





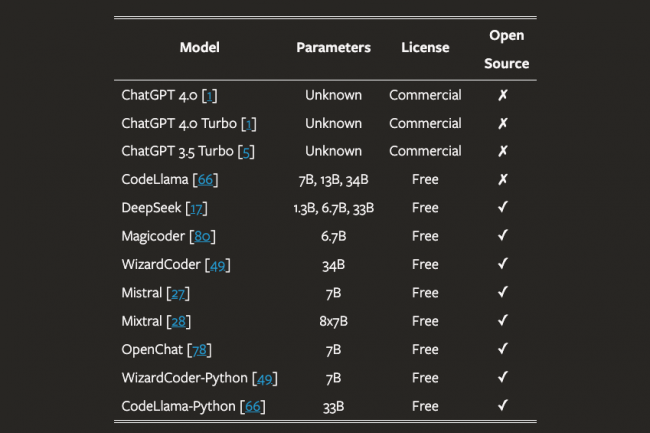
D’après la première étude importante sur l’hallucination de paquets, les LLM pourraient être exploités pour lancer des vagues d’attaques par « confusion de paquets ».
Dans l’une des études les plus étendues et les plus approfondies jamais réalisées sur le sujet, des chercheurs universitaire (Université de San Antonio au Texas, Université de Virginie et Université de l’Oklahoma) ont découvert que les grands modèles de langage (LLM) présentaient un sérieux problème d’hallucination de paquets que des attaquants pourraient exploiter pour introduire des paquets codés malveillants dans la chaîne d’approvisionnement. Le problème est tellement grave…
Il vous reste 94% de l’article à lireVous devez posséder un compte pour poursuivre la lecture
Vous avez déjà un compte?
Les entreprises et les employés sont impatients de tester l’agent conversationel GenAI de Microsoft. Mais de nombreux projets de déploiement restent bloqués au stade pilote en raison des défis liés à la gouvernance des données et au suivi du retour sur investissement.
Avec la promesse d’une plus grande productivité des employés, Microsoft 365 Copilot (ex Copilot for Microsoft 365) a suscité beaucoup d’intérêt de la part des entreprises avant même son lancement en novembre dernier. Cet enthousiasme initial a incité de nombreux clients de la suite bureautique et collaborative à mettre l’assistant d’IA générative entre les mains de leurs employés. Mais pour de nombreuses entreprises, ces déploiements ont toutefois à ce stade été largement limités…
Il vous reste 96% de l’article à lireVous devez posséder un compte pour poursuivre la lecture
Vous avez déjà un compte?
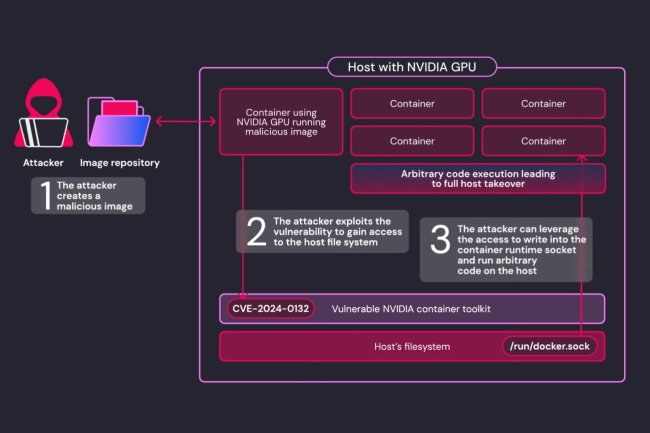
Nvidia a corrigé une vulnérabilité critique dans son outil de conteneurisation, Container Toolkit. Elle est capable d’exécuter du code à distance et de provoquer un déni de service.
Autrefois appelé Nvidia Docker, le service Container Toolkit (NCT) du fournisseur comprend une faille importante. La CVE-2024-0132 affiche un score de gravité (CVSS) de 9 sur 10. Un utilisateur ou une application malveillante peut s’évader de leur conteneur dédié et gagner un accès complet à l’hôte sous-jacent. « Nvidia Container Toolkit 1.16.1 ou antérieur contient une vulnérabilité TOCTOU (Time-of-check Time-of-Use) de l’heure de vérification à l’heure d’utilisation quand il fonctionne avec la configuration par défaut, où une image de conteneur spécifiquement élaborée peut accéder au système de fichiers de l’hôte », a expliqué le fournisseur dans une note sur le correctif publiée dans son bulletin de sécurité. De plus, dans certaines circonstances, l’exploitation réussie de la vulnérabilité entraîne l’exécution de code, le déni de service, l’escalade des privilèges, la divulgation d’informations et l’altération des données.
Vulnérabilité Time of Check Time of Use (TOCTOU)
Les conteneurs Nvidia, qui sont des logiciels spécialisés conçus pour faciliter le déploiement d’applications impliquant de l’intelligence artificielle et de l’apprentissage machine, s’appuient sur NCT pour accéder au matériel GPU. C’est grâce aux outils et aux bibliothèques du Toolkit que les applications s’exécutant dans les conteneurs peuvent utiliser le GPU. La démonstration a été faite dans un billet de blog de Wiz Research, dont les chercheurs ont été crédités par Nvidia de la découverte de la faille. Les attaquants contrôlant une image de conteneur exécutée par une boîte à outils, autrement dit un paquet exécutable léger et autonome contenant tout ce qui est nécessaire pour exécuter une application, peuvent s’évader du conteneur et obtenir un accès complet à l’hôte.
Cette condition de concurrence appelée « Time-of-check Time-of-Use » se produit lorsqu’un programme vérifie une condition et utilise ensuite le résultat de cette vérification sans s’assurer que la condition n’a pas changé dans l’intervalle. Même si les détails techniques spécifiques de l’exploitation potentielle n’ont pas été divulgués pour des raisons de sécurité, le blog Wiz a partagé un flux d’attaque potentiel. « L’attaquant crée une image spécialement conçue pour exploiter la faille CVE-2024-0132 », ont écrit les chercheurs dans le blog. « L’attaquant exécute l’image malveillante sur la plateforme cible, soit directement dans les services permettant le partage des ressources GPU, soit indirectement par le biais d’une supply chain ou d’une attaque d’ingénierie sociale, par exemple un utilisateur exécutant une image d’IA à partir d’une source non fiable. »
Dans quels cas appliquer les correctifs ?
Comme indiqué dans les notes de correction, la vulnérabilité dite d’évasion des conteneurs affecte toutes les versions de Nvidia Container Toolkit jusqu’à la version v1.16.1 incluse. Selon les chercheurs de Wiz, le Toolkit est très répandu et la faille pourrait affecter 35 % des environnements cloud. « Cette bibliothèque est largement adoptée comme solution pour accéder au GPU Nvidia depuis les conteneurs », ont ajouté les chercheurs. « De plus, elle est préinstallée dans de nombreuses plateformes d’IA et images de machines virtuelles (comme les Amazon Machine Images, AMI), car il s’agit d’une exigence d’infrastructure commune pour les applications d’IA. »
Pour les environnements partagés comme Kubernetes, le bug peut être exploité pour s’échapper d’un conteneur et accéder aux données et aux secrets sur d’autres « applications exécutées sur le même nœud, voire sur le même cluster », exposant ainsi l’ensemble de l’environnement. Il est donc recommandé aux entreprises utilisant un modèle de calcul partagé de mettre immédiatement à jour la boîte à outils. « Un attaquant pourrait déployer un conteneur nuisible, s’en échapper et utiliser les secrets de la machine hôte pour cibler les systèmes de contrôle du service cloud », ont mis en garde les chercheurs. « Un attaquant pourrait alors accéder à des informations sensibles, comme le code source, les données et les secrets d’autres clients utilisant le même service ». L’entreprise a précisé que la vulnérabilité n’avait pas d’incidence sur les cas d’usage impliquant l’interface CDI (Container Device Interface). Pour tous ceux qui souhaitent utiliser la boîte à outils Nvidia Container, un correctif est désormais disponible.

La Fondation Eclipse a mis en place un groupe de travail chargé de travailler sur la conformité de la communauté open source aux différentes réglementations sur l’IA ou sur la cybersécurité en particulier celles de l’UE. La structure sert aussi à mener des actions de lobbying auprès des législateurs sur les spécificités du logiciel libre.
Depuis quelques années, la communauté open source doit faire face à une multiplicité de cadre réglementaire. Elle a du batailler sur certains textes comme le règlement européen sur la cyber-résilience pour prendre en compte les spécificités du monde open source. Fort de cette expérience, la Fondation Eclipse a lancé l’Open Regulatory Compliance Working Group (ORC WG) pour aider les développeurs, les entreprises, les industries et les fondations open source, à naviguer et à adopter des cadres réglementaires en constante évolution.
En particulier, le groupe de travail, qui compte parmi ses membres la Python Software Foundation et la Rust Foundation, prévoit d’aider les entreprises à se conformer en connaissance de cause aux exigences réglementaires de l’Union européenne, comme le règlement sur la cyberrésilience ou l’IA Act ainsi que le Data Act. Sur le premier, le groupe de travail va discuter avec les organismes de réglementation et les gouvernements pour améliorer leur compréhension du modèle de développement unique de l’open source.
Une structure d’aide et de lobbying
« Le groupe de travail sur la conformité réglementaire de l’open source a été créé pour combler le fossé entre les autorités réglementaires et l’écosystème open source, en veillant à ce que les organisations et les développeurs puissent exploiter les technologies open source tout en restant conformes à l’évolution des réglementations mondiales », a expliqué Mike Milinkovich, directeur exécutif d’Eclipse, dans un communiqué.
Le groupe formalisera les meilleures pratiques de l’industrie et offrira des ressources pour aider les entreprises à naviguer dans les exigences réglementaires à travers de multiples juridictions. Il a également l’intention d’aider les entités gouvernementales à fournir une plus grande sécurité juridique à l’écosystème open source et à le cycle de développement des logiciels. L’objectif global est d’améliorer la qualité et la sécurité des logiciels dans les projets open source.
À la date du 24 septembre, les organisations participantes au groupe de travail étaient : Apache Software Foundation, Blender Foundation, Robert Gosh, Code Day, The Document Foundation, FreeBSD Foundation, iJUG, Lunatech, Matrix.org Foundation, Mercedes-Benz Tech Innovation, Nokia, NLnet Labs, Obeo, Open Elements, OpenForum Europe, OpenInfra Foundation, Open Source Initiative, Open Source Robotic Foundation, OWASP, Payara Services, The PHP Foundation, Python Software Foundation, Rust Foundation, Scanoss, Siemens et Software Heritage.

L’augmentation des tarifs d’assurance due aux ransomwares ces dernières années semble se stabiliser alors que les réglementations européennes incitent davantage d’entreprises à envisager une couverture.
L’explosion des tarifs des cyberassurance est-elle révolue ? Au cours des dernières années, les indemnités versées par les assureurs ont dépassé 70 % des primes, ce qui a pu créer un environnement commercial insoutenable pour les assureurs qui ont réagi en montant les primes. Face à l’augmentation des demandes d’indemnisation, le prix des contrats a cependant grimpé bien au-delà des niveaux d’inflation, les assureurs imposant par ailleurs des conditions de souscription plus strictes voire dans certains cas des…
Il vous reste 96% de l’article à lireVous devez posséder un compte pour poursuivre la lecture
Vous avez déjà un compte?

L’authentification à deux facteurs (2FA) ou double authentification va au-delà des mots de passe par l’ajout d’une deuxième couche de sécurité au processus d’authentification, et offre aux entreprises et aux utilisateurs un meilleur moyen de sécuriser leurs données.
L’authentification à deux facteurs (2FA) est une méthode d’accès sécurisée qui repose sur deux formes d’identification (appelées facteurs), le plus souvent un mot de passe associé à un second facteur comme un jeton physique, un code généré par une application sur le téléphone de l’utilisateur ou une empreinte biométrique. L’objectif principal de la 2FA est de fournir une deuxième couche de protection pour l’accès aux systèmes et aux comptes et de rendre ainsi plus difficile…
Il vous reste 97% de l’article à lireVous devez posséder un compte pour poursuivre la lecture
Vous avez déjà un compte?

Les améliorations de la dernière itération de Java sont en particulier liées aux performances de chiffrement, des options de débogage mais aussi à la prise en charge de Kerberos et PKI.
Java 23, publié il y a un peu plus d’une semaine, présente une douzaine de caractéristiques officielles, allant d’un deuxième aperçu de l’API de fichiers de classe à un autre incubateur d’API vectorielle, mais il est également doté de diverses fonctions de sécurité. Les améliorations en la matière comprennent des mises à jour des performances de chiffrement et l’ajout du support de Kerberos et PKI. Lors de son lancement, Sean Mullan, responsable technique de l’équipe chargée des bibliothèques de sécurité Java chez Oracle, a énuméré les fonctionnalités de la boite à outils pour développeurs de la dernière itération de ce langage, JDK 23. Pour javax.crypto, la taille de la mémoire tampon de CipherInputStream a été augmentée de 512 octets à 8 192 octets. Cela peut améliorer les performances et est plus cohérent avec les tailles de tampon pour d’autres API telles que java.io.FileInputStream. Les performances de la construction d’un objet java.security.SecureRandom via new SecureRandom() ont également été améliorées. Pour l’API de chiffrement un nouvel attribut de configuration PKS11 nommé allowLegacy a été introduit. Les applications peuvent définir cette valeur sur “true” pour contourner les vérifications de l’héritage. La valeur par défaut est “false.”
Concernant PKI, de nouveaux certificats d’autorité racine ont été ajoutés au magasin de clés cacerts, notamment CN=Certainly Root R1, 0=Certainly, C=US et CN=Certainly Root E1, O=Certainly, C=US. Deux certificats au niveau racine GlobalSign sont également disponibles : CN=GlobalSign Root R46, O=GlobalSign nv-sa, C=BE et CN=GlobalSign Root E46, O=GlobalSign nv-sa, C=BE. En outre, un magasin de clés javasecurity.Keystore nommé KeychainStore-ROOT a été ajouté pour Apple. Ce keystore contient les certificats racine stockés dans le trousseau du système sur les systèmes macOS. Deux keystores sont désormais supportés : KeychainStore-Root et KeychainStore qui contient les clés privées et les certificats du trousseau de l’utilisateur. Cette amélioration corrige les problèmes qui provoquaient l’échec des connexions HTTP parce que le JDK n’était pas en mesure de trouver un certificat racine pour établir la confiance dans la chaîne de certificats de l’homologue.
Des méthodes d’accès mémoire bientôt supprimées
Kerberos dans JDK 23 ajoute une propriété de sécurité, nommée jdk.security.krb5.name.case.sensitive, pour permettre la vérification de la sensibilité à la casse des noms des principaux Kerberos dans les fichiers keytab et credential cache. En outre, le débogage output du composant Kerberos est désormais traitée comme erreur standard et non en tant qu’output standard. En termes d’autorisation relatives à JDK 23, la fonction getSubject lève désormais une exception de type UnsupportedOperationException à moins qu’un gestionnaire de sécurité ne soit autorisé ou activé. Cette modification a été effectuée pour préparer les utilisateurs à une future version dans laquelle cette méthode sera modifiée de manière à ce qu’elle génère toujours une exception de type “UnsupportedOperationException”. De nouvelles options “thread” et “timestamp” ont été ajoutées à la propriété système java.security.debug pour faciliter le débogage des applications. Sean Mullan note également la dépréciation des méthodes d’accès à la mémoire dans sun.misc.Unsafe dont la suppression est prévue, ce qui est l’une des 12 fonctions établies dans le JDK 23. Le JEP (JDK Enhancement Proposal) indique que l’effacement de ces méthodes fait partie d’un effort à long terme pour garantir l’intégrité par défaut de la plateforme Java.
Des chercheurs en sécurité de watchTowr ont récemment démontré comment des pirates pouvaient abuser de Whois pour obtenir des certificats délivrés frauduleusement pour des domaines dont ils ne sont pas propriétaires. Une situation qui a fait réagir Google qui veut interdire ce répertoire pour identifier les contacts de domaine à partir du 1er novembre 2024.
Le célèbre annuaire de noms de domaine Whois de l’Icann pour retrouver l’identité et les coordonnées de ceux qui détiennent ces noms de domaine (nom et prénom, adresse postale, téléphone et email) est bien malgré lui sous le feu des projecteurs. Des chercheurs en sécurité de de watchTowr ont découvert récemment que certains serveurs de courrier électronique et autorités de certification (AC) s’appuient sur des enregistrements périmés pour les…
Il vous reste 94% de l’article à lireVous devez posséder un compte pour poursuivre la lecture
Vous avez déjà un compte?
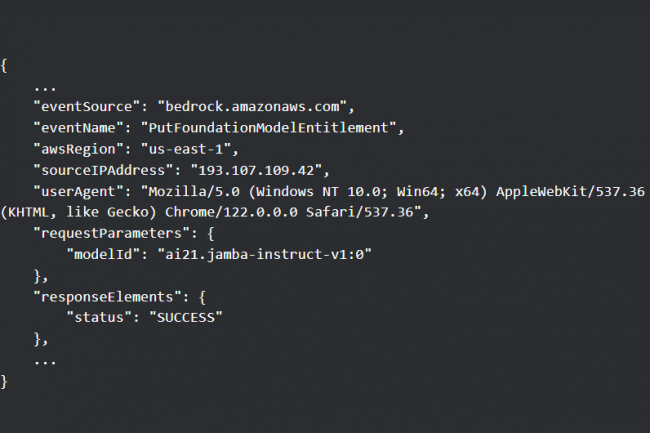
De plus en plus souvent, les utilisateurs de services cloud d’IA tels qu’Amazon Bedrock sont la cible d’attaquants qui utilisent des identifiants volés pour accéder à des ressources LLM. Avec à la clé d’importants dommages financiers pour leurs victimes.
Selon une étude de Sysdig, le marché noir de l’accès aux grands modèles de langage (LLM) se développe. Dans ce que l’on appelle désormais le LLMjacking, les attaquants abusent d’identifiants volés pour interroger des services de requête d’IA tels qu’Amazon Bedrock. D’après les requêtes API observées par Sysdig, il semble que les acteurs de la menace interrogent non seulement les LLM que les propriétaires de comptes ont déjà déployés sur ces plateformes, mais qu’ils tentent également d’en activer de nouveaux, ce qui pourrait rapidement faire grimper les coûts pour les victimes. « Le LLMjacking lui-même est en hausse : au cours du mois de juillet, les requêtes LLM ont été multipliées par 10 et au cours du premier semestre 2024, le nombre d’adresses IP uniques engagées dans ces attaques a été multiplié par 2 », ont déclaré les chercheurs de l’entreprise de sécurité dans un rapport. « Avec la progression continue du développement de LLM, le premier coût potentiel pour les victimes est monétaire : par exemple, l’utilisation de modèles de pointe comme Claude 3 Opus peut quasiment tripler le coût à hauteur de 100 000 $ par jour. »
C’est pour profiter des jeux de rôle, générer des scripts, analyser des images et utiliser des invites textuelles sans payer et sans les limites normales imposées par les services gratuits que les attaquants souhaitent accéder aux LLM. Sysdig a trouvé des preuves que, dans certains cas au moins, les utilisateurs qui se livrent au LLMjacking sont basés en Russie, où les sanctions occidentales ont imposé des limites sévères à l’accès aux chatbots LLM et aux services fournis par des entreprises occidentales. « La principale langue utilisée dans les invites est l’anglais (80 %), la deuxième, le coréen (10 %), le reste étant le russe, le roumain, l’allemand, l’espagnol et le japonais », ont indiqué les chercheurs.
Des API Bedrock abusées
Le service Amazon Bedrock d’AWS permet aux entreprises de déployer et d’utiliser facilement les LLM de plusieurs fournisseurs d’IA, de les enrichir de leurs propres ensembles de données et de créer des agents et des applications autour d’eux. Le service prend en charge une longue liste d’actions API pour gérer les modèles et d’interagir avec eux par programmation. Les actions API les plus courantes appelées par les attaquants via des informations d’identification compromises au début de cette année comprenaient InvokeModel, InvokeModelStream, Converse et ConverseStream. Mais récemment, les chercheurs ont aussi vu que des attaquants abusaient de PutFoundationModelEntitlement et de PutUseCaseForModelAccess, utilisées pour activer des modèles, ainsi que ListFoundationModels et GetFoundationModelAvailability, afin de détecter à l’avance les modèles auxquels un compte a accès. Cela signifie que les entreprises qui ont déployé Bedrock sans activer certains modèles ne sont pas à l’abri.
L’écart de coût entre les différents modèles peut être substantiel. Par exemple, pour l’utilisation d’un modèle Claude 2.x, les chercheurs ont estimé le coût potentiel à plus de 46 000 $ par jour, mais pour des modèles tels que Claude 3 Opus, le coût pourrait être deux à trois fois plus élevé. Les chercheurs ont vu des attaquants utiliser Claude 3 pour générer et améliorer le code d’un script destiné à interroger le modèle en premier lieu. Le script a pour objectif d’interagir en permanence avec le modèle, en générant des réponses, en surveillant un contenu spécifique et en enregistrant les résultats dans des fichiers texte. « La désactivation des modèles dans Bedrock et l’exigence d’activation ne doivent pas être considérées comme une mesure de sécurité », ont mis en garde les chercheurs. « Les attaquants peuvent les activer à la place de l’utilisateur et le feront pour atteindre leurs objectifs ». C’est ce qui se passe par exemple avec l’API Converse, annoncée en mai, qui simplifie l’interaction des utilisateurs avec les modèles Amazon Bedrock. Selon Sysdig, les attaquants ont commencé à abuser de l’API dans les 30 jours qui ont suivi sa publication. Ils précisent par ailleurs que les actions Converse API n’apparaissent pas automatiquement dans les journaux CloudTrail, contrairement aux actions InvokeModel.
La sécurisation des identifiants et des jetons LLM en guise d’atténuation
Même si la journalisation est activée, les attaquants malins essaieront de la désactiver en appelant DeleteModelInvocationLoggingConfiguration, qui désactive la journalisation des invocations pour CloudWatch et S3. Dans d’autres cas, ils vérifieront l’état de la journalisation et éviteront d’utiliser des informations d’identification volées afin de dissimuler leur activité. Souvent, les attaquants n’appellent pas directement les modèles Bedrock d’Amazon, mais utilisent des services et des outils tiers. C’est le cas par exemple de SillyTavern, une application frontale pour interagir avec les LLM qui demande aux utilisateurs de fournir leurs propres identifiants à un service LLM de leur choix ou à un service proxy. « Compte tenu du coût important, tout un marché et un écosystème se sont développés autour de l’accès aux LLM », avertissent les chercheurs. « Les informations d’identification sont obtenues de différentes manières : paiement, essais gratuits ou vol. Comme cet accès est une denrée précieuse, des serveurs proxy inversés sont utilisés pour garder les informations d’identification en lieu sûr et sous contrôle. »
Les entreprises doivent prendre des mesures pour s’assurer que leurs identifiants et jetons AWS ne sont pas divulgués dans des référentiels de code, des fichiers de configuration et ailleurs. Elles doivent également appliquer le principe du moindre privilège en limitant les jetons à la tâche pour laquelle ils ont été créés. « Les entreprises doivent évaluer en permanence leur cloud par rapport aux contrôles de posture des meilleures pratiques, telles que la norme AWS Foundational Security Best Practices », ont recommandé les chercheurs de Sysdig. « Elles doivent surveiller leur cloud pour détecter les informations d’identification potentiellement compromises, les activités inhabituelles, l’usage inattendu de LLM et les indicateurs de menaces actives ciblant l’IA. »

Les bonnes pratiques de gestion des correctifs restent partiellement respectées, malgré de meilleurs outils et les changements des organisations IT. Comme l’a démontré de façon éclatante la panne Crowdstrike.
Le déploiement des correctifs de sécurité reste un défi en entreprise, malgré les améliorations apportées à la fois à l’évaluation des vulnérabilités et aux technologies de mise à jour. Les priorités divergentes, les défis organisationnels et la dette technique continuent de transformer l’objectif apparemment simple de maintien à jour des systèmes en véritable casse-tête, selon les experts interrogés.À cause de ces difficultés, environ 60 % des applications d’entreprise ne sont pas corrigées six mois après la publication d’une vulnérabilité, selon l’éditeur de solutions de sécurité cloud Qualys. Seules 40% des entreprises corrigent les vulnérabilités critiques dans les 30 premiers jours qui suivent leur divulgation.La prolifération des applications ne rend pas service à l’informatique d’entreprise. Une étude récente de la société Adaptiva, spécialisée dans la gestion des correctifs, a révélé qu’en moyenne, une entreprise gère 2 900 applications. Cela fait beaucoup de correctifs potentiels à apporter, surtout que le nombre de vulnérabilités détectées ne cesse d’augmenter.Autant de facteurs qui contribuent à augmenter la probabilité d’une interruption de l’activité de l’entreprise. « Plus une entreprise doit déployer de correctifs, plus le risque de temps d’arrêt est élevé en raison de redémarrages ou de l’interruption d’une application par un correctif », résume Eran Livne, directeur principal de la gestion des produits chez Qualys.L’automatisation et ses lacunesCes dernières années, la gestion des correctifs est devenue une pratique de réduction des risques, les entreprises alignant les workflows de sécurité et de remédiation et donnant la priorité aux vulnérabilités à corriger en fonction de calculs d’exposition, de la probabilité d’un arrêt dû à la mise à jour et des coûts potentiels d’un tel arrêt.Selon Sanjay Macwan, DSI et RSSI de la plateforme de communication Vonage, « les entreprises doivent s’assurer qu’elles disposent d’un inventaire actualisé de leurs ressources afin de suivre tous les composants nécessitant des correctifs, ainsi que de politiques formelles et rigoureuses que chaque équipe doit suivre afin de coordonner une application efficace et en temps voulu des correctifs. Les correctifs devraient se voir associer des niveaux de risque afin de déterminer l’ordre dans lequel ils sont traités, et les équipes devraient disposer de processus de déploiement clairs, y compris une surveillance post-patch afin de détecter les erreurs critiques » consécutives au déploiement des correctifs.Eran Livne préconise l’utilisation d’outils d’automatisation « pour aider à réduire le travail manuel nécessaire à la gestion d’un grand nombre de vulnérabilités, en particulier celles les plus simples à corriger, et touchant les navigateurs, les lecteurs multimédias et les lecteurs de documents ». Grâce à l’automatisation des patchs de moindre priorité, les équipes chargées des opérations IT et de la sécurité peuvent se concentrer sur les correctifs de sécurité critiques et urgents.
Malgré leurs promesses, les outils automatisés ont leurs limites, prévient toutefois Rich Newton, consultant chez Pentest People : « les priorités de correction recommandées par les outils en fonction de la gravité des vulnérabilités ne correspondent pas toujours à la tolérance au risque spécifique de l’organisation ou à ses objectifs métiers, ce qui souligne la nécessité d’une supervision humaine. S’appuyer uniquement sur une solution de gestion des correctifs, en particulier dans les environnements informatiques complexes, peut s’avérer futile. Tous les systèmes ne peuvent pas être entièrement pris en charge par des outils automatisés, d’où la nécessité de mettre en place des politiques et des procédures de surveillance et d’évaluation continues de l’état des correctifs dans l’ensemble du parc informatique. »
Elie Feghaly, RSSI de l’entreprise de technologie de diffusion Vizrt, reconnaît que, bien que les outils d’évaluation des vulnérabilités et de correction automatisée soient très utiles, ils ne constituent pas la panacée. « Les rôles de remédiation automatisés sur des environnements informatiques compliqués s’accordent rarement avec des environnements très dynamiques et potentiellement sujets à des erreurs », explique-t-il.Le facteur Legacy – et son héritage encombrantEn outre, la grande majorité des environnements informatiques complexes exploitent une grande quantité de logiciels Legacy qui ne sont plus corrigés par leur fournisseur, souligne Martin Biggs, vice-président et directeur général pour la région EMEA chez Spinnaker. « Et lorsque des correctifs sont disponibles, ils peuvent être source de perturbations et nécessitent des tests de régression approfondis avant d’être déployés », souligne-t-il.Pour les environnements sensibles, il peut ainsi s’avérer pratiquement impossible d’appliquer un correctif, même lorsqu’il est disponible. Dans d’autres cas, l’application du correctif ne résout pas la vulnérabilité sous-jacente, qui n’est traitée que dans des mises à jour ultérieures, prévient Martin Biggs. « Il est tout à fait habituel dans le monde Oracle que la même vulnérabilité soit à nouveau corrigée par des correctifs publiés plusieurs trimestres après le correctif original », illustre-t-il. Avec de tels incertitudes et effets, voir de nombreuses entreprises tâtonner dans leur stratégie de gestion des correctifs n’est guère surprenant.Les tests au centre de l’attentionElie Feghaly (Vizrt) souligne un autre problème courant auquel les entreprises sont confrontées en matière de gestion des correctifs : « un correctif fonctionne parfaitement dans le laboratoire de test ou d’essai, mais provoque des dégâts considérables en production en raison d’une dépendance inattendue à l’égard d’une autre application. » Même si les facteurs externes et dépendances sont précisément les raisons principales plaidant pour le renforcement des tests. La panne très médiatisée du mois de juillet, causée par une mise à jour défaillante du contenu de Falcon par CrowdStrike et qui a fait tomber des systèmes dans le monde entier, a permis de remettre en pleine lumière l’importance des tests avant le déploiement des correctifs.« Les outils d’évaluation des vulnérabilités et d’application automatisée des correctifs peuvent considérablement atténuer les difficultés liées à la gestion des correctifs en assurant une surveillance continue, en identifiant les vulnérabilités en temps réel et en automatisant le déploiement des correctifs sans intervention manuelle », souligne Chris Morgan, analyste principal en matière de renseignement sur les cybermenaces chez ReliaQuest. « Toutefois, leur efficacité dépend d’une configuration adéquate, de mises à jour régulières et d’une intégration dans des pratiques de sécurité plus larges. Les correctifs doivent être testés de manière approfondie et déployés initialement sur un sous-ensemble réduit de systèmes, afin de minimiser le risque de pannes dues à des correctifs défectueux. »Thomas Richards, directeur associé du Synopsys Software Integrity Group, explique que les environnements de test automatisés peuvent contribuer à réduire le risque de perturbation. Mais pas si vous n’avez qu’une visibilité limitée sur ce qui doit être corrigé en amont. « Le défi auquel nos clients sont souvent confrontés consiste à configurer correctement les outils pour scanner et patcher tous les systèmes actifs de leur organisation, dit-il. Les raisons pour lesquelles les systèmes ne sont pas couverts par ce processus sont multiples : dispositifs anciens, mauvaises configurations, Shadow IT, systèmes qui devraient être mis hors service mais qui sont restés en ligne, etc. La partie la plus importante d’un programme de correction de vulnérabilités est de s’assurer qu’il couvre bien tous les systèmes sont couverts par ce programme et qu’ils font bien l’objet de mises à jour régulières. »Combler le fossé culturelDave Harvey, directeur de l’équipe de cyber-réponse chez KPMG en Grande-Bretagne, affirme qu’en plus d’une priorisation et d’une remédiation appropriées, une stratégie de gestion des correctifs réussie dépend de « l’intégration de renseignements efficaces sur la menace, d’un examen régulier et d’une collaboration efficace entre les équipes IT et de sécurité ». Sur ce dernier point, Madeline Lawrence, Chief Brand Officer de la société belge de cybersécurité Aikido Security, explique que les équipes d’ingéniérie se sentent souvent « dépassées et agacées » lorsqu’elles traitent des vulnérabilités de sécurité.Car il faut tenir compte du décalage total de mentalité entre les équipes de sécurité, « qui ont appris à envisager toutes les possibilités », et les développeurs, qui aiment « les raccourcis et l’efficacité », ajoute-t-elle. « Pour de nombreux développeurs, les équipes de sécurité qui se présentent avec des demandes s’apparentent à des trouble-fête. Cette différence fondamentale d’approche et de priorités pose des problèmes considérables aux organisations qui tentent d’amener les équipes chargées des opérations IT et de la sécurité à collaborer plus étroitement pour résoudre les failles de sécurité. »Selon Madeline Lawrence, « combler ce fossé ne passe pas seulement par de nouveaux outils ou processus, il faut aussi s’attaquer au fossé culturel et de communication qui sépare ces équipes clefs pour ce sujet, mais souvent mal alignées ». Au coeur de ce fossé se trouve le fait que les équipes chargées des opérations IT accordent la priorité à la disponibilité et aux performances des systèmes, tandis que les équipes chargées de la sécurité se concentrent sur l’atténuation des menaces. Cette tension entraîne souvent des conflits et des retards dans la résolution des problèmes de sécurité.Objectifs communs pour les devs, les ops et la sécurité« Ce défi est encore accentué par la complexité des environnements informatiques modernes, qui couvrent plusieurs plateformes et rendent difficile le maintien de la visibilité et du contrôle », souligne Christiaan Beek, directeur pour l’analyse des menaces chez Rapid7. « Il est également courant de constater des différences de tolérance au risque entre les équipes, ce qui peut conduire à des désaccords sur les vulnérabilités à prioriser, retardant ainsi les actions nécessaires. »Pour que les opérations informatiques, les développeurs de logiciels et les équipes de sécurité soient sur la même longueur d’onde, Eran Livne (Qualys) conseille de se concentrer sur des objectifs communs : « travailler sur des objectifs communs facilite la collaboration, la communication et l’élimination des risques. Cela permet également de renforcer la responsabilité de toutes les équipes concernées, plutôt que de les voir se rejeter la faute entre elles, comme cela s’est produit dans le passé. »Selon Rich Newton, de Pentest People, « il est possible d’améliorer considérablement les pratiques d’application des correctifs en en faisant une propriété conjointe entre les équipes informatiques et les équipes de sécurité. » Un avis que partage Dave Harvey (KPMG), pour qui les entreprises performantes intègrent des pratiques sécurisées dès le début de leurs processus de développement : « l’intégration de la sécurité et de la gestion des risques dans le processus de développement, dès son origine, permet une meilleure compréhension des problématiques, de sorte que les systèmes sont conçus et construits de manière sûre. »Afin de maîtriser leurs risques, les entreprises doivent donc surveiller leurs ressources informatiques en temps réel, ce qui leur permet de détecter les problèmes dans leur infrastructure le plus rapidement possible. Même si tous les problèmes de sécurité ne sont pas identiques. Moins de 1 % des vulnérabilités CVE publiées cette année ont été exploitées, il est donc impératif de se concentrer sur les risques qui comptent pour l’entreprise – et de le faire en se basant sur les données.