des systèmes. NetBackup 11.0 propose aussi un renforcement du scoring de risque, avec des paramètres de sécurité optimisés automatiquement, et la mise en oeuvre d’une authentification multifacteur lors de tentatives de modification de configurations jugées suspectes. Sur le plan du cloud, Cohesity annonce un support élargi des charges de travail PaaS, désormais étendu à Yugabyte, Amazon DocumentDB et Neptune, Azure Cosmos DB (Cassandra et Table API), Amazon RDS Custom for SQL Server, Oracle Snapshots, ainsi qu’à des outils de développement et de versioning comme Azure DevOps, GitHub et GitLab. Par ailleurs, la version 11.0 permet la réplication d’images et la reprise après sinistre à partir de couches d’archivage cloud telles qu’Amazon S3 Glacier et Azure Archive. Selon l’entreprise, NetBackup est reconnu par l’organisme Sheltered Harbor, ce qui atteste de sa conformité aux normes de cybersécurité les plus strictes, notamment celles appliquées dans le secteur financier américain. M. Murthy précise que « les dernières fonctionnalités de NetBackup offrent à nos clients des moyens plus intelligents de réduire l’impact des attaques, maintenant et à l’ère post-quantique ».
Dévoilée en septembre dernier, une faille critique dans l’utilitaire Smart Licensing de Cisco intéresse toujours les cybercriminels. Des activités récentes ont été découvertes par le SANS Technology Institute et recommande de corriger rapidement l’outil.
Pour les entreprises qui n’auraient pas corriger l’outil Smart Licensing Utility de Cisco (CSLU), il est urgent de le faire, souligne l’organisme de formation SANS Technology Institute. Les failles ont été découvertes en septembre dernier. CSLU est surtout utilisé dans les petits réseaux sur site et dans les réseaux isolés (air gap) pour gérer les licences Cisco sans avoir à recourir au Smart Licensing, plus complexe, basé sur le cloud. Selon une alerte lancée le 19 mars par Johannes Ullrich, doyen de la recherche, le SANS a détecté « quelques activités d’exploitation » ciblant ces failles, rendues publiques pour la première fois par Cisco en septembre dernier.
Ce n’est pas très surprenant : quelques semaines seulement après la publication des vulnérabilités, Nicholas Starke, chercheur en menaces chez Aruba, a procédé à une rétro-ingénierie de la première des failles, une porte dérobée non documentée accessible à l’aide d’un mot de passe faible codé en dur. « SANS a détecté le déploiement de ce mot de passe dans des appels récents à travers l’API », a déclaré Johannes Ullrich. Le fait que, dans son avis, Cisco a inévitablement indiqué à tout le monde ce qu’il fallait rechercher n’a pas arrangé les choses. « Cette vulnérabilité est due à un identifiant statique non documenté pour un compte d’administration. » Pour les pirates (et les chercheurs), il serait trop tentant de passer à côté. Trouver et exploiter des portes dérobées est presque un sport dans certains milieux. Normalement, les avis sont rédigés de façon à ce que les descriptions soient aussi génériques et peu détaillées que possible, mais malheureusement, il s’agit d’un exemple où rien n’a été simple.
Le secret de la porte dérobée
La faille du mot de passe codé en dur, référencée CVE-2024-20439, pouvait être exploitée pour obtenir des privilèges d’administrateur via l’API de l’application. La seconde faille, référencée CVE-2024-20440, pourrait offrir à un attaquant d’obtenir des fichiers logs contenant des données sensibles comme des identifiants d’API. Les deux failles ayant reçu un score CVSS identique de 9,8, on peut se demander laquelle est la plus grave des deux. Cependant, les vulnérabilités pourraient clairement être utilisées ensemble d’une manière qui amplifie leur danger, ce qui rend l’application de correctifs encore plus impérative.
Les versions 2.0.0, 2.1.0 et 2.2.0 de CSLU sont affectées. La version 2.3.0 est la version corrigée. Le produit CSLU étant récent, on aurait pu s’attendre à ce qu’il soit mieux sécurisé. Cela dit, Cisco a déjà connu ce type de faille : des identifiants codés en dur avaient été découverts dans Cisco Firepower Threat Defense, Emergency Responder et, plus anciennement, dans Digital Network Architecture (DNA) Center, pour ne citer que quelques-uns des produits concernés. Comme l’écrit M. Ullrich du SANS de manière plutôt sarcastique dans la dernière mise en garde de l’organisme : « La première faille référencée CVE-2024-20439 est tout à fait le genre de portes dérobées que Cisco aime introduire dans ses produits. »
La Cisa a lancé une alerte concernant une faille critique dans la solution de sauvegarde de Nakivo. Elle est activement exploitée par les cyberpirates.
Les cybercriminels apprécient particulièrement les vulnérabilités concernant les éditeurs de sauvegarde. On comprend pourquoi la Cisa (équivalent américain de l’Anssi) vient de lancer un avertissement sur une faille critique touchant la solution Backup & Replication de Nakivo. Répertoriée CVE-2024-48248 et un score de gravité de CVSS 8.6, elle entraîne une traversée de répertoire. « Cette vulnérabilité permet aux attaquants de lire des fichiers arbitraires sur le système affecté sans authentification », a déclaré le spécialiste américain de la sauvegarde des VM et des environnements SaaS dans l’avis de sécurité. « L’exploitation de cette vulnérabilité pourrait exposer des données sensibles, y compris des fichiers de configuration, des sauvegardes et des informations d’identification, ce qui pourrait conduire à des violations de données ou à d’autres compromissions de la sécurité » poursuit le fournisseur.
La vulnérabilité a été identifiée pour la première fois et portée à la connaissance de Nakivo par la société de cybersécurité WatchTowr le 13 septembre 2024. Il a fallu plus d’un mois à l’éditeur pour reconnaître la découverte. En conformité avec sa politique de diffusion, WatchTowr a publié des détail sur la faille, ainsi qu’un prototype d’exploit en février 2025.
Une diffusion d’un PoC d’exploit face au mutisme de Nakivo
Dans son alerte, la Cisa a expliqué que la brèche de sécurité était activement exploitée. Il est difficile de dire néanmoins si la publication du PoC par WatchTwr a facilité les campagnes d’attaques. La société était consciente du problème lors de la diffusion de son exploit. Il indique dans un blog « face à une vulnérabilité aussi « simple », il est parfois difficile de croire que nous sommes les seuls à être tombés dessus ».
Dans le viseur, la stratégie de Nakivo qui a eu déjà du mal à répondre aux sollicitations de WatchTwr. « Nous supposons bien sûr qu’ils ont contacté tous leurs clients sous NDA [ ndlr : clause de confidentialité] et qu’ils les ont encouragés à patcher discrètement, afin d’éviter de laisser leurs clients vulnérables à leur insu », glisse le fournisseur de cybersécurité. La vulnérabilité n’est pas sans rappeler celle découverte récemment chez Veeam dans son outil nommé également Backup & Replication.
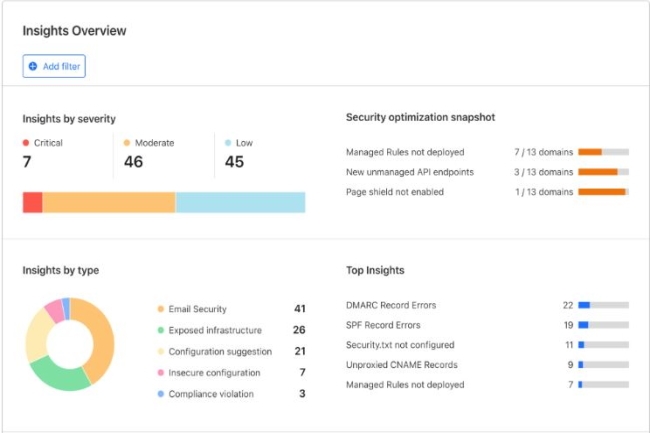
En utilisant la découverte basée sur le réseau, Cloudflare entre dans l’arène de la gestion de la posture de sécurité cloud.
Si ces dernières années, Cloudflare a régulièrement élargi son portefeuille de services de sécurité, une chose lui manquait encore : la gestion de la posture de sécurité dans le cloud (Cloud Security Posture Management, CSPM). Cette catégorie d’outils de sécurité permet aux entreprises de mieux comprendre et de mieux évaluer l’état actuel de la sécurité des applications et de l’infrastructure dans le cloud. Ce n’est plus le cas depuis le lancement, hier, de l’offre Cloudflare Security Posture Management qui aidera les équipes de sécurité à découvrir des actifs dont elles n’ont peut-être même pas connaissance, notamment des applications cloud, des points d’extrémité d’API et même des services alimentés par l’IA. Celle-ci comporte également un tableau de bord unifié avec un aperçu des actifs connus, pour que les entreprises puissent à la fois prioriser et remédier aux risques identifiés.Parmi les principales fonctionnalités de la solution, on peut citer :- La découverte et l’inventaire des actifs en temps réel à travers les applications SaaS et web.- Un tableau de bord unifié qui offre une visibilité sur l’ensemble des actifs technologiques.- La détection continue des menaces et l’évaluation des risques en fonction des actifs.- La protection des applications SaaS contenant des informations sensibles.- La gestion de la posture API avec sept nouvelles analyses de risque.- L’intégration de la gestion de la posture de sécurité du courrier électronique.« La magie de cette solution réside dans le fait qu’un client adhère à CloudFlare, qu’il commence à proxyser le trafic vers notre réseau et qu’à l’intérieur de ce trafic, nous pouvons découvrir les menaces qui pèsent sur lui », a expliqué Michael Tremante, directeur principal des produits chez Cloudflare, lors d’une interview exclusive.Une approche de la gestion de la posture axée sur le réseauLa solution de gestion de la posture de sécurité de Cloudflare fonctionne de manière tout à fait différente des outils traditionnels qui nécessitent généralement des agents installés sur les points finaux ou des connexions API dans les environnements cloud. Son approche basée sur le réseau permet deux voies de découverte distinctes : soit par des services de reverse proxy qui protègent les applications cloud orientées vers le public, soit par l’intermédiaire de capacités de proxy direct via Cloudflare Zero Trust pour le trafic des employés.Lorsque le trafic passe par le réseau de Cloudflare, aussi bien des requêtes entrantes vers les applications d’une entreprise ou un trafic sortant des employés, la plateforme effectue une inspection approfondie des paquets après décryptage. Le système classe automatiquement les actifs découverts, en identifiant les points de terminaison des API, les pages de connexion, les formulaires de paiement et même les services alimentés par l’IA, le tout sans nécessiter de configuration de la part des équipes de sécurité. « Notre proxy est un proxy de couche Layer 7 complet, et notre solution décrypte et recrypte à la périphérie de tout », a indiqué M. Tremante. Pour le trafic des employés, le mécanisme de découverte fonctionne par le biais de la résolution DNS ou de capacités de proxy complètes. « Une fois que le trafic est acheminé par proxy, nous ne faisons pas de différence entre l’utilisateur et l’autre extrémité de la connexion », a-t-il ajouté. « Il peut s’agir d’une application SaaS, d’une application interne personnalisée, du moment qu’elle utilise les protocoles que nous comprenons ».Une gestion de la posture de sécurité contrôlée par le réseauLa gestion de la sécurité des applications SaaS peut s’avérer particulièrement complexe. La plupart des fournisseurs de SaaS ont déjà intégré divers contrôles d’accès et de sécurité, mais il reste encore beaucoup à faire au niveau du réseau. M. Tremante fait remarquer que, par exemple, si une entreprise utilise Microsoft 365, une série de contrôles spécifiques dans le tableau de bord fourni sont plus spécifiques à cet environnement. « Si l’on fait partie d’une équipe de sécurité et que l’on veut s’assurer que seul un sous-ensemble de ses employés accède à Outlook ou à Microsoft 365, et qu’aucun contenu allant vers Outlook n’est malveillant, il est possible de le bloquer en amont avant même qu’il n’atteigne le service Outlook, le réseau a une longueur d’avance, car notre proxy Layer 7 est complet », a-t-il justifié.Se préparer à la conformité PCI DSS 4.0 La plateforme répond également aux exigences de conformité en identifiant automatiquement les problèmes potentiels. La gestion de la posture de sécurité est particulièrement importante pour la conformité réglementaire. L’une des préoccupations auxquelles de nombreuses entreprises seront confrontées ce mois-ci est la conformité à la version 4.0 de la norme PCI DSS (Payment Security Industry-Data Security Standard), qui entrera en vigueur le 31 mars. « Dans le cadre de la gestion de la posture de sécurité, nous découvrons désormais toutes les ressources web externes chargées dans les applications web », a fait valoir Michael Tremante. Cette capacité est un élément clé de la conformité à la norme PCI DSS 4.0.Vers une gestion complète de la posture de sécuritéIl est important de noter que la technologie Cloudflare Security Posture Management n’est pas encore un CSPM complet, car elle se limite à la découverte des actifs déjà protégés par le réseau de Cloudflare. Pour l’avenir, l’entreprise a déjà des projets d’expansion. « Il s’agit de la première étape, et nous nous dirigeons résolument vers la gestion complète de la posture sécurisée », a révélé M. Tremante. « Nous prévoyons de commencer un balayage actif des actifs, même s’ils ne sont pas encore intégrés au réseau de Cloudflare. » Cette capacité permettrait à Cloudflare de se positionner plus directement face aux fournisseurs traditionnels de gestion de la posture de sécurité, tout en conservant son approche centrée sur le réseau comme élément clé de différenciation. « Parfois, les clients pensent qu’ils sont totalement intégrés à Cloudflare, alors qu’ils ont parfois un autre réseau quelque part qu’ils ont complètement oublié », a ajouté M. Tremante.
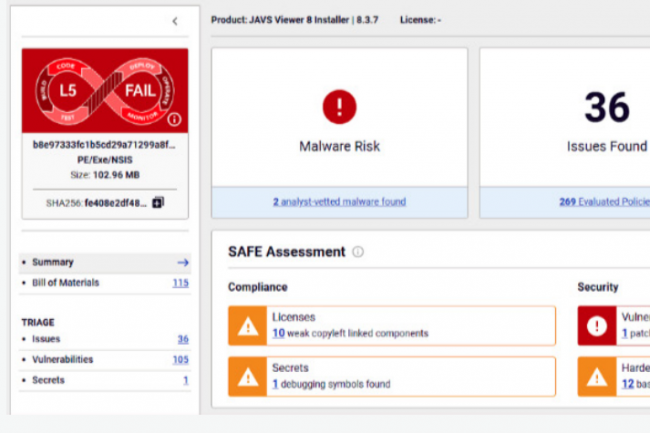
En 2024, les pirates ont multiplié les attaques et les exploits de failles dans les binaires de logiciels et applications du marché y compris celles d’intelligence artificielle. Les attaques contre la supply chain logicielle sont devenues particulièrement sophistiquées.
La multiplicité des failles dans les logiciels open source et les logiciels commerciaux tiers, ainsi que les campagnes malveillantes ciblant les pipelines de développement de l’IA, exacerbent les problèmes de sécurité de la supply chain logicielle. Selon ReversingLabs (RL), les incidents liés à l’exposition de secrets intégrés à des développements via de composants open source librement accessibles ont augmenté de 12 % l’année dernière par rapport à 2023.Une analyse de 30 logiciels libres parmi les plus populaires laisse apparaître une moyenne de six failles de gravité critique et de 33 failles de gravité élevée… pour chacun d’entre eux. Les progiciels propriétaires sont également une source fréquente de risques, selon d’autres conclusions du rapport de ReversingLabs sur la sécurité de la supply chain logicielle.Les risques liés à celle-ci sont devenus de plus en plus fréquents et complexes, car les environnements informatiques modernes reposent largement sur des fournisseurs et des composants open source. Le problème a pris de l’ampleur après le piratage de SolarWinds en 2020, qui a touché plus de 30 000 organisations, y compris des agences gouvernementales américaines.De nombreux incidents résultant d’attaques contre la supply chain logicielle – qu’elle que soit la forme qu’elle prenne – se sont produits depuis le piratage historique de SolarWinds Orion, attribué à une unité du Service de renseignement extérieur de Russie.Sous le microscopeL’analyse par RL de plus de deux douzaines de binaires de logiciels propriétaires largement utilisés – y compris des OS, des gestionnaires de mots de passe, des navigateurs web et des logiciels de réseaux privés virtuels (VPN) – montre la persistance de toute une série de problèmes tels que des secrets exposés, la présence de vulnérabilités logicielles activement exploitées, des preuves d’altération possible du code et un durcissement inadéquat des applications.Mais, selon RL, ce sont les modules open source et les référentiels de code qui représentent toujours la grande majorité des risques liés à la chaîne d’approvisionnement en 2024. L’analyse de packages populaires comme npm, PyPI et RubyGems montre que de nombreux modules open source largement utilisés contiennent des composants anciens et obsolètes – un phénomène connu sous le nom de « code rot » (pourriture de code). Par exemple, de npm, module comptant près de 3 000 téléchargements hebdomadaires et 16 applications dépendantes, a permis d’identifier 164 vulnérabilités de code distinctes, dont 43 de gravité « critique » et 81 de gravité « élevée ». La même analyse identifie sept vulnérabilités logicielles connues pour avoir été activement exploitées par des acteurs de la menace.L’IA : nouvelle frontière pour les attaques par la supply chainL’étude révèle également que les campagnes ciblant la supply chain logicielle visent désormais l’infrastructure de développement et le code utilisé par les développeurs d’applications de Machine Learning et d’IA. Par exemple, les chercheurs de RL ont découvert une technique malveillante baptisée « nullifAI », au sein de laquelle un code malveillant est placé dans les fichiers de sérialisation Pickle de Python. Cette technique a échappé aux protections intégrées dans la plateforme open source Hugging Face – un ensemble de ressources populaire pour les développeurs d’IA et de ML.« Les chaînes d’approvisionnement en IA sont une cible de plus en plus importante, les attaquants manipulant les données, les modèles d’entraînement et les bibliothèques logicielles », souligne Michael Adjei, directeur de l’ingénierie des systèmes chez l’éditeur de solutions de micro-segmentation Illumio. « De nombreuses organisations s’appuient sur des services tiers pour les modèles pré-entraînés et les outils basés sur le cloud, mais des ressources non sécurisées peuvent introduire des portes dérobées et des vulnérabilités. » Selon lui, « pour protéger la supply chain de l’IA, les couches cachées secrètes des modèles devraient être exposées à des tests de pénétration et à des entraînements contradictoires (adversarial training, consistant à réentraîner un modèle sur des examples permettant d’en dégrader la fiabilité, NDLR). »Peter Garraghan, CEO de Mindgard, fournisseur de tests de sécurité pour l’IA et professeur à l’université britannique de Lancaster, reconnaît que les menaces pesant sur la supply chain constituent une préoccupation émergente pour les développeurs d’IA. « Les composants d’IA – par exemple, LLM, RAG – sont intégrés dans la chaîne d’approvisionnement en logiciels, ce qui en fait une nouvelle frontière pour les attaques sophistiquées », dit-il. « Comme le souligne l’OWASP (voir LLM 03:2025), les LLM s’intègrent fréquemment à des API externes et à des sources de données, ce qui introduit des risques importants en raison de ces dépendances. »Et encourager les pratiques de codage sécurisé ne suffit pas « Les RSSI doivent adopter une posture de sécurité proactive qui inclut des tests continus des applications d’IA, une transparence sur la structure des logiciels et la détection automatisée des menaces tout au long du cycle de vie du développement de l’IA », conseille Peter Garraghan.Code généré par l’IA : un faux sentiment de sécuritéLes chaînes d’approvisionnement en logiciels s’appuient fortement sur des codes open source, émanant de tiers et/ou générés par l’IA, ce qui introduit des risques échappant au contrôle des équipes de développement. De meilleurs contrôles sur les logiciels que l’industrie construit et déploie sont nécessaires, selon ReversingLabs.« Les outils AppSec traditionnels passent à côté de menaces telles que l’injection de malwares, la modification malveillante de dépendances et les failles cryptographiques », indique Saša Zdjelar, Chief trust officer de ReversingLabs. « La véritable sécurité exige une analyse approfondie des logiciels, une évaluation automatisée des risques et une vérification continue tout au long du cycle de développement. »Les développeurs et les équipes chargées de la sécurité des applications doivent avoir accès à des outils leur permettant de s’assurer que leurs composants fondamentaux sont exempts de vulnérabilités connues ou, pire encore, de malwares cachés ou de manipulations diverses.L’introduction de codes générés par l’IA ne résout pas ce problème. On a observé que les logiciels générés par l’IA reprenaient des codes présentant des vulnérabilités connues, remettaient au goût du jour des algorithmes de chiffrement obsolètes ou contenaient des composants open source périmés.ReversingLabs affirme qu’il est nécessaire de mettre en place une nouvelle génération de solutions pour la supply chain logicielle, conçues pour identifier les malwares et les manipulations, ainsi que les changements de comportement d’une application entre deux versions successives.Extension de la nomenclature logicielleReversingLabs et des experts indépendants estiment encore qu’il est temps d’adopter et d’étendre le concept de nomenclature des logiciels (SBOM, pour software bill of materials). Un SBOM fournit un inventaire complet des dépendances logicielles – des données qui aident les organisations à atténuer les risques de sécurité et à répondre rapidement aux vulnérabilités dans les bibliothèques et autres composants.« Actuellement, le SBOM est simplement une liste d’ingrédients et, peut-être, de vulnérabilités existantes, dit Saša Zdjelar de ReversingLabs. Les récents ajouts visant à prendre en compte une nomenclature étendue – aux composants de machine learning, cryptographiques et SaaS – constituent un grand pas dans la bonne direction. »Darren Meyer, du fournisseur de tests de sécurité des applications d’entreprise Checkmarx, souligne que les entreprises devaient développer des programmes complets basés sur les risques afin de maîtriser les menaces pesant sur leur supply chain logicielle. « Pour rester au fait des codes tiers vulnérables et malveillants, il faut disposer d’une chaîne d’outils complète, notamment de fonctions d’analyse de la composition des logiciels (SCA) pour identifier les vulnérabilités connues dans les composants logiciels tiers, d’une analyse des conteneurs pour détecter les failles dans les paquets issus de tiers au sein des conteneurs, et de renseignements sur la menace centrés sur les paquets malveillants afin de repérer les composants compromis », énumère Darren Meyer.David Spillane, directeur de l’ingénierie des systèmes chez le fournisseur de cybersécurité Fortinet, fait valoir que les RSSI ont un rôle clé à jouer dans l’atténuation des risques potentiels liés à la sécurité de la supply chain : « outre les pratiques de développement sécurisé, les RSSI et les équipes informatiques au sens large peuvent prendre plusieurs mesures pour atténuer les attaques contre la supply chain logicielle des entreprises, à commencer par l’audit de l’infrastructure existante, afin d’identifier les vulnérabilités dont les cybercriminels pourraient tirer parti. Il est essentiel de disposer d’un inventaire actualisé des actifs logiciels pour réduire les vecteurs d’attaque potentiels en classant les solutions en fonction de leur degré de sécurité. »
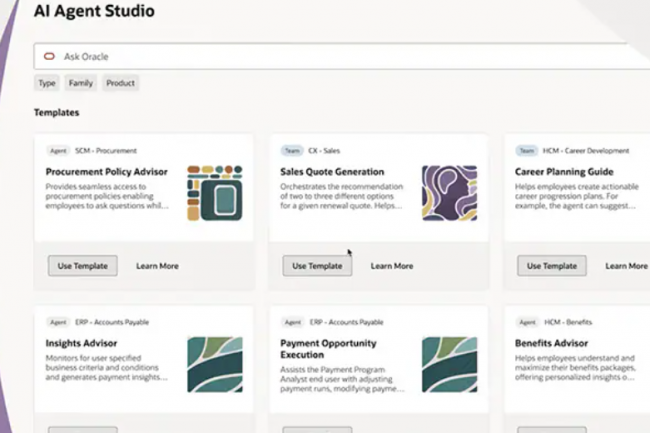
Pour automatiser plus efficacement les processus d’entreprise et réduire les traitements manuels sans nécessiter des coûts de développement trop élevés, Oracle lance AI Agent Studio dans Fusion Cloud Applications sans changement tarifaire. Mais plusieurs analystes remettent en cause l’aspect vraiment agentique de cette offre.
Oracle a annoncé ce jeudi AI Agent Studio pour Fusion Cloud Applications, une plateforme complète pour créer, étendre, déployer et gérer des agents (et des équipes d’agents) IA au sein des entreprises. « L’introduction d’AI Agent Studio reflète la nécessité pour chaque plateforme d’application d’entreprise majeure d’avoir son propre ensemble d’agents, car c’est devenu une nécessité en 2025 pour toute plateforme d’entreprise qui cherche à rester pertinente dans un marché…
Il vous reste 94% de l’article à lireVous devez posséder un compte pour poursuivre la lecture
Vous avez déjà un compte?
Une vulnérabilité critique ouvrant la voie à de l’exécution de code distant a été comblée par Veeam dans sa solution de sauvegarde et de réplication. Elle découle d’un correctif incomplet d’une autre faille critique plus ancienne exploitée par les opérateurs de ransomware Akira et Fog.
L’éditeur de solutions de résilience des données Veeam a publié un correctif pour son produit Backup & Replication touché par une faille critique (score CVSS de 9,9) référencée CVE-2025-23120. Le patch résout un problème de désérialisation qui peut entraîner l’exécution de code à distance en tant qu’utilisateur système sur le serveur Windows sous-jacent. La sérialisation est le processus de transformation des données en un flux d’octets pour la transmission à une autre application, et la désérialisation est l’inverse de ce processus. La désérialisation de données provenant de sources non fiables est à l’origine de nombreuses vulnérabilités liées à l’exécution de code à distance dans divers langages de programmation.
Ce défaut peut être exploité par n’importe quel compte authentifié faisant partie du groupe d’utilisateurs locaux sur l’hôte Windows. Cependant, les serveurs Veeam connectés à un domaine Active Directory sont beaucoup plus à risque, car dans les configurations par défaut, le groupe d’utilisateurs du domaine est ajouté celui en local sur les ordinateurs connectés au domaine. Cela signifie que si des attaquants parviennent à exécuter un code malveillant sur n’importe quel ordinateur Windows du réseau – ce qui est fréquent – ils peuvent facilement utiliser le compte actif de ce PC pour exploiter ce trou de sécurité sur le serveur Backup & Replication s’il est relié au même domaine AD. Bien que ce problème ait reçu un seul identifiant (CVE-2025-23120), les chercheurs de la société de sécurité watchTowr soutiennent qu’il s’agit en fait de deux vulnérabilités, car il y a deux voies distinctes pour exploiter le problème. Le fournisseur conseille aux clients de mettre à jour vers Backup & Replication 12.3.1 ou d’installer le hotfix pour la version 12.3 si une mise à jour ne peut pas être effectuée immédiatement. Ce dernier ne fonctionne que sur les déploiements qui n’ont pas eu d’autres patchs d’urgence appliqués précédemment.
Des listes noires de classe rarement complètes
Les problèmes de désérialisation découverts par watchTowr proviennent d’un correctif incomplet pour une faille plus ancienne patchée en 2024 en tant que CVE-2024-40711 qui a ensuite été signalée comme exploitée dans l’une des infections zero day des opérateurs de ransomware Akira et Fog. En fait, le produit Backup & Replication est ciblé à de multiples reprises depuis 2023 par des cybergangs.
Les développeurs d’applications ont pris l’habitude d’atténuer les risques liés à la désérialisation en créant des listes noires de classes qui pourraient être dangereuses lorsqu’elles sont désérialisées, et comme l’explique watchTowr, c’est également l’approche adoptée par Veeam lors de la résolution de la CVE-2024-40711. Cependant, l’histoire a montré que ces recensements sont rarement complets. « Les listes noires (également appelées listes de blocage ou listes de refus) sont basées sur l’idée très optimiste (et manifestement erronée) que nous pouvons simplement dresser une liste de toutes les mauvaises classes, que nous pouvons garder un enregistrement et la mettre à jour au fur et à mesure”, souligne l’éditeur de sécurité. Un monde idéal, mais ” c’est un mensonge. Bien que nous soyons d’accord sur le fait qu’il est aujourd’hui extrêmement difficile de trouver de nouveaux processus de désérialisation dans les langages de programmation et les frameworks (même si cela reste possible), les produits ont leur propre base de code et peuvent contenir des classes abusives qui peuvent servir à mauvais escient pendant la désérialisation. Et ce, avant même d’aborder les bibliothèques tierces. »
Des gadgets exploitables sources de risques
Les développeurs de Veeam Backup & Replication maintiennent une liste de gadgets [un gadget est une classe qui peut être utilisée comme un outil pour tirer parti du mécanisme de désérialisation, ndlr] qui sont bloqués pour être désérialisés via .NET BinaryFormatter. Cette liste est située dans le code à Veeam.Backup.Common.Sources.System.IO.BinaryFormatter.blacklist.txt. Ainsi, lorsque la CVE-2024-40711 a été découverte, leur solution a été d’ajouter le gadget System.Runtime.Remoting.ObjRef à ce document. Problème résolu, jusqu’à ce que le chercheur de watchTowr Sina Kheirkhah trouve d’autres classes exploitables, System.CodeDom.Compiler.TempFileCollection et System.IO.DirectoryInfo, résultant en la vulnérabilité CVE-2024-42455. Ces classes ont également été ajoutées à la liste d’exclusion.
Piotr Bazydlo, chercheur chez watchTowr, a trouvé d’autres gadgets exploitables : Veeam.Backup.EsxManager.xmlFrameworkDs et Veeam.Backup.Core.BackupSummary, qui étendent tous deux la classe DataSet, un gadget RCE très populaire pour la désérialisation. Il s’agit de la nouvelle faille CVE-2025-23120 patchée mercredi. En fait, l’exploitation de la CVE-2025-23120 ne nécessite que de simples modifications de l’exploit de preuve de concept publié précédemment pour la CVE-2024-42455. « Nous espérons avoir apporté une preuve supplémentaires que la protection des puits de désérialisation par une liste noire devrait être interdite », écrivent les chercheurs. « Peu importe à quel point votre liste est parfaite, perfectionnée et à la pointe de la technologie, quelqu’un finira par trouver un moyen de l’utiliser à mauvais escient. »
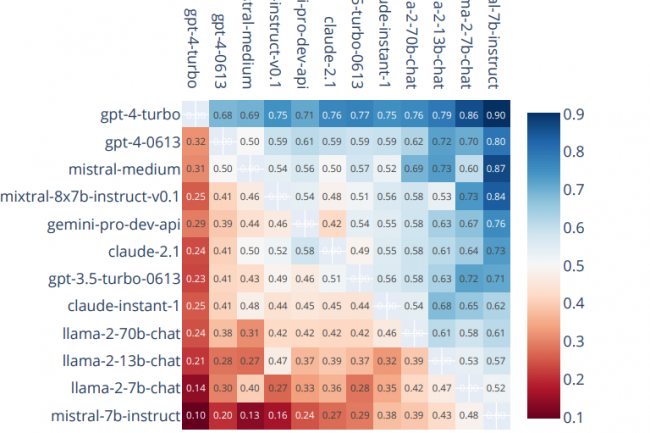
Avec le développement de grands modèles de langage de plus en plus nombreux, variés et spécifiques, il devient difficile pour les entreprises de se repérer. Elles peuvent cependant exploiter les benchmarks de LLM qui se développent eux-aussi en nombre, à condition de suivre certaines règles.
Les déploiements de l’IA générative en entreprise sont désormais pléthore. Et le marché propose un éventail de plus en plus large de LLM parmi lesquels il n’est pas simple de choisir en fonction de ses besoins. Une des réponses se trouve dans les benchmarks qui évaluent et classent les principaux modèles.Ces tests standardisés spécifiquement développés pour mesurer les performances des modèles de langage, évaluent non seulement le fonctionnement d’un modèle, mais aussi la qualité des tâches qu’il réalise. Ils mesurent et comparent des paramètres tels que la précision, la fiabilité et la capacité à s’exécuter efficacement dans la pratique. Qu’il s’agisse de sélectionner un chatbot pour le service client, de traduire des textes scientifiques ou de programmer un logiciel, les benchmarks apportent une première réponse à la question : ce modèle est-il adapté à mon cas d’usage ?Conserver un regard critiqueLes principales caractéristiques de ces benchmarks sont au nombre de trois. La polyvalence pour commencer. Les benchmarks mesurent en effet un large éventail de capacités des LLM, depuis la compréhension du langage jusqu’à la résolution de problèmes mathématiques ou au développement logiciel. La spécialisation ensuite, puisque certains benchmarks sont conçus pour se concentrer sur des domaines d’application précis, comme MultiMedQA dans le domaine médical, et pour évaluer l’adéquation d’un modèle dans des contextes sensibles ou très complexes. Enfin, ces benchmarks présentent quelques défis. Ils ont des limites telles que la potentielle data contamination (exploitation de données incorrectes), un degré d’obsolescence rapide et une capacité limitée à être étendus au-delà de leur cible initiale. Ce qui impose de conserver un regard critique lors de l’interprétation des résultats du comparatif.3 piliers : les datasets, l’évaluation et les classementsLe benchmarking de LLM repose sur trois piliers : les data sets, les méthodes d’évaluation et les classements. Les data sets, collections de tâches et de scénarios spécifiquement développés pour tester les capacités des modèles de langage, constituent la base des tests. Ils définissent les défis qu’un modèle doit surmonter. Leur qualité et leur variété sont essentielles pour garantir la valeur d’un benchmark. Mieux, ils simulent des applications du monde réel, plus les résultats sont utiles et significatifs. Squad (Stanford question responding dataset), par exemple, fournit des passages de texte et des questions associées pour tester la capacité d’un modèle à extraire des informations pertinentes de certains passages.Deuxième pilier d’un benchmark, les méthodes d’évaluation. Il existe trois approches principales. Avec la première, le benchmark compare la réponse générée par un modèle avec un texte de référence idéal. Un exemple classique est Bleu, qui évalue dans quelle mesure les séquences de mots de la réponse générée correspondent à celles du texte de référence. Bertscore va encore plus loin, en évaluant non seulement les correspondances de mots, mais en analysant aussi la similarité sémantique. Ceci est particulièrement utile lorsque le sens est plus important que l’exactitude littérale.Les LLM, juges de LLMLa deuxième méthode d’évaluation évalue la qualité d’un texte généré indépendamment de toute référence. Le test analyse la cohérence, la logique et l’exhaustivité de la réponse par elle-même. Un modèle pourrait, par exemple, résumer le texte source : « Le changement climatique est l’un des problèmes les plus urgents de notre époque. Il est causé par l’augmentation des gaz à effet de serre tels que le CO₂, qui proviennent principalement de la combustion de combustibles fossiles » par « Le changement climatique est causé par les émissions de CO₂ ». Dans ce cas, une évaluation sans référence vérifiera si ce résumé reflète correctement le contenu essentiel et reste logique en soi.Enfin, le LLM-as-a-Judge – AI as an educator est une approche innovante qui consiste à utiliser les modèles eux-mêmes comme leurs propres juges. Ces modèles analysent à la fois leurs propres réponses et celles des autres et les évaluent sur la base de critères prédéfinis. Cette approche ouvre de nouvelles possibilités qui vont au-delà des mesures classiques. Mais la méthode n’est pas sans défauts. Une étude a, par exemple, montré que les modèles ont tendance à reconnaître leurs propres réponses et à les évaluer plus favorablement que les autres. De tels biais nécessitent des mécanismes de contrôle supplémentaires pour garantir l’objectivité. La recherche dans ce domaine n’en est qu’à ses balbutiements, mais le potentiel d’obtention d’évaluations plus précises et nuancées reste important.Enfin, 3e et dernier pilier d’un benchmark de LLM, les classements. Ce sont eux qui rendent les résultats transparents et comparables. Ils fournissent un aperçu précieux des résultats de référence. Ils rendent les performances des différents modèles comparables en un coup d’oeil et favorisent ainsi la transparence. Des plateformes comme Hugging Face ou Papers with Code sont de bons points de départ. Mais attention : une position en tête d’un classement ne doit pas être confondue avec une supériorité universelle. Le choix du bon modèle doit toujours se faire en fonction des besoins individuels d’un projet.Les benchmarks LLM les plus courantsAvec chaque avancée sur le marché des LLM, de nouveaux tests sont créés pour répondre aux demandes croissantes. En règle générale, les benchmarks sont conçus pour des tâches spécifiques telles que la pensée logique, la résolution de problèmes mathématiques ou la programmation. Quelques benchmarks bien connus sont présentés ci-dessous, en fonction des thématiques suivantes : 1) Raisonnement et compréhension du langage- MMLU (Massive multitask language understanding) teste l’étendue des connaissances d’un modèle dans 57 disciplines académiques et professionnelles. Avec près de 16 000 questions à choix multiples basées sur les programmes et les examens, des sujets tels que les mathématiques, la médecine et la philosophie sont couverts. Un accent particulier est mis sur le contenu complexe et spécifique à un sujet qui nécessite des connaissances avancées et un raisonnement logique.Article de recherche associé – Mesurer la compréhension d’un langage massivement multitâche.- Hellaswag évalue le « bon sens » d’un modèle en sélectionnant la phrase la plus plausible qui va suivre une autre phrase, parmi quatre options. Les tâches ont été conçues pour être faciles pour les humains, mais difficiles pour les modèles, ce qui rend ce benchmark particulièrement difficile.Article de recherche – Hellaswag : une machine peut-elle vraiment finir votre phrase ?- TruthfulQA évalue la capacité d’un modèle à fournir des réponses véridiques sans reproduire de malentendus ou de fausses hypothèses. Avec 817 questions dans 38 catégories, dont le droit et la santé, TruthfulQA est spécialement conçu pour identifier de la désinformation généralisée.Article de recherche – TruthfulQA : Mesurer la façon dont les modèles imitent les mensonges humains.2) Résolution de problèmes mathématiques- MATH comprend 12 500 problèmes mathématiques dans des domaines tels que l’algèbre, la géométrie et la théorie des nombres. Chacun est annoté avec une solution étape par étape qui permet une évaluation précise des capacités de résolution du modèle. Le benchmark teste ainsi la capacité de ce dernier à reconnaître les relations logiques et à fournir une précision mathématique.Article de recherche – Mesurer la résolution de problèmes mathématiques à l’aide de l’ensemble de données Math.3) Compétences en programmation- HumanEval propose 164 tâches de programmation Python avec des tests unitaires complets pour valider les solutions. Le benchmark teste la capacité d’un modèle à générer du code fonctionnel et logique à partir de descriptions en langage naturel.Article de recherche – Évaluation de LLM entraînés sur du code.4) Benchmarks spécifiques à un domaine- MultiMedQA combine six ensembles de données médicales, dont PubMedQA et MedQA, pour tester l’applicabilité des modèles dans des contextes médicaux. La variété des questions – des questions ouvertes aux QCM – fournit une analyse détaillée des capacités spécifiques au domaine.Article de recherche – Les grands modèles de langage encodent les connaissances cliniques.5) Benchmarks spécialisés- MT-Bench se concentre sur la capacité des LLM à fournir des réponses cohérentes dans des dialogues en plusieurs étapes. Avec près de 1400 dialogues couvrant des sujets tels que les mathématiques, l’écriture, les jeux de rôle et le raisonnement logique, le benchmark fournit une analyse complète des capacités de dialogue du modèle.Article de recherche – MT-Bench-101 : A Fine-Grained Benchmark for Evaluating Large Language Models in Multi-Turn Dialogues.- Chatbot Arena est une plateforme de comparaison directe entre modèles. Les utilisateurs peuvent tester des chatbots anonymes en évaluant leurs réponses en temps réel. Le système de classement Elo est ensuite utilisé pour créer un classement dynamique qui reflète les performances des modèles. L’indice de référence se distingue par son approche de crowdsourcing. Tout le monde peut contribuer à l’évaluation de la Chatbot Arena.Article de recherche – Chatbot Arena : une plateforme ouverte pour évaluer les LLM en fonction des préférence d’un humain.- SafetyBench est le premier benchmark complet à examiner les aspects de sécurité des LLM. Avec plus de 11 000 questions réparties en sept catégories, dont les préjugés, l’éthique, les risques potentiels et la robustesse, il fournit une analyse détaillée de la sécurité et de la sûreté des modèles.Article de recherche – SafetyBench : Évaluation de la sécurité des LLM.Les inévitables limites des benchmarksReste que les benchmarks ne sont pas des outils parfaits. Bien qu’ils fournissent des informations précieuses sur les capacités des LLM, leurs résultats doivent toujours être analysés avec un oeil critique. L’un des plus grands défis est ce que l’on appelle la contamination des données. Les benchmarks tirent leur validité de l’hypothèse que les modèles résolvent des tâches sans exposition préalable. Pourtant, les données d’entraînement d’un modèle contiennent souvent déjà des tâches ou des questions qui correspondent aux data sets. Ce qui peut, artificiellement, faire apparaître certains résultats comme meilleurs qu’ils ne le seraient dans la réalité et déformer les performances réelles d’un modèle.Qui plus est, le développement rapide des technologies d’IA rend de nombreux benchmarks rapidement obsolètes. Cela nécessite le développement continu de nouveaux tests plus exigeants pour évaluer de manière significative les capacités actuelles des modèles modernes.Un autre défaut des benchmarks réside dans la difficulté à les généraliser. Ils évaluent en général des fonctions spécifiques telles que la traduction ou la résolution de problèmes mathématiques. Mais un modèle qui fonctionne bien pour un benchmark donné n’est pas automatiquement adapté pour des scénarios réels et complexes dans lesquels plusieurs fonctions sont impliquées. Autrement dit, ces benchmarks sont très utiles, mais ne reflètent pas toute la réalité.Conseils pratiques pour votre prochain projetLes benchmarks sont plus que de simples tests, ils constituent la base de décisions éclairées lorsqu’il s’agit de choisir des LLM. Ils permettent d’analyser de façon exhaustive les forces et faiblesses d’un modèle, d’identifier les meilleures options pour des cas d’utilisation spécifiques et de minimiser les risques du projet. Il est intéressant de veiller aux éléments suivants pour une mise en pratique :- Définir des exigences claires : tout d’abord, il faut déterminer les compétences essentielles au projet spécifique choisi. En conséquence, des critères de référence sont sélectionnés pour répondre à ces exigences spécifiques.- Combiner plusieurs benchmarks : aucun benchmark ne peut évaluer toutes les fonctionnalités pertinentes d’un modèle. Une combinaison de différents tests permet d’obtenir une image différenciée des performances.- Sélectionner en fonction des priorités : la définition des priorités du projet permet de sélectionner les benchmarks qui auront le plus de poids dans la réussite du projet.- Compléter les benchmarks avec des tests pratiques : l’utilisation de tests avec des données réelles permet de s’assurer qu’un modèle répond aux exigences de l’application concernée.- Rester flexible : de nouveaux benchmarks sont développés en permanence pour mieux refléter les avancées récentes dans la recherche en IA. Mieux vaut se tenir à jour pour s’adapter si besoin.L’utilisation stratégique des benchmarks permet non seulement de choisir un meilleur modèle, mais aussi d’exploiter pleinement son potentiel d’innovation. Cependant, les benchmarks ne constituent bien entendu qu’une première étape avant l’intégration et l’adaptation des LLM dans des applications concrètes pour l’entreprise.
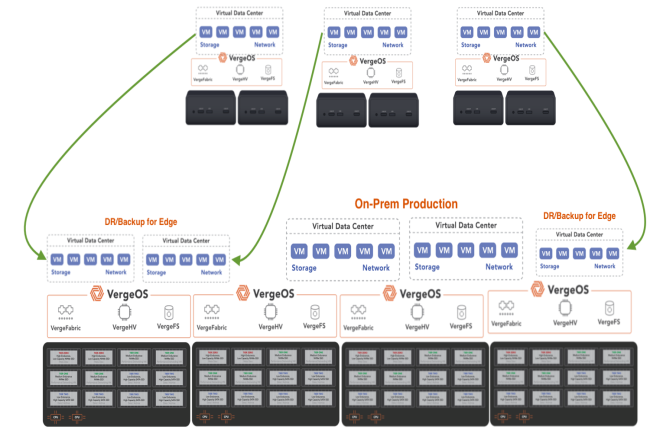
Avec son offre de virtualisation de réseau, VergeIO veut séduire les entreprises qui n’ont pas apprécié les changements apportés par Broadcom à VMware. Sa dernière version SDN VergeFabric comprend des fonctions plus avancées de routage BGP, de surveillance de la sécurité et de gestion du trafic.
VergeIO cherche à bousculer le marché de l’infrastructure virtuelle avec son approche de la virtualisation et du réseau SDN (Software-Defined Networking). L’entreprise fondée en 2010 n’est pas une startup, mais elle ne s’était pas encore faite beaucoup remarquer sur le marché. Sauf que depuis l’acquisition de VMware par Broadcom et les rumeurs de défections de clients VMware, la solution de VergeIO est apparue comme une alternative. Au coeur de son offre, la plateforme VergeOS propose une approche fondamentalement différente des solutions d’infrastructure virtuelle traditionnelles comme VMware. Au lieu de combiner des composants distincts comme un hyperviseur, un stockage et un réseau, VergeOS intègre toutes ces fonctions dans une base de code unique. VergeFabric est l’un de ces éléments intégrés. La semaine dernière, dans le cadre de la mise à jour de sa technologie VergeFabric, l’entreprise a ajouté plusieurs fonctionnalités avancées de mise en réseau au-delà de la commutation virtuelle de base. « Si l’on regarde la pile VMware, il y a évidemment ESXi, vSAN, NSX, le tout bricolé avec vCenter », a déclaré George Crump, directeur marketing de VergeIO. « Notre proposition est fondamentalement différente, car elle intègre tout ce code dans une base de code unique, resserrée et très efficace, de sorte que les fonctions de réseau, de stockage, de l’hyperviseur et, en option, celles de l’interface graphique, font toutes partie du même code. »Contenu et déploiements de VergeIOAlors que l’hyperviseur ESX est au coeur de la plateforme de virtualisation de VMware, VergeIO est basé sur l’hyperviseur open source KVM. Cependant, VergeIO n’utilise pas une version standard de KVM, mais une base d’hyperviseur KVM fortement modifiée, comme la qualifie M. Crump, avec des améliorations propriétaires significatives, avec néanmoins de fortes connexions avec la communauté open-source. Actuellement, 70 % des déploiements de VergeIO se font sur site et 30 % environ via des fournisseurs de services bare-metal, l’adhésion étant particulièrement forte parmi les fournisseurs de services cloud qui hébergent des applications pour leurs clients. Le logiciel nécessite un accès direct au hardware en raison de son intégration de bas niveau avec les ressources physiques. « Depuis novembre 2023, le client type qui adopte notre solution est celui qui a est tombé à la renverse en recevant sa licence de renouvellement de VMware », a expliqué M. Crump. « Plus on possède d’éléments de la pile, plus notre histoire s’améliore ». Un rapport de 2024 du Data Center Intelligence Group (DCIG) a identifié VergeOS comme l’une des cinq principales alternatives à VMware. « VergeIO commence par installer VergeOS sur des serveurs bare metal », indique le rapport. « Il place ensuite les ressources matérielles des serveurs sous sa gestion, les catalogue et les met à la disposition des machines virtuelles. En accédant directement aux ressources matérielles du serveur et en les gérant, il les optimise d’une manière que les autres hyperviseurs ne peuvent souvent pas faire. »Fonctionnalités réseau avancées de VergeFabricVergeFabric est le composant réseau de l’écosystème VergeOS. Il fournit des capacités de réseau SDN en tant que service intégré plutôt que de machine virtuelle ou d’application séparée. VergeFabric est exclusivement disponible dans VergeOS et ne peut pas être déployé en tant que produit autonome ou intégré à d’autres hyperviseurs tels que VMware ESX. La dernière version de VergeFabric va au-delà de la virtualisation de réseau de base pour inclure un ensemble plus large de capacités de mise en réseau. Plus précisément, la version améliorée de VergeFabric comprend désormais :- Le routage BGP qui permet de définir des itinéraires entre différents centres de données physiques et virtuels.- Une fonctionnalité complète de pare-feu pour le contrôle d’accès et la sécurité.- Des services DNS directement intégrés dans la plateforme.- Une surveillance de la sécurité avec mise en miroir des ports pour la surveillance du trafic est-ouest et nord-sud à des fins d’analyse de la sécurité.- La gestion du trafic, y compris la limitation du débit pour un meilleur contrôle des ressources.Multi-location et segmentation du réseau pour les datacenters virtuelsL’une des caractéristiques les plus remarquables de VergeFabric est son approche de la multi-location qui permet de créer des centres de données virtuels. Cette capacité est particulièrement précieuse pour les fournisseurs de services qui doivent isoler les environnements des clients tout en partageant l’infrastructure physique. « Lorsqu’ils intègrent un nouveau client, ils utilisent notre multi-location, que nous appelons centre de données virtuel, pour coordonner ce client particulier dans sa propre zone », a fait valoir M. Crump. « Il partage toujours les mêmes ressources, mais à partir de ce moment-là, il s’agit de son propre monde ». Cette segmentation se fait automatiquement au niveau du réseau. M. Crump fait remarquer que dès qu’un centre de données virtuel est créé, il est automatiquement segmenté par rapport aux autres. La plateforme prend en charge un nombre illimité de réseaux, tant internes qu’externes, avec un contrôle granulaire des communications. À l’avenir, VergeIO prévoit d’intégrer davantage de capacités de sécurité dans la plateforme au cours des prochaines versions, y compris de l’IA. M. Crump a indiqué que les capacités de détection des menaces, en particulier, utiliseront la télémétrie provenant de l’hyperviseur, du réseau et des composants de stockage. « À partir de maintenant, nous essayons vraiment de tirer parti de ces données télémétriques sur des éléments généralement séparés les uns des autres », a-t-il précisé.