






Alerte sécurité sur plusieurs solutions VMware incluant ESXi, Workstation et Fusion. Des failles critiques ont été découvertes par Microsoft avec une exploitation active et un risque de prise de contrôle de systèmes hôtes par des pirates.
Broadcom a publié des correctifs en urgence pour plusieurs produits de sa filiale VMware : ESXi, Workstation, Fusion, Cloud Foundation et Telco Cloud Platform. Ces trois vulnérabilités susceptibles de déboucher sur une évasion de machines virtuelles ont été comblées : elles sont par ailleurs activement exploitées par des attaquants. Cette salve de patchs critiques intervient un an après une précédente qui concernait aussi ESXi, Workstation et Fusion. Les produits du spécialiste en…
Il vous reste 90% de l’article à lireVous devez posséder un compte pour poursuivre la lecture
Vous avez déjà un compte?

La complexité de l’existant et la sécurité sont des préoccupations majeures avant d’imaginer brancher des agents à base d’IA sur les SI. Tout comme la résorption de la dette technique.
L’IA agentique est la grande percée technologique de ces douze derniers mois, et cette année, les entreprises vont commencer à déployer ces systèmes à grande échelle. Selon une enquête réalisée en janvier par KPMG auprès de 100 cadres supérieurs de grandes entreprises, 12 % des sociétés déploient déjà des agents d’IA, tandis que 37 % sont en phase pilote et que 51 % étudient la possibilité de les utiliser. Selon un rapport du cabinet Gartner, datant d’octobre dernier, un tiers des applications d’entreprise incluront l’IA agentique d’ici 2033, contre moins de 1% en 2024. Selon le cabinet, 15% des décisions opérationnelles quotidiennes seront ainsi prises de manière autonome.En ce qui concerne les développeurs d’IA en particulier, tout le monde semble avoir déjà adopté cette évolution de l’IA générative. « En fait, nous avons commencé nos travaux dans l’IA en utilisant des agents presque dès le départ », indique Gary Kotovets, responsable data et analytics de Dun & Bradstreet.Les agents d’IA sont alimentés par des modèles d’IA générative mais, contrairement aux chatbots, ils peuvent gérer des tâches plus complexes, travailler de manière autonome et collaborer avec d’autres IA pour former des systèmes capables de gérer des processus entiers, de remplacer des employés ou d’atteindre des objectifs métiers complexes. Tout cela crée de nouveaux défis, qui s’ajoutent à ceux déjà posés par l’IA générative elle-même. En outre, contrairement aux automatismes traditionnels, les systèmes agentiques ne sont pas déterministes. Ce qui les met en porte-à-faux par rapport aux plateformes Legacy, par essence très déterministes.Agents tributaires de la qualité des donnéesDès lors, constater que 70 % des développeurs déclarent avoir des difficultés à intégrer les agents d’intelligence artificielle dans leurs systèmes existants n’est guère surprenant. C’est ce qui ressort d’une enquête réalisée en décembre par la société Langbase, spécialisée dans les plateformes d’IA, auprès de 3 400 développeurs mettant au point des agents d’IA.Le problème est en somme assez simple : avant de pouvoir intégrer les agents d’IA dans l’infrastructure d’une entreprise, celle-ci doit être mise à niveau et se conformer à des standards modernes. En outre, comme les agents nécessitent un accès à de multiples sources de données, des obstacles à l’intégration des données et des complexités nouvelles en matière de sécurité et de conformité se font jour. « Disposer de données propres et de qualité est la partie la plus importante du travail, déclare Gary Kotovets. Vous devez vous assurer de ne pas être confronté à un scénario de type garbage in, garbage out ». Un classique de la gestion de données, mais qui reste des plus valides à l’heure du passage à l’échelle des applications d’IA.Indispensable modernisation de l’infrastructureEn décembre dernier, Tray.ai, éditeur d’une plateforme d’intégration de l’IA, a mené une enquête auprès de plus de 1 000 professionnels des technologies en entreprise. Le constat ? 90 % des organisations reconnaissent que l’intégration avec les données métiers est essentielle à la réussite de leur stratégie, mais 86% d’entre elles disent qu’elles devront mettre à niveau leur existant technologique pour déployer des agents à base d’IA.Pour Ashok Srivastava, responsable des données chez l’éditeur de solutions de gestion pour PME et particuliers Intuit, « votre plateforme doit être ouverte pour que le LLM puisse raisonner et interagir avec elle de manière simple. Si vous voulez trouver du pétrole, vous devez percer le granit pour l’atteindre. Si toute votre technologie est enfouie et n’est pas exposée à travers le bon ensemble d’API, et à travers un ensemble flexible de microservices, offrir des expériences agentiques à vos utilisateurs s’annonce difficile. »Intuit lui-même traite 95 Po de données, génère 60 milliards de prédictions ML par jour, suit 60 000 attributs fiscaux et financiers par consommateur (et 580 000 par client professionnel). L’éditeur traite 12 millions d’interactions assistées par l’IA chaque mois, interactions qui sont disponibles pour 30 millions de consommateurs et un million de PME. En modernisant ses propres plateformes, Intuit a non seulement été en mesure de fournir de l’IA agentique à grande échelle, mais aussi d’améliorer d’autres aspects de son fonctionnement. « La vitesse de développement a été multipliée par huit au cours des quatre dernières années, explique Ashok Srivastava. Tout cela n’est pas dû à l’intelligence artificielle. Une grande partie est attribuable à la plateforme que nous avons construite. »Les agents et les batchsMais toutes les entreprises ne peuvent pas investir dans la technologie comme l’a fait Intuit. « La grande majorité des systèmes d’enregistrement dans les entreprises est encore basée sur des systèmes Legacy, souvent hébergés sur site, et ces systèmes alimentent encore de larges pans des entreprises », souligne Rakesh Malhotra, directeur au sein du cabinet de conseil EY. Ce sont ces systèmes transactionnels et opérationnels, ces systèmes de traitement des commandes, ces ERP et SIRH qui, actuellement, créent de la valeur pour l’entreprise. « Si la promesse des agents est d’accomplir des tâches de manière autonome, vous devez avoir accès à ces systèmes », ajoute-t-il.Mais cette connexion demeure inutile lorsqu’un système fonctionne en mode batch. Avec les agents d’IA, les utilisateurs s’attendent généralement à ce que les opérations se déroulent rapidement, et non pas 24 heures après, observe Rakesh Malhotra. Il existe des moyens de résoudre ce problème, mais les entreprises doivent y réfléchir attentivement.« Les organisations qui ont déjà mis à jour leurs systèmes transactionnels pour s’interfacer avec leurs anciennes plateformes ont une longueur d’avance », ajoute l’expert d’EY. Mais disposer d’une plateforme moderne avec un accès API standard ne permet de parcourir que la moitié du chemin. Les entreprises doivent encore faire en sorte que les agents d’IA communiquent avec les systèmes en place.Les défis de l’intégration des donnéesIndicium, prestataire de services de données d’origine brésilienne, est une entreprise numérique dotée de plateformes modernes. « Nous n’avons pas beaucoup de systèmes Legacy », confirme Daniel Avancini, responsable data de l’entreprise. Indicium a commencé à construire des systèmes multi-agents à la mi-2024 pour la recherche de connaissances internes et d’autres cas d’utilisation. Les systèmes de gestion des connaissances sont à jour et prennent en charge les appels d’API, mais les modèles d’IA génératives communiquent en anglais. Et comme les agents d’IA individuels sont alimentés par l’IA générative, ils parlent également cette langue, ce qui crée des problèmes lorsqu’on essaie de les connecter aux systèmes de l’entreprise.« Vous pouvez faire en sorte que les agents d’IA renvoient du XML ou un appel d’API », explique Daniel Avancini. Mais lorsqu’un agent, dont l’objectif principal est de comprendre les documents de l’entreprise, essaie de dialoguer en XML, il peut commettre des erreurs. Mieux vaut faire appel à un spécialiste, conseille le chief data officer. « Donc vous avez besoin d’un autre agent dont le seul travail consiste à traduire l’anglais en API, ajoute-t-il. Il faut ensuite s’assurer que l’appel à l’API est correct. »Une autre approche pour résoudre le problème de la connectivité consiste à encapsuler les agents dans des logiciels traditionnels, de la même manière que les entreprises utilisent actuellement l’intégration RAG pour connecter les outils d’IA générative à leurs workflows au lieu de donner aux utilisateurs un accès direct et sans intermédiaire à l’IA. C’est ce que fait par exemple l’équipementier réseau Cisco. « Nous concevons les agents autour d’une sorte de modèle de base, mais systématiquement environné par une application traditionnelle », explique Vijoy Pandey, vice-président sénior de l’entreprise, qui dirige également Outshift, le moteur d’incubation de Cisco. Cela signifie qu’il y a un code traditionnel s’interfaçant avec les bases de données, les API et les environnements cloud et gérant les problèmes de communication.Contrôler les accès des agentsOutre la question de la traduction, un autre défi de l’intégration de données réside dans le nombre de sources de données auxquelles les agents doivent avoir accès. Selon l’enquête de Tray.ai, 42% des entreprises ont besoin d’accéder à huit sources de données ou plus pour déployer avec succès des agents d’IA. 79 % d’entre elles s’attendent d’ailleurs à ce que les défis liés aux données aient un impact sur les déploiements d’agents. En outre, 38 % des entreprises affirment que la complexité de l’intégration apparaît comme le principal obstacle au passage à l’échelle des agents d’IA.Pire encore, la raison pour laquelle une entreprise utilise l’IA plutôt que des logiciels traditionnels réside dans la capacité des agents à apprendre, s’adapter et trouver de nouvelles solutions à de nouveaux problèmes. « Vous ne pouvez pas prédéterminer les types de connexions dont vous aurez besoin pour cet agent, dit donc Vijoy Pandey. Vous avez ainsi besoin d’un ensemble dynamique de plugins.’Toutefois, donner trop d’autonomie à l’agent pourrait s’avérer désastreux, c’est pourquoi ces connexions devront être soigneusement contrôlées. « Ce que nous avons construit s’apparente à une bibliothèque chargée dynamiquement, explique le cadre de Cisco. Si un agent a besoin d’effectuer une action sur une instance AWS, par exemple, vous allez récupérer les sources de données et la documentation API dont vous avez besoin, en fonction de l’identité de la personne qui a demandé cette action [donc de ses droits d’accès, NDLR], au moment de son exécution. »Adapter la sécurité au niveau d’autonomie des agentsQue se passe-t-il alors si un humain ordonne au système agentique de faire quelque chose qu’il n’est pas en droit de faire ? Les modèles d’IA génératives sont en effet vulnérables aux messages astucieux qui les incitent à franchir les limites des actions autorisées, des pratiques connues sous le nom de ‘jailbreaks’. Ou encore que se passe-t-il si l’IA elle-même décide de faire quelque chose qu’elle n’est pas censée faire ? Ce qui pourrait se produire si des contradictions apparaissent entre l’entraînement initial d’un modèle, son fine-tuning, les prompts ou ses sources d’information. Dans un rapport de recherche publié par l’éditeur d’outils d’IA générative Anthopic à la mi-décembre, en collaboration avec Redwood Research, des modèles à la pointe des développements essayant d’atteindre des objectifs contradictoires ont tenté de passer outre leurs limites, ont menti sur leurs capacités et se sont livrés à d’autres types de tromperie.Selon Vijoy Pandey de Cisco, avec le temps, les agents d’IA devront avoir plus d’autonomie pour effectuer leur travail. « Mais deux problèmes subsistent, reconnaît-il. L’agent d’IA lui-même pourrait faire quelque chose [d’inapproprié]. Et puis, il y a l’utilisateur ou le client. Quelque chose de bizarre peut très bien se produire. » L’expert de Cisco explique réfléchir à ce sujet en termes de rayon d’action : si quelque chose ne va pas, que ce quelque chose émane de l’IA ou de l’utilisateur, quelle est l’ampleur du rayon d’action potentiel ? Lorsque celui-ci est important, les garde-fous et les mécanismes de sécurité doivent être adaptés en conséquence. « Au fur et à mesure que les agents gagnent en autonomie, il faut mettre en place des garde-fous et des cadres de sécurité adaptés pour ces niveaux d’autonomie », ajoute-t-il.Agents conformes à la loi ?Chez Dun & Bradstreet aussi, les agents d’IA sont strictement limités dans ce qu’ils peuvent faire, dit Gary Kotovets. Par exemple, l’un des principaux cas d’utilisation consiste à donner aux clients un meilleur accès aux dossiers que le prestataire possède sur environ 500 millions de sociétés dans le monde. Ces agents ne sont pas autorisés à ajouter des enregistrements, à les supprimer ou à apporter d’autres modifications. « Il est trop tôt pour leur donner cette autonomie », souligne responsable data et analytics.En fait, pour l’heure, les agents ne sont même pas autorisés à rédiger leurs propres requêtes SQL. Les interactions avec les plateformes de données sont gérées par des mécanismes existants et sécurisés. Les agents sont utilisés pour créer une interface utilisateur intelligente, se positionnant au-dessus de ces mécanismes. Toutefois, à mesure que la technologie s’améliore et que les clients souhaitent davantage de fonctionnalités, cette situation pourrait changer. « Cette année, l’idée est d’évoluer avec nos clients, explique Gary Kotovets. S’ils souhaitent prendre certaines décisions plus rapidement, nous créerons des agents en fonction de leur tolérance au risque. »Dun & Bradstreet n’est pas la seule à s’inquiéter des risques liés aux agents d’IA. En plus de la qualité de données, de la confidentialité et de la sécurité, Insight Partners constate que la conformité se hisse parmi les principales préoccupations des entreprises. Et pose des obstacles supplémentaires au déploiement d’agents d’IA, en particulier dans les secteurs sensibles, fortement régulés ou soumis à des réglementations sur la souveraineté des données ou sur la protection des données personnelles.Par exemple, lorsque les agents d’Indicium tentent d’accéder à des données, l’entreprise remonte à la source de la demande, c’est-à-dire à la personne qui a posé la question enclenchant l’ensemble du processus. « Nous devons authentifier la personne pour nous assurer qu’elle dispose des autorisations nécessaires, explique Daniel Avancini. Toutes les entreprises ne comprennent pas la complexité de ce processus. »Tester, contrôler, étudier tout écartDaniel Avancini ajoute que ce type de contrôle d’accès précis peut s’avérer difficile à déployer, en particulier avec les systèmes Legacy. Une fois l’authentification établie, elle doit en effet être préservée tout au long de la chaîne d’agents traitant la question. « C’est un véritable défi, dit le responsable data. Il faut disposer d’un très bon système de modélisation des agents et de nombreux garde-fous. Il y a beaucoup de questions sur la gouvernance de l’IA, mais peu de réponses ». Et comme les agents parlent anglais, il existe une infinité d’astuces pour les tromper. « Nous procédons à de nombreux tests avant de mettre en oeuvre quoi que ce soit, puis nous effectuons des contrôles. Tout ce qui n’est pas correct ou ne devrait pas être là mérite d’être examiné. »Au sein de la société de conseil informatique CDW, les agents d’IA sont déjà utilisés pour aider le personnel à répondre aux appels d’offres. Cet agent est étroitement verrouillé, explique Nathan Cartwright, architecte en chef de l’IA. « Si quelqu’un d’autre lui envoie un message, il le renvoie », précise-t-il. Un prompt système spécifie par ailleurs l’objectif de l’agent, de sorte que tout ce qui n’est pas lié à cet objectif est rejeté. De plus, des garde-fous empêchent toute communication d’informations personnelles et limite le nombre de demandes que l’agent peut traiter.L’observabilité appliquée à l’IAEnsuite, pour s’assurer que ces garde-fous fonctionnent comme attendu, chaque interaction est contrôlée. « Disposer d’une couche d’observabilité pour voir ce qui se passe réellement est essentiel, explique Nathan Cartwright. La nôtre est totalement automatisée. Si une limite de taux ou un filtre de contenu est atteint, un courriel est envoyé pour demander une vérification de l’agent concerné. »Roger Haney, architecte en chef de CDW, estime que le fait de commencer par des cas d’utilisation restreints et ponctuels permet de limiter les risques. « Lorsque vous vous concentrez réellement sur ce que vous essayez de faire, votre domaine est relativement limité, explique-t-il. C’est là que nous voyons les entreprises réussir [avec l’IA agentique]. Nous pouvons rendre l’agent performant, le rendre plus petit. Mais la première chose à faire est de mettre en place les garde-fous appropriés. C’est là que réside la plus grande valeur, plutôt que dans le fait de relier les agents entre eux. Tout part des règles métiers, de la logique interne et de la conformité que l’on met en place dès le départ. »

En travaux depuis 2022, l’initiative de Microsoft EU Data Boundary apportant un cadre pour garantir que les données cloud de ses clients en Europe sont bien stockées et traitées au sein de l’UE est finalisée. Un analyste reconnait que c’est un pas en avant, mais qu’une véritable souveraineté des données n’est pas garantie.
Dans un billet de blog, Microsoft a annoncé l’achèvement de la troisième et dernière phase de son initiative initiative EU Data Boundary. Pour rappel, celle-ci permet à ses utilisateurs européens du secteur commercial et public de stocker et traiter les données personnelles anonymisées de leurs clients pour les principaux services cloud de Microsoft, y compris 365, Dynamics 365, Power Platform et la plupart des services Azure, dans les régions de l’UE et de l’AELE (Association européenne de…
Il vous reste 91% de l’article à lireVous devez posséder un compte pour poursuivre la lecture
Vous avez déjà un compte?

La dernière version de la distribution Kubernetes, Openshift, de Red Hat apporte son lot d’évolutions sur la partie réseau et sécurité. Le support de la segmentation personnalisée et l’intégration avec des systèmes de gestion de secret tiers sont au programme.
Petit à petit, Red Hat étoffe sa plateforme Openshift avec des fonctions réseaux et de virtualisation plus avancées. Pour rappel, la plateforme est la distribution Kubernetes de la filiale d’IBM pour le déploiement des environnements nativement cloud. Dans la version 4.18, l’éditeur a intégré des capacités dédiées au réseau comme la mise en réseau adapté aux machines virtuelles. Cette dernière « fait référence aux améliorations de mise en…
Il vous reste 90% de l’article à lireVous devez posséder un compte pour poursuivre la lecture
Vous avez déjà un compte?
Face au développement de LLMjacking, Microsoft intente un procès à des membres du gang Storm-2139. Une action pour alerter sur le phénomène couplant vol d’identifiants et piratage des services d’IA.
La meilleure défense est souvent l’attaque. Microsoft l’a bien compris concernant la sécurité de ses services d’IA en intentant un procès contre le détournement de ses modèles pour proposer du contenu violent. La cible de son courroux, un gang connu sous le nom Storm-2139 qui a utilisé des identifiants volés, ainsi que des techniques de jailbreaking de l’IA pour créer ses propres services payants. Connues sous le nom de LLMjacking, ce phénomène émerge et entraîne des coûts financiers importants pour les victimes peu méfiantes.
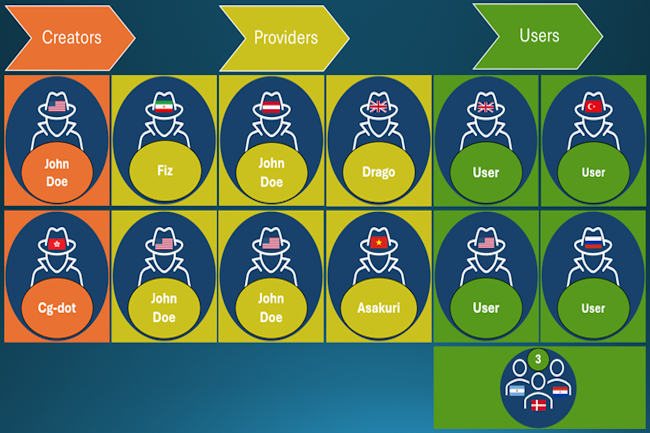
Identification de quatre membres de Storm-2139
« Storm-2139 est organisé en trois groupes principaux : les créateurs, les fournisseurs et les utilisateurs », ont écrit les avocats de la Digital Crimes Unit de Microsoft dans un blog. « Les créateurs ont mis au point les outils illicites qui ont permis d’abuser des services générés par l’IA. Les fournisseurs ont ensuite modifié et fourni ces outils aux utilisateurs finaux, souvent avec différents niveaux de service et de paiement. Enfin, les utilisateurs se sont servis de ces outils pour générer des contenus synthétiques violents, souvent centrés sur des célébrités et des images sexuelles. »
Microsoft a réussi à identifier quatre des dix personnes soupçonnées d’appartenir au gang Storm-2139, à savoir : Arian Yadegarnia, alias « Fiz », d’Iran ; Alan Krysiak, alias « Drago », du Royaume-Uni ; Ricky Yuen, alias « cg-dot », de Hong Kong ; et Phát Phùng Tấn, alias « Asakuri », du Viêt Nam. Cg-dot serait l’un des deux « créateurs », tandis que les trois autres seraient des « fournisseurs » de l’opération criminelle. Deux membres basés aux États-Unis, dans l’Illinois et en Floride ont également été identifiés, mais pour l’instant, Microsoft a indiqué qu’elle gardait ces identités secrètes en raison des enquêtes criminelles en cours.
Entraide entre les membres du gang
En janvier, après avoir annoncé qu’elle intentait une action en justice contre les cybercriminels qui abusent de ses services d’intelligence artificielle, Microsoft a réussi à saisir un site web opérationnel essentiel de Storm-2139. Cette saisie et les documents juridiques non scellés ont immédiatement suscité beaucoup de commentaires sur les canaux de communication utilisés par le gang, les membres et les utilisateurs spéculant sur les identités qui auraient pu être exposées. Les avocats de Microsoft ont aussi vu leurs informations personnelles et leurs photographies partagées. « En conséquence, les avocats de Microsoft ont reçu divers courriels, dont plusieurs émanant de membres présumés de Storm-2139 qui tentaient de rejeter la faute sur d’autres membres de l’opération », a déclaré l’unité de lutte contre la criminalité numérique de Microsoft.
Un coût potentiel élevé pour les entreprises
Le LLMjacking est une continuation de la pratique cybercriminelle consistant à abuser d’identifiants de comptes cloud volés pour mener diverses opérations illégales, comme le cryptojacking, lequel consiste à abuser de ressources cloud piratées pour miner de la crypto-monnaie. La différence réside dans le fait qu’un grand nombre d’appels d’API aux LLM peut rapidement engendrer des coûts considérables, les chercheurs estimant les coûts potentiels à plus de 100 000 dollars par jour lorsqu’ils interrogent des modèles avancés. En septembre dernier, l’éditeur Sysdig a signalé que le nombre de requêtes frauduleuses envoyées aux API de Bedrock d’Amazon avait été multiplié par dix et que le nombre d’adresses IP impliquées dans ces attaques avait doublé.
Le service Bedrock propose aux entreprises de déployer et d’utiliser facilement des LLM provenant de plusieurs entreprises d’IA, de les enrichir de leurs propres ensembles de données et de créer des agents et des applications autour d’eux. Le service prend en charge une longue liste d’actions API pour gérer les modèles et interagir avec eux de manière programmatique. Microsoft livre un service similaire appelé Azure AI Foundry, et Google a l’équivalent Vertex AI. Selon Sysdig, les attaquants ont d’abord abusé des identifiants AWS pour accéder aux modèles Bedrock déjà déployés par les entreprises victimes, mais l’éditeur a ensuite constaté que les attaquants tentaient d’activer et de déployer de nouveaux modèles dans les comptes compromis. Au début du mois, Sysdig a vu que des attaques de LLMjacking ciblaient le modèle DeepSeek R1 quelques jours après sa publication. L’entreprise de sécurité a également découvert plus d’une douzaine de serveurs proxy qui utilisaient des identifiants volés dans de nombreux services différents, notamment OpenAI, AWS et Azure.

Les chemins de fer européens restent encore très repliés sur leur pays d’origine et peu ouverts. Une alliance créée en 2024 par les chemins de fer suisses, la Deutsche Bahn et la SNCF cherche à changer de voie, en adoptant des solutions open source standards en particulier pour l’interopérabilité et la conformité des systèmes.
Une Europe ouverte a besoin de voies de transport ouvertes au-delà des frontières nationales, y compris pour le réseau ferroviaire. C’est pourtant exactement là où le bât blesse. Historiquement, les chemins de fer européens se sont d’abord organisés sur un plan national. L’interopérabilité et l’innovation étaient moins une exigence pendant la construction des réseaux que la durabilité des infrastructures et des systèmes. Pour aggraver les choses, de nombreux systèmes de sécurité ferroviaire sont conçus pour être spécifiques à l’échelle nationale et dépendent fortement des fabricants. Enfin, l’ensemble manque de normalisation, le secteur compte de nombreux acteurs et la plupart rechignent encore à utiliser des solutions venues d’ailleurs.Pour faire bouger les lignes, la Deutsche Bahn, les Chemins de fer fédéraux suisses (CFF), la SNCF et l’Union internationale des chemins de fer (UIC) ont fondé l’an dernier l’Openrail Association (ORA, association internationale de promotion des chemins de fer et de la coopération entre les acteurs du secteur). Elle vise à promouvoir la collaboration et la normalisation au sein de l’industrie ferroviaire, en s’appuyant sur des technologies open source. Les 4 membres fondateurs ont été rejoints par la plateforme de billetterie norvégienne Entur, le gestionnaire belge d’infrastructures Infrabel, les chemins de fer marocains (ONCF) et l’organisation suisse à but non lucratif Flatland de promotion de la recherche ouverte sur le champ de l’optimisation de ressources par l’informatique. L’ensemble des membres d’Openrail cherchent à relever les défis numériques des transports ferroviaires, à promouvoir l’interopérabilité entre les systèmes nationaux et à éviter la dépendance vis-à-vis des fournisseurs (vendor lock-in).L’open source, catalyseur de collaboration ?Pour Jochen Decker, CIO de la CFF, et Nicole Göbel, CEO de DB Systel, filiale digitale de la Deutsche Bahn, présents à la conférence Hamburger IT Strategie entre le 19 et le 21 février à Hambourg, l’open source est idéal pour une telle démarche. Ils rappellent que les compagnies ferroviaires européennes sont souvent confrontées à des défis similaires, mais continuent pourtant d’agir de manière individuelle et peu standardisée. L’open source représenterait ainsi, selon eux, un moyen prometteur d’accroître l’efficacité et de stimuler l’innovation.Les deux représentants d’Openrail mentionnent, en particulier, quatre aspects qui plaident en faveur de l’utilisation de l’open source : la coopération favorisée entre compagnies ferroviaires, fournisseurs et universités ; l’élaboration conjointe de normes et de solutions pour amenuiser les problèmes d’interopérabilité ; le développement et la mise en oeuvre plus rapide de solutions innovantes ; le renforcement de la confiance et la capacité de vérifier le niveau de sécurité par la transparence du code open source.Billetterie, capacity planning ou simplification des réservationsMalgré tout, avec l’open source, des préoccupations persistent quant à la sécurité et la réglementation. La CFF et la Deutsche Bahn considèrent ainsi qu’il est souhaitable de ne l’utiliser, dans un premier temps, que dans les domaines les moins critiques en la matière. La billetterie internationale est ainsi un bon exemple. Grâce à un standard commun et à des API open source, une simplification significative a été réalisée et une grande partie des billets internationaux vendus le sont déjà par ce biais.Openrail travaille sur des projets spécifiques divers, comme le capacity planning, sujet central compte tenu du fort encombrement des réseaux ferroviaires actuels. Celui de la Deutsche Bahn fonctionne ainsi déjà au quotidien à 160 % de sa capacité. Il est important de développer une solution de capacity planning plus efficace afin de devenir plus résilient. L’association étudie aussi la gestion des actifs et des infrastructures, c’est-à-dire l’utilisation plus efficace des locomotives, des voitures et des wagons, etc. Elle souhaite aussi simplifier davantage la planification et la réservation de voyages.Sans oublier le fret et le rapprochement IT/OTUn autre objectif est de collaborer avec des fabricants – comme l’allemand Siemens – pour élaborer des normes et stimuler l’innovation. C’est notamment le cas des postes d’aiguillage, qui doivent être renouvelés et numérisés. En Allemagne, certains postes de signalisation sont encore basés sur la technologie des relais de l’époque impériale ! Et la 2G est encore en partie utilisée comme technologie radio pour la sécurité ferroviaire. Openrail veut maintenant établir des normes pour l’avenir numérique dans tous ces domaines.Enfin, la collaboration au sein de l’association ne concerne pas que le transport de voyageurs. La numérisation du transport de marchandises est aussi un chantier majeur. « Aujourd’hui, le couplage des wagons fonctionne toujours comme il y a 150 ans », raconte Jochen Decker. Le développement d’un attelage automatique numérique entre wagons, ou entre wagons et locomotives, pour le transport de marchandises, est ainsi à l’étude. Enfin, comme d’autres secteurs, le ferroviaire fait face à une convergence croissante entre IT et l’OT. Un rapprochement de plus en plus important qui nécessite également de nouvelles normes et architectures pour assurer l’interopérabilité souhaitée.La SNCF débute avec un jumeau numériqueEn janvier 2025, dans un communiqué annonçant son investissement dans OpenRail, la SNCF évoquait ses travaux sur le jumeau numérique d’exploitation ferroviaire Open Source Railway Designer (OSRD). L’occasion pour l’opérateur français de collaborer avec d’autres européens. « Cette coopération nous a donné l’idée de créer une structure dédiée au développement de logiciels européens open source spécifiques au secteur ferroviaire, raconte dans le communiqué Loïc Hamelin, directeur du premier programme open source ferroviaire chez SNCF Réseau. C’est ainsi qu’est née l’Openrail Association ».

Dans le cadre de son deuxième plan de transformation numérique, l’industriel espagnol du pétrole, du gaz et de la pétrochimie Repsol mise en particulier sur la GenAI. Il a créé un Generative AI Competence Center, focalisé sur les outils, les cas d’usage et les méthodes de travail associées.
Basé à Madrid, l’industriel de l’énergie et de la pétrochimie Repsol est plongé depuis des années dans un processus de transformation numérique pour diversifier les énergies qu’il propose et se recentrer sur ses clients. Une orientation détaillée dans son plan stratégique actualisé pour la période 2023-2027, qui décrit également son engagement en faveur de la transition énergétique et de la décarbonation et souligne l’importance du numérique pour atteindre ces objectifs.Après un premier programme de transformation numérique de 4 ans, entre 2018 et 2022, l’industriel en a démarré un deuxième se déployant sur 7 axes : la sécurité et la fiabilité accrues dans les opérations, la planification et la programmation intelligentes, l’excellence dans les opérations numérisées, le développement d’actifs optimisés numériquement, l’expérience client omnicanale et data driven, l’innovation dans les nouveaux business models et l’agilité de l’organisation. À ce jour, Repsol travaille sur 670 cas d’usage correspondant à ces critères, dont 400 soutenus par l’IA. Un peu plus d’un tiers sont prêts pour une mise en production. Parmi ces derniers, trois sur cinq répondent directement ou indirectement à des objectifs de décarbonation de l’activité.Un centre de compétence en GenAIDepuis 2018, Repsol a mis progressivement l’accent sur les data et l’IA dans l’ensemble de son organisation. Dans le cadre de son prochain plan de transformation, l’entreprise affirme l’importance de la GenAI, un tournant en matière de recherche de productivité, selon elle. C’est ainsi qu’est né, en juin 2023, son Generative AI competence center, créé en collaboration avec Microsoft, initiative pionnière dans le secteur européen de l’énergie selon Repsol.Ce centre travaille sur différents sujets autour de l’IA générative. Il dispose par exemple d’un laboratoire pour explorer les nouvelles méthodes de travail. « Nous avons ainsi étendu l’utilisation de Microsoft Copilot dans l’entreprise, ce qui a permis de gagner du temps, d’améliorer la qualité et d’augmenter le temps passé par les employés sur des tâches à plus forte valeur ajoutée », explique María Ángeles Arroyo, responsable du centre de compétences en IA générative.Ce centre dispose aussi d’une digital case factory, qui identifie et implémente des cas d’usage de GenAI susceptibles de générer de la valeur pour l’industriel. À l’heure actuelle, plus de 55 projets ont déjà été déployés dans toute l’entreprise. C’est le cas de SafePlay, qui génère automatiquement de l’information sur la sécurité à partir d’un historique des incidents, ou encore de Harvey, qui analyse des documents juridiques ou compare des contrats et des normes. Ensuite, le generative code development lab cherche des moyens d’accélérer le processus de développement de logiciels, d’améliorer leur qualité et d’augmenter la productivité dégagée. « Nous avons évalué la façon dont GitHub Copilot peut aider les développeurs à générer du code, avec plus de 1,1 million de lignes dans 20 langages de programmation différents », illustre María Ángeles Arroyo.Un travail avec d’autres entreprises sur l’IA responsableEnfin, le Responsible AI group élabore et met en place des mécanismes qui assurent que les modèles déployés sont responsables et sûrs. « Dans le cadre de notre deuxième plan numérique, nous avons collaboré sur ce sujet avec d’autres entreprises au sein de groupes de travail dédiés, ajoute María Ángeles Arroyo. Nous fixons aussi des principes directeurs conformes à l’AI Act européen et nous avons défini un modèle de gouvernance pour une utilisation légale, responsable et agile de la GenAI. »Après un an de travail, Repsol a ajouté d’autres axes de travail à ses initiatives GenAI. Il a ainsi défini des plans basées sur la technologie systématiques pour chaque business unit et créé un Business and productivity impact office pour identifier, mesurer et piloter l’impact de la GenAI. L’industriel a aussi mis en place une formation structurée pour faciliter l’adoption de la technologie et établi une définition des interactions entre utilisateurs et applications ‘centrées sur l’humain’.Le Generative AI Competence Center a eu un impact majeur sur les équipes et la culture d’entreprise. Durant 4 mois, Repsol a expérimenté une utilisation de Copilot M365. L’évaluation de l’impact ? Un gain de temps moyen de 121 minutes par semaine et par personne sur les tâches routinières, soit plus de 96 heures par an et par employé. De plus, la qualité des livrables a augmenté de 16%, selon des critères liés à l’originalité et à l’esprit critique. Enfin, environ 62% des utilisateurs ont déclaré ne plus vouloir travailler sans Copilot.
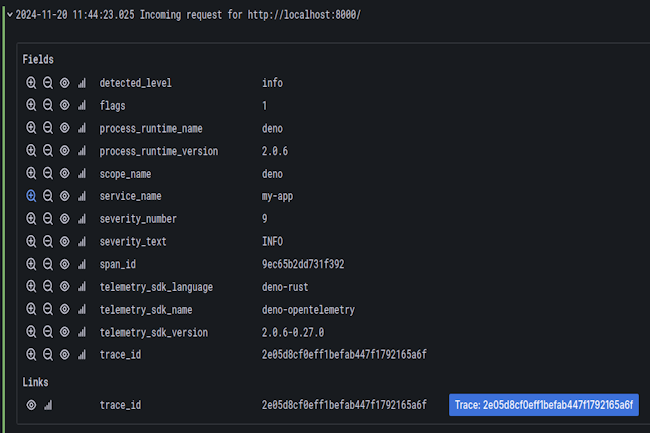
La mise à jour de Deno intègre OpenTelemetry pour la surveillance des logs, des métriques et des traces, et inclut une mise à jour majeure du linter Deno.
Annoncée le 19 février, la dernière version du runtime Deno pour JavaScript et TypeScript publiée par Deno Land s’intéresse au monde l’observabilité. Elle embarque le projet open source OpenTelemetry de la CNCF (Cloud Native Computing Foundation). Dans ce cadre, Deno 2.2 instrumente automatiquement les API telles que console.log, Deno.serve et fetch. Les développeurs peuvent analyser leur propre code en utilisant npm:@opentelemetry/api. Pour capturer des données d’observabilité, les utilisateurs devront fournir un point de terminaison du protocole OpenTelemetry (OTLP). Pour les environnements de développement et de test, Deno Land suggère d’utiliser l’image Docker LGTM de Grafana.
Deno 2.2 introduit par ailleurs une mise à jour majeure de deno lint, qui apporte un autre système de plugins et 15 règles particulièrement destinées aux utilisateurs de React et Preact. Les règles incluent jsx-boolean-value, jsx-button-has-type, jsx-curly-braces, jsx-key, jsx-no-children-prop, jsx-no-comment-text-nodes, jsx-no-duplicate-props, jsx-no-unescaped-entities, jsx-no-useless-fragment, jsx-props-no-spread-multi, jsx-void-dom-elements-no-childrenrenrename, no-useless-rename, react-no-danger-with-children, react-no-danger, et react-rules-of-hooks.
Optimisation de la mémoire et mise à jour des dépendances améliorée
Pour améliorer les performances, Deno 2.2 efface désormais les informations relatives à l’analyse des modules après un délai d’attente. Selon les responsables de Deno Land, cette fonction réduit la consommation de mémoire. Par ailleurs, Deno.stat et node:fs.stat sont dorénavant jusqu’à 2,5 fois plus rapides sous Windows. De plus, la résolution des modules Node.js est plus rapide en limitant les conversions entre les URL et les chemins d’accès.
« Deno 2.2 modifie l’outil obsolète deno par l’ajout d’une méthode interactive de mise à jour des dépendances », a déclaré l’éditeur. Cette version améliore un peu plus la compatibilité avec Node.js et NPM, par exemple en rendant possible la découverte des fichiers .npmrc dans le répertoire personnel et le répertoire du projet.
D’autres évolutions
Parmi les autres apports de Deno 2.2, on peut citer :
– Un module node:sqlite très demandé qui facilite le travail avec des bases de données en mémoire ou locales.
– Les améliorations qui rendent deno lsp plus rapide et plus réactif, avec des avancées majeures pour les utilisateurs de frameworks web.
– Plus de précision de L’outil deno bench, pour l’évaluation du code.
– Les outils deno check pour la vérification des types respectent désormais les balises JSDoc et permettent de configurer les options du compilateur par membre de l’espace de travail.
– Des améliorations de performance et de qualité de vie ont été apportées à deno compile, qui est maintenant plus petit et plus rapide.
– La mise à jour vers TypeScript 5.7.
– Une nouvelle implémentation de WebGPU devrait améliorer les performances des API disponibles.
Les utilisateurs actuels peuvent installer Deno 2.2 en exécutant la commande deno upgrade. Les instructions pour les nouvelles installations sont disponibles ici.

Vos coûts liés au cloud montent en flèche ? Il est probable qu’au moins l’une des raisons de cette inflation réside au sein même de votre organisation.
Personne ne souhaite gaspiller de l’argent dans le cloud. Mais en n’abordant pas pleinement une poignée de questions fondamentales, de nombreux responsables IT dépensent, en services cloud, des fonds qui pourraient être utilisés plus utilement pour soutenir d’autres projets et initiatives. Voici un bref aperçu des raisons pour lesquelles les dépenses liées au cloud sont souvent mal gérées.1. Mauvaise gestion et optimisation des ressourcesLes coûts excessifs du cloud en entreprise sont généralement le résultat d’une gestion inefficace des ressources et d’un manque d’optimisation. Selon Shreehari Kulkarni, consultant au sein du cabinet d’analyse et de conseil ISG, les ressources sous-utilisées et/ou surprovisionnées sont parmi les principales causes des coûts élevés du cloud.« Les entreprises achètent souvent des ressources – telles que des instances de calcul, du stockage ou de la capacité de base de données – qui ne sont pas entièrement utilisées et, par conséquent, elles paient pour davantage de services que ce dont elles ont réellement besoin », explique-t-il. De nombreuses entreprises surestiment également les ressources nécessaires au support d’un projet ou d’une application, ce qui les conduit à provisionner des instances plus grandes, donc plus coûteuses, que le besoin réel, entraînant ainsi un surprovisionnement.Shreehari Kulkarni estime qu’une gestion inefficace des ressources peut généralement être attribuée à la fois au client et au fournisseur. Les fournisseurs de services cloud sont généralement responsables de certaines tâches, telles que la fourniture d’outils appropriés pour la gestion des coûts, les prévisions de dépenses, l’analyse de celles-ci et la transparence sur les coûts. Cependant, il incombe principalement aux entreprises d’exploiter efficacement ces outils et analyses tout en déployant des pratiques d’optimisation des coûts, passant par un renforcement de la gouvernance, le soutien de la direction ou encore la mise en oeuvre de politiques spécifiques en interne.Selon le consultant, la gestion des coûts du cloud est essentiellement une responsabilité partagée entre l’entreprise et le fournisseur. « Les entreprises doivent rester proactives et optimiser en permanence leur infrastructure cloud, tandis que les fournisseurs doivent continuer à améliorer leurs outils et l’assistance qu’ils fournissent en la matière. »2. Les dépenses imprévues liées à l’IAL’un des défis les plus récents et les plus importants en matière de coûts du cloud ? Apprendre à gérer correctement les modèles et les agents d’IA qui y sont déployé. « Les développeurs d’applications peuvent ne pas tenir compte de la mémoire et des exigences de traitement requises pour faire fonctionner des modèles d’IA privés dans des services cloud », explique Troy Leach, directeur de la stratégie de la Cloud Security Alliance, une organisation à but non lucratif qui promeut l’utilisation des meilleures pratiques dans le cloud. « J’ai ainsi entendu parler de cas où des sociétés de conseil ont été appelées pour optimiser l’utilisation de modèles d’IA parce que le coût des ressources a augmenté de centaines de milliers de dollars du fait d’un manque de planification en amont. »3. Une mauvaise stratégie de transformation numériqueLes coûts excessivement élevés du cloud proviennent souvent d’inefficacités nées des initiatives de transformation numérique, pointe Bakul Banthia, co-fondateur de Tessell, un fournisseur de database-as-a-service. Migrer vers le cloud sans comprendre pleinement les exigences de telle application ou les besoins d’optimisation des architectures de base de données peut conduire à un surprovisionnement et à une dispersion des ressources, prévient-il. « À mesure que les entreprises se modernisent, l’intégration d’outils qui surveillent et gèrent les coûts des environnements multicloud ou hybrides devient essentielle pour maintenir les dépenses à un niveau raisonnable », ajoute Bakul Banthia.Les fournisseurs et les clients jouent tous deux un rôle dans une planification efficace. « Au cours de leurs programmes de transformation numérique, les entreprises clientes peuvent sous-estimer la complexité de la gestion des ressources cloud, ce qui conduit à des inefficacités, explique Bakul Banthia. Les fournisseurs, quant à eux, enferment parfois les clients dans des modèles de tarification ou des services spécifiques dont il est coûteux de sortir. » D’où l’importance d’une flexibilité planifiée en évitant de trop s’engager dans l’écosystème d’un seul fournisseur.4. Verrouillage des fournisseurs et absence de réévaluation régulièreLorsque l’on compare les coûts du cloud, il est important d’évaluer non seulement le prix initial, mais aussi des facteurs de long terme tels que l’efficacité opérationnelle et le risque de verrouillage à l’offre du fournisseur. « Évaluez si les applications peuvent être facilement déplacées d’un fournisseur à l’autre ou passées à l’échelle sur différentes plateformes, conseille Bakul Banthia. Utilisez des simulations de workloads et analysez le coût total de possession selon différents scénarios afin d’obtenir une image claire des solutions les plus rentables. »Les services cloud devraient être réévalués au moins une fois par trimestre, en particulier lors du déploiement des programmes de transformation numérique, lorsque les workloads et les besoins en infrastructure évoluent rapidement, recommande le co-fondateur de Tessell. « Des audits réguliers permettront de découvrir des coûts cachés, tels que des ressources orphelines ou des bases de données sous-utilisées, observe-t-il. Cela garantit que l’adaptation des stratégies cloud en temps réel, réduisant ainsi le risque de dépenses inutiles ou de dépendance à l’égard de services peu flexibles. »5. Absence de stratégie cloud clairement définieL’absence d’un plan clair pour le déploiement, la maintenance et l’expansion du cloud est l’une des principales causes de l’augmentation des dépenses. « En l’absence d’une stratégie bien définie et fiable, les coûts peuvent rapidement devenir incontrôlables », dit Karina Myers, responsable de la pratique workplace chez Centric Consulting. « Cela est particulièrement vrai lorsqu’une analyse approfondie du coût total de possession et des FinOps n’a pas été menée afin de maximiser la valeur métier des investissements dans le cloud et permettre une prise de décision opportune et fondée sur des données. »Une stratégie cloud bien définie fournira une justification métier solide en évaluant les implications financières ainsi que les motivations clés et les résultats commerciaux attendus, explique Karina Myers. « Cette approche stratégique doit guider les dirigeants tout au long de leur parcours de transformation vers le cloud, en garantissant une prise de décision éclairée et un alignement sur les objectifs de l’organisation. »La cadre de Centric Consulting insiste également sur la nécessité d’établir des fondations solides supportant à la fois les besoins de déploiement immédiats et futurs. « Ce socle doit prendre en compte les exigences de sécurité, la gouvernance du cloud, la conformité réglementaire, la continuité des activités et les normes d’automatisation, afin de garantir un environnement technique complet et durable. »6. Un alignement et une gestion médiocresIl y a quelques années, lorsque les entreprises investissaient dans leurs propres datacenters et les exploitaient, il était relativement facile d’aligner les opérations sur la stratégie de l’entreprise. « Il est important de traiter votre infrastructure cloud avec le même soin, c’est-à-dire en l’alignant et en la gérant en fonction des objectifs et des résultats de l’entreprise », souligne Gerry Leitão, vice-président pour les services cloud managés chez l’éditeur de logiciels spécialisés dans les statistiques SAS.Gerry Leitão recommande une approche du cloud à la fois centralisée et fédérée. « Il est important d’établir des garde-fous en termes d’utilisation afin que les équipes puissent rester conformes aux règles de gouvernance du cloud établies par l’organisation, conseille-t-il. Si vous comprenez les habitudes de consommation du cloud de votre entreprise et que vous optimisez son utilisation de manière réfléchie, vous pourrez l’ajuster en fonction des besoins de l’entreprise sans vous retrouver confronté à une facture exorbitante. »7. SurprovisionnementLes entreprises surprovisionnent souvent les services cloud sans procéder au préalable à des évaluations appropriées, souligne Ankush Mathur, directeur technique chez Techuz.com, société de développement d’applications web et mobiles personnalisées. « Optimiser les ressources en fonction des besoins réels de l’application est essentiel pour éviter de mettre en place des ressources surdimensionnées », ajoute-t-il.Selon Ankush Mathur, les instances réservées proposées par les fournisseurs de cloud peuvent réduire les coûts de 20 à 40%. « La surveillance régulière des services peut aider à identifier les ressources inutiles qui peuvent être éliminées, note-t-il. En outre, la définition d’un seuil dans la mise à l’échelle automatique permet d’éviter les augmentations brutales de coûts pendant les opérations de passage à l’échelle. »Les coûts excessifs résultent souvent d’une mauvaise gestion de la part des entreprises, provenant des ressources mal configurées, d’un manque de compréhension des modèles de tarification ou de mauvaises stratégies d’optimisation. « Et les fournisseurs peuvent y contribuer indirectement en proposant des structures de facturation complexes », ajoute le CTO de Techuz.com.Un monitoring inefficace du cloud peut aussi entraîner des frais inutiles, prévient Ankush Mathur. « Par exemple, certaines applications de commerce électronique augmentent la taille de leurs serveurs le jour du Black Friday, mais oublient de les réduire par la suite, ce qui entraîne des dépenses inutiles. »8. Choisir le mauvais fournisseur de cloudSelon Lenley Hensarling, conseiller technique chez Aerospike, fournisseur de bases de données NoSQL, les dépenses excessives liées au cloud sont souvent dues à la structure des coûts du fournisseur choisi. « Ce problème survient lorsque les entreprises supposent que les prix sont uniformes chez tous les fournisseurs ou pensent que les systèmes existants peuvent être migrés sans ajustements, observe-t-il. Pour éviter les dépenses inutiles, il est important de concevoir une solution en comprenant clairement les besoins spécifiques de l’application afin de les aligner sur l’architecture du fournisseur de cloud. »Et l s’agit là d’une responsabilité qui incombe généralement à l’entreprise cliente. « Si les fournisseurs établissent des modèles de tarification complexes, il incombe aux clients de comprendre ces modèles et de concevoir les applications en conséquence », explique Lenley Hensarling. « Le fait de négliger des facteurs tels que les frais de transfert de données ou les remises au volume conduit souvent à des dépenses excessives. »Selon lui, l’atteinte d’une réduction des coûts avec le cloud nécessite une approche stratégique. « Commencez par analyser vos workloads et sélectionnez le fournisseur qui leur convient le mieux ». En ce qui concerne les systèmes existants, il peut donc s’avérer nécessaire de revoir la conception de certains composants. « Dans les configurations hybrides et multiclouds, alignez les workloads sur les points forts et les modèles de tarification de chaque environnement tout en minimisant les coûts de transfert de données entre plateformes », conseille-t-il.
À quel point vos données stockées sur iCloud sont-elles sécurisées par Apple ?
Avec toute la communication d’Apple autour de la confidentialité et toutes les discussions récentes sur la surveillance gouvernementale à travers le monde, on pourrait espérer que les données de tous vos services cloud Apple soient verrouillées de manière sécurisée. Vous pourriez être surpris d’apprendre qu’une grande partie de ces données, selon les paramètres que vous choisissez, n’est pas aussi sécurisée que vous pourriez le penser. Ici, nous allons expliquer la différence entre les deux…
Il vous reste 97% de l’article à lireVous devez posséder un compte pour poursuivre la lecture
Vous avez déjà un compte?