






Des chercheurs en sécurité d’Oligo ont découvert une vulnérabilité critique affectant les grands modèles de langage LLama de Meta. Elle ouvre la voie à l’exécution de code arbitraire distant en envoyant des données malveillantes désérialisées.
La sécurité de l’IA devient un sujet préoccupant avec des techniques en pleine évolution. Preuve en est la faille critique trouvée dans le LLM Llama de Meta pouvant entraîner des attaques RCE (remote code execution). Elles peuvent engendrer sur du vol et de la compromission de données, voire aller jusqu’à de la prise de contrôle de LLM. Répertorié en tant que CVE-2024-50050, ce trou de sécurité lié découle de l’utilisation inappropriée de la bibliothèque open source orientée message (pyzmq) dans les frameworks d’IA.
« L’équipe de recherche d’Oligo a découvert une vulnérabilité critique dans meta-llama, un framework open source de Meta pour construire et déployer des applications GenAI », ont déclaré les chercheurs en sécurité d’Oligo dans un billet de blog. « La faille, CVE-2024-50050, permet aux attaquants d’exécuter un code arbitraire sur le serveur d’inférence llama-stack depuis le réseau. » Selon les chercheurs du fournisseur en solutions de sécurité, un certain nombre de frameworks d’IA open source exploitent une bibliothèque open source orientée message (pyzmq) d’une « manière peu sûre », permettant l’exécution de code à distance. Le problème vient du fait que Llama Stack utilise pickle, un module Python pour la sérialisation et la désérialisation d’objets Python, dans son implémentation « inference API », une fonctionnalité que Llama propose aux entreprises pour intégrer leurs propres modèles ML dans le pipeline applicatif.
Une faille signalée et corrigée par Meta
Pickle est intrinsèquement capable d’exécuter des codes arbitraires lors de la désérialisation de données non fiables (crafts) envoyées par des attaquants, en particulier avec la mise en œuvre exposée de pyzmq (une liaison Python pour ZeroMQ). « Dans les scénarios où le socket ZeroMQ est exposé sur le réseau, les attaquants pourraient exploiter cette vulnérabilité en envoyant des objets malveillants élaborés au socket », ont déclaré les chercheurs, ajoutant que l’unpickling de ces objets [conversion de fichier binaire en objets Python, ndlr] pourrait donner aux attaquants la capacité de réaliser une exécution de code arbitraire (RCE) sur la machine hôte. Suite à cette découverte, l’équipe de sécurité de Meta a rapidement patché Llama Stack, en changeant le format de sérialisation pour la communication socket de pickle à JSON.
Oligo Research a signalé la vulnérabilité à Meta le 29 septembre 2024, qui l’a ensuite reconnue et publié un correctif sur GitHub le 10 octobre 2024, avec une version corrigée 0.0.41 poussée sur l’index de package Python (PyPi). Le 24 octobre dernier, Meta l’a ensuite identifiée en tant que CVE-2024-50050 avec un score CVSS de 6,3 (gravité moyenne). De son côté Snyk, spécialisé dans la sécurité du développement logiciel, a reconnu une plus grande dangerosité de ce trou de sécurité en lui attribuant un score CVSS critique de 9,3 pour la version 4.0 de Llama Stack et même de 9,8 pour la v3.1.
Meta n’a pas répondu à CSO aux demandes de précision su la gravité de la faille jusqu’à la publication de cet article. La vulnérabilité est actuellement en attente d’analyse par la National Vulnerability Database (NVD), un référentiel complet de vulnérabilités divulguées publiquement, géré par le NIST.

Le code généré par l’IA se généralise, y compris dans les endroits où son utilisation est officiellement interdite, introduisant au passage de nouveaux risques. Voici ce que les RSSI peuvent faire pour s’assurer qu’il ne compromet pas la sécurité de l’organisation.
En 2023, l’équipe de la start-up spécialisée dans l’extraction de données Reworkd était soumise à des délais serrés. Les investisseurs entendaient monétiser la plateforme et, pour ce faire, l’équipe devait au préalable migrer de Next.js à Python/FastAPI. Pour accélérer les choses, elle a alors décidé de confier une partie du travail à ChatGPT. Le code généré par l’IA semblait fonctionner, a donc été implémenté directement dans l’environnement de production.Le lendemain matin, une mauvaise surprise attendait l’équipe de Reworkd : « plus de 40 notifications Gmail de plaintes d’utilisateurs, écrit le cofondateur de la start-up Ashim Shrestha dans un post de blog. Tout semblait avoir pris feu pendant la nuit. Aucun de ces utilisateurs ne pouvait s’abonner. »Un bogue sur la ligne 56, générée par l’IA, a provoqué une collision d’identifiant unique au cours du processus d’abonnement, et il a fallu cinq jours pour identifier le problème et le résoudre. Ce bogue, cette « simple erreur de ChatGPT nous a coûté plus de 10 000 dollars », souligne Ashim Shrestha.Bibliothèques hallucinéesSi Reworkd a révélé ouvertement son erreur, de nombreux incidents similaires passent sous les radars. Les RSSI en prennent souvent connaissance dans une réunion à huis clos. Les institutions financières, les systèmes de santé et les plateformes de commerce électronique ont tous rencontré des problèmes de sécurité, car les outils de complétion de code à base d’IA peuvent introduire des vulnérabilités, perturber les opérations ou compromettre l’intégrité des données. De nombreux risques sont associés au code généré par l’IA, des noms de bibliothèques résultant d’hallucinations à l’introduction de dépendances tierces non suivies et non vérifiées. « Nous sommes confrontés aux conditions idéales de déclenchement d’une crise : une dépendance croissante au code généré par l’IA, une croissance rapide des bibliothèques Open Source et la complexité inhérente de ces systèmes, souligne Jens Wessling, directeur technique de l’éditeur Veracode. Il est tout à fait naturel que les risques de sécurité augmentent. »De plus, les outils de complétion de code tels que ChatGPT, GitHub Copilot ou Amazon CodeWhisperer sont fréquemment utilisés en cachette. Une enquête menée par Snyk montre qu’environ 80 % des développeurs font fi des politiques de sécurité de leur organisation, pour intégrer du code généré par l’IA. Cette pratique crée des angles morts au sein des entreprises, ces dernières peinant à atténuer les risques ainsi créés et les problèmes juridiques qui en résultent.A mesure que l’adoption des outils de codage automatisé progresse fortement, la discussion sur les risques qu’ils posent est devenue une priorité absolue pour de nombreux RSSI et responsables de la cybersécurité. Si ces outils sont peuvent accélérer le développement, ils posent également divers problèmes de sécurité, dont certains sont difficiles à détecter.S’assurer que les packages logiciels sont identifiés« Le code généré par l’IA se confond souvent avec le code développé par l’homme, ce qui rend difficile l’identification des risques de sécurité », explique Jens Wessling. Parfois, le code généré automatiquement peut inclure des bibliothèques tierces ou des dépendances masquées, c’est-à-dire des dépendances qui ne sont pas explicitement déclarées. Ces packages logiciels passant sous le radar peuvent échapper aux analyses de code. Or, ils renferment potentiellement des vulnérabilités, sans oublier le nécessaire suivi des patchs de sécurité de ces composants.L’une des solutions consiste à utiliser des outils d’analyse de la composition des logiciels (SCA, Software composition analysis) et de sécurité de la supply chain logicielle, qui permettent d’identifier les bibliothèques utilisées, les vulnérabilités et les éventuels problèmes juridiques et de conformité que ces exploitations peuvent entraîner. « Un SCA bien réglé proposant une analyse en profondeur peut être une solution », dit Grant Ongers, CSO et cofondateur de Secure Delivery. Une solution cependant imparfaite. « Le plus gros problème, c’est que les SCA tendent à inclure des vulnérabilités dans des fonctions de bibliothèques qui ne sont jamais appelées », ajoute-t-il.Le rapport 2024 Dependency Management Report d’Endor Labs souligne que 56 % des vulnérabilités signalées dans les bibliothèques se trouvent dans des dépendances ‘fantômes’ pour les organisations. « Les outils doivent pouvoir donner aux équipes de sécurité une visibilité sur tous les composants logiciels utilisés à des fins de conformité et de gestion des risques », indique Darren Meyer, ingénieur de recherche chez Endor Labs.C’est pourquoi il est important que les organisations disposent d’un inventaire précis de leurs composants logiciels. « Sans cet inventaire, il est impossible d’identifier, et encore moins de gérer, les risques liés aux bibliothèques d’IA ou à toute autre bibliothèque tierce, reprend Darren Meyer. Si vous n’avez pas de moyen d’identifier les bibliothèques d’IA – intégrant des logiciels écrits, publiés et/ou consommés par votre organisation -, alors vous faites potentiellement face à un risque de conformité. »Surveiller les modèles ML communautairesLes organisations s’exposent également à des risques lorsque les développeurs téléchargent des modèles d’apprentissage machine (Machine Learning) ou des jeux de données à partir de plateformes communautaires comme Hugging Face. « Malgré les contrôles de sécurité effectués en entrée et en sortie, il peut arriver que le modèle contienne une porte dérobée qui devient active une fois le modèle intégré », explique Alex Ștefănescu, développeur de logiciels libres au sein de l’Organized Crime and Corruption Reporting Project (OCCRP). « Ce qui peut déboucher sur une fuite de données de l’entreprise exploitant ces modèles malveillants. » Début 2024, la plateforme Hugging Face hébergeait au moins 100 modèles ML malveillants, dont certains étaient capables d’exécuter du code sur les machines des victimes, selon un rapport de JFrog.En ce qui concerne les outils de complétion de code comme GitHub Copilot, Alex Ștefănescu s’inquiète des hallucinations. « Un LLM générera toujours la suite la plus statistiquement probable d’un prompt donné, il n’y a donc aucune garantie réelle qu’il générera un vrai paquet issu de PyPI (le dépôt officiel des codes Python, NDLR) par exemple, après le mot ‘import’. Certains attaquants en sont conscients et enregistrent des noms de paquets sur des plateformes telles que npm (gestionnaire de paquets pour Node.js, NDLR) et PyPI, en remplissant certaines fonctionnalités suggérées par les outils de complétion de code afin de donner l’impression que ces paquets sont légitimes. » Importés dans des applications exploitées en production, ces paquets peuvent évidemment causer de sérieux dommages.Pour faire face à ces risques, les RSSI peuvent établir des protocoles de téléchargement et d’intégration de modèles de ML ou de jeux de données à partir de plateformes externes telles que Hugging Face. Il s’agit notamment de mettre en oeuvre des outils d’analyse automatisée afin de détecter les codes malveillants ou les portes dérobées, de bâtir une politique n’autorisant que les modèles provenant d’éditeurs vérifiés, ou d’effectuer des tests internes dans des environnements isolés.Fuite d’information via les assistants de développementPrès de la moitié des organisations sont préoccupées par les systèmes d’IA qui apprennent et reproduisent des schémas intégrant des informations sensibles, selon l’enquête Voice of Practitioners 2024 de GitGuardian. « C’est particulièrement inquiétant car ces outils suggèrent du code basé sur des modèles entraînés sur des données pouvant, par inadvertance, inclure des informations d’identification codées en dur, par exemple », explique Thomas Segura, auteur de l’enquête chez GitGuardian.Bien qu’il n’y ait pas de solution miracle, les entreprises peuvent prendre quelques mesures pour réduire ce risque. « L’utilisation de systèmes d’IA auto-hébergés, qui ne renvoient pas de données, est une solution efficace », souligne Grant Ongers (Secure Delivery).Les développeurs, mais aussi les équipes data, marketing, etc.Les outils basés sur l’IA ne sont pas uniquement exploités par des équipes composées d’ingénieurs logiciels. « Nous constatons qu’un grand nombre d’outils sont adoptés par les analystes de données, les équipes marketing, les chercheurs, etc. », explique Darren Meyer (Endor Labs).Ces équipes ne développent pas leurs propres logiciels, mais écrivent de plus en plus d’outils assez simples qui exploitent des bibliothèques et des modèles d’IA, de sorte qu’elles ne sont souvent pas conscientes des risques encourus. « Cette combinaison de l’ingénierie de l’ombre et d’une sensibilisation à la sécurité applicative inférieure à la moyenne peut constituer un terrain propice à l’explosion des risques », ajoute Darren Meyer.Pour s’assurer que ces équipes travaillent en toute sécurité, les RSSI doivent nouer des relations avec elles dès le début du processus. Autre piste : la mise en place de programmes de formation adaptés à ces équipes afin de les sensibiliser aux risques potentiels qu’embarquent les outils à base d’IA et les bibliothèques logicielles. « Plutôt que de payer des abonnements à des outils de complétion de code, le secteur devrait investir dans le développement des connaissances de son personnel », tranche Alex Ștefănescu (OCCRP).Des budgets pour la sécurité applicative« Les budgets de sécurité n’augmentent généralement pas au même rythme que le développement de logiciels, et l’adoption de l’IA ne fait que creuser ce fossé », reprend Darren Meyer. La sécurité applicative est donc sous-financée dans la plupart des organisations, alors que l’adoption de l’IA et le développement assisté accélèrent le rythme de création de logiciels. « Un portefeuille d’outils de sécurité de haute qualité aidant à combler ce fossé n’est plus optionnel, pense Darren Meyer. Et si les outils sont essentiels, il en va de même pour le personnel AppSec et ProdSec à même de collaborer efficacement avec les développeurs – y compris les profils atypiques – et comprendre les implications techniques, celles en matière de conformité et de sécurité de l’IA. »Lorsqu’il s’agit d’obtenir des ressources suffisantes pour protéger les systèmes à base d’IA, certains interlocuteurs au sein des organisations peuvent hésiter, considérant qu’il s’agit d’une dépense facultative plutôt que d’un investissement essentiel. « L’adoption de l’IA est un sujet qui divise de nombreuses organisations, certains dirigeants et équipes y étant tout à fait favorables, tandis que d’autres y sont fermement opposés, explique Darren Meyer. « Cette tension peut représenter un défi pour les RSSI et responsables de la sécurité des informations métier. »Les RSSI qui sont conscients des avantages et inconvénients de cet équilibre peuvent essayer de mettre en place des contrôles pour gérer les risques de manière efficace, mais cela peut donner l’impression qu’ils veulent l’innovation s’ils n’expliquent pas correctement leur démarche.L’IA modifiant les pratiques d’écriture de code, l’industrie navigue sur une ligne de crête entre adoption d’une technologie riche en promesses et atténuation des risques qu’elle peut poser. Selon Grant Ongers, le plus important, est d’éviter les deux extrêmes : « soit une dépendance excessive à l’égard d’une IA imparfaite, soit l’ignorance totale de l’IA ».La bibliothèque de Babel est alimentée par l’IAAvec plus de cinq millions de bibliothèques Open Source disponibles aujourd’hui et environ un demi-milliard d’autres, selon des estimations, qui seront publiées au cours de la prochaine décennie, dont beaucoup seront alimentées par l’IA, les organisations sont confrontées à un défi sans précédent dans la gestion des risques de sécurité associés à leurs écosystèmes logiciels.« La communauté entre dans un territoire inconnu, et je pense que les risques doivent être abordés au niveau de l’industrie dans son ensemble pour garantir la sûreté, la sécurité et la qualité des logiciels qui alimentent notre environnement », fait valoir Jens Wessling, directeur technique de l’éditeur Veracode.La manière dont ces questions seront abordées est également importante. À l’heure actuelle, il y a une explosion de fournisseurs de sécurité qui prétendent sécuriser l’IA. Pour des résultats plus ou moins probants. En conséquence, « les organisations peuvent se retrouver sans la visibilité nécessaire pour prendre des décisions éclairées en matière de gestion des risques, et sans les capacités pour agir en fonction de ces décisions », explique Darren Meyer, ingénieur de recherche chez Endor Labs. « Les RSSI ne veulent pas se retrouver dans la situation où ils doivent développer de nouvelles capacités alors qu’une faille a fait la une des journaux – ou pire, lorsque c’est leur organisation qui a été victime de cette faille. »
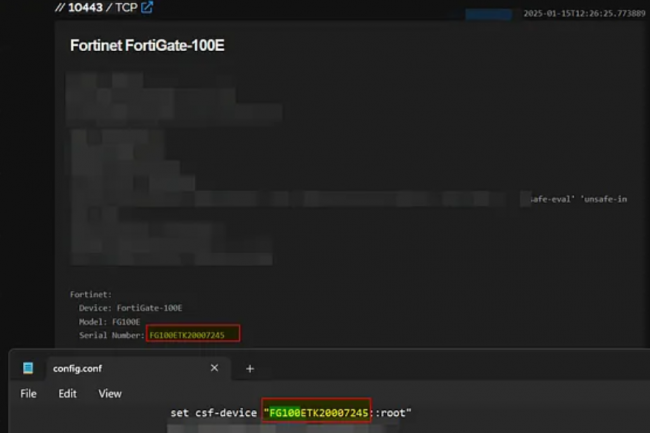
A peine sortis d’une zero-day, les administrateurs de pare-feux FortiGate de Fortinet doivent examiner minutieusement leurs systèmes pour éviter tout risque de compromission suite à la diffusion de données de configuration et d’informations d’identification VPN volées il y a deux ans.
Coup de chaud pour les administrateurs réseau qui utilisent le pare-feu FortiGate de Fortinet dans leur environnement informatique. Après une faille zero-day exploitée dans les firewalls de ce fournisseur, le chercheur en cybersécurité Florian Roth a lancé une autre alerte. Cet avertissement fait suite à l’analyse qu’il a faite des données de configuration de matériels FortiGate volés, publiées au début du mois par un acteur malveillant appelé Belsen Group. Ces données, censées contenir les paramètres de configuration de 15 000 pare-feux, seraient d’une grande valeur pour les pirates. « Si la sécurité est importante pour vous, vous devez évaluer la compromission des terminaux et autres systèmes de votre réseau touchés […] les correctifs ne suffisent pas. » Le chercheur les exhorte aussi à traiter cette affaire comme un incident de sécurité.
A l’origine de cette découverte, Kevin Beaumont, également chercheur en sécurité, qui a trouvé après examen des données publiées par ce cybergang. Elles contenaient des adresses IP, des mots de passe en clair et certaines adresses électroniques d’utilisateurs ou de leurs entreprises. À la vue de ces informations, certains se demandent aussi pourquoi les administrateurs ont autorisé le stockage de mots de passe en clair dans un fichier de configuration. M. Roth a regroupé les adresses électroniques par domaine de premier niveau afin d’aider les RSSI et les équipes de sécurité à déterminer si leur entreprise était concernée. Cependant, il a averti que certains des domaines pouvaient être ceux de services de messagerie gratuits ou de fournisseurs de services travaillant pour les victimes réelles.
Des mesures à prendre pour éviter l’exploit
Pour sa part, après la publication, la semaine dernière, des données dérobées par Belsen Group, Fortinet s’est voulu rassurant, déclarant que les informations exposées avaient été capturées à partir d’une vulnérabilité de 2022 et agrégées pour ressembler à une nouvelle divulgation. « Notre analyse des appareils en question montre que la majorité d’entre eux ont depuis longtemps été mis à niveau vers des versions plus récentes », a affirmé l’entreprise. La liste ne comprend aucune configuration pour FortiOS 7.6 ou 7.4 (les versions les plus récentes du système d’exploitation de Fortinet), « ni aucune configuration récente pour 7.2 et 7.0 ». « Si votre entreprise a toujours respecté les meilleures pratiques de routine en actualisant régulièrement les informations d’identification de sécurité et a pris les mesures recommandées au cours des années précédentes, il y a très peu de risque que la configuration actuelle de l’entreprise ou des informations d’identification aient été divulguées par l’acteur de la menace », a précisé Fortinet.
« Nous continuons à recommander vivement aux entreprises de prendre les mesures recommandées, si elles ne l’ont pas déjà fait, pour améliorer leur posture de sécurité. Nous pouvons également confirmer que les équipements achetés depuis décembre 2022 ou qui n’ont exécuté que FortiOS 7.2.2 ou une version plus récente ne sont pas concernés par les informations divulguées par cet acteur de la menace. » Cependant, le fournisseur ajoute que si une entreprise « utilisait une version impactée (7.0.6 et inférieure ou 7.2.1 et inférieure) avant novembre 2022 et qu’elle n’a pas encore pris les mesures recommandées dans l’avis [d’octobre 2022] », elle doit revoir les actions recommandées pour améliorer sa posture de sécurité. Les chercheurs de Censys pensent qu’un peu plus de 5 000 des 15 000 dispositifs FortiGate compromis exposent encore leurs interfaces de connexion Web. « Même si vous avez appliqué un correctif en 2022, vous pouvez toujours avoir été exploité, car les configurations ont été vidées il y a des années et viennent seulement d’être publiées », a encore écrit M. Beaumont. « Il est préférable de savoir à quel moment ce correctif a été appliqué. Disposer de la configuration complète d’un appareil, y compris de toutes les règles de pare-feu, cela représente beaucoup d’informations… »
Une faille toujours dangereuse
Alors que les données ont apparemment été collectées il y a un peu plus de deux ans, on ne sait pas pourquoi elles sont diffusées maintenant. Dans un article publié la semaine dernière et analysant les données, les chercheurs de Censys font remarquer que Belsen Group est un acteur récent de la menace et qu’il a peut-être récemment acheté ou rassemblé les données mises en vente par le(s) pirate(s) initial(aux). Censys estime également que, même si des mesures ont été prises par les administrateurs de FortiGate il y a deux ans, après la découverte de la vulnérabilité, « celle-ci est toujours pertinente et pourrait causer des dommages ». Souvent, les règles de configuration des pare-feux ne sont pas modifiées, à moins qu’un incident de sécurité spécifique oblige à une mise à jour. « Il peut aussi arriver que certains de ces firewalls aient changé de propriétaire dans l’intervalle, mais ces cas sont également rares. »
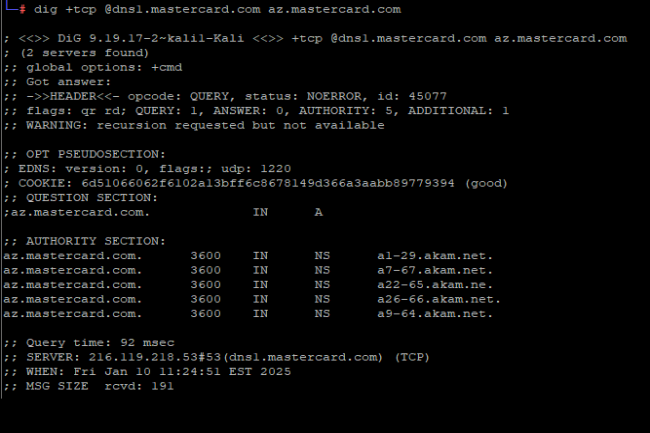
Un chercheur en sécurité a découvert une erreur dans la configuration du DNS de Mastercard provenant d’un simple copier-coller. Une affaire qui aurait pu avoir de graves conséquences et qui pose la question de la détection d’un telle maladresse.
Pendant près de cinq ans, il a manqué un caractère dans l’enregistrement DNS de Mastercard. Selon le chercheur en sécurité qui l’a découverte, cette erreur dans le paramétrage du DNS (domain name system) résulte presque certainement d’un copier-coller malheureux. L’erreur aurait pu permettre à des pirates de prendre le contrôle du sous-domaine, de créer un faux site imitant le site officiel de Mastercard et de tromper les clients pour obtenir des détails sensibles et des informations…
Il vous reste 91% de l’article à lireVous devez posséder un compte pour poursuivre la lecture
Vous avez déjà un compte?

Pourtant grands utilisateurs des services Google, les hôtels scandinaves Strawberry se détournent du moteur de recherche du Californien. En cause, les multiples publicités malveillantes que ce dernier laisse passer. Strawberry espère ainsi susciter le débat.
Fin 2021, la chaîne Nordic Choice Hotels, rebaptisée Strawberry, a été victime d’une importante attaque de ransomware qui a paralysé ses activités pendant un peu plus d’une semaine. Tout a dû être fait manuellement, explique Martin Belak, responsable de la sécurité de la chaîne hôtelière. « Les réceptionnistes travaillaient avec des tableaux blancs pour savoir quelles chambres étaient réservées », se rappelle-t-il.L’attaque a incité Strawberry, qui compte 240 hôtels en Scandinavie, en Finlande et dans les pays baltes et plus de 16 500 employés, à accélérer la transition de son environnement Windows vers un environnement Chrome OS en un temps record, en migrant 4 000 appareils en une semaine. « Nous sommes massivement utilisateurs des outils de Google et disposons de l’ensemble de la suite Workspace. Nous sommes un gros client de ce fournisseur et entretenons avec lui une relation étroite », synthétise Martin Belak.Le malvertising détruit la confiance et coûte de l’argentCette proximité avec Google n’empêche pas la chaîne d’hôtels de se défier de ce qui reste le principal service de la firme de Mountain View : la recherche. En cause, le manque de contrôle sur les publicités affichées par Google. « Le plus gros problème est que Google ne vérifie pas quels annonceurs sont autorisés à avoir des positions de recherche payantes. Il ne vérifie ni l’authenticité ni les antécédents, ce qui signifie qu’il autorise à la fois des acteurs légaux et criminels », explique Martin Belak.Quiconque recherche, par exemple, un fournisseur risque de se retrouver sur une page achetée affichée par un acteur criminel – une technique communément appelée malvertising. « Les criminels achètent des mots-clés et créent de fausses landing pages identiques aux pages légitimes, sous des URL similaires aux URL réelles. Nous sommes exposés à ces tentatives de fraude tous les jours. Heureusement, nos outils de sécurité détectent la plupart d’entre elles, mais celles qui passent au travers nous coûtent à la fois de la confiance et de l’argent. Nous devons indemniser les victimes, tout en prenant en charge les coûts administratifs liés au signalement des incidents à l’autorité suédoise de protection de la vie privée », détaille Martin Belak.L’hameçonnage cible la rechercheStrawberry a essayé à plusieurs reprises de signaler ces problèmes à Google, mais n’a pas réussi à dialoguer avec les responsables de ce sujet au sein de l’entreprise californienne parce que ses contacts ne dépendent pas de l’activité gérant la publicité.La chaîne d’hôtels, qui fait partie du groupe Choice Hotels International, n’est d’ailleurs pas la seule à avoir signalé ces problèmes. Il y a deux ans, le FBI a mis en garde contre ce type d’escroquerie par le biais d’annonces achetées, mais sans réel effet depuis lors. L’éditeur de solutions de sécurité Netskope a récemment indiqué que, selon ses données de télémétrie, les taux de clics d’hameçonnage ont triplé en 2024. L’empoisonnement des moteurs de recherche et la publicité malveillante expliquent en partie cette hausse alarmante, car les cybercriminels déplacent leurs opérations vers la recherche, délaissant un peu les boîtes de réception mail.Face à ces constats, Strawberry, a décidé, avant Noël, de changer de moteur de recherche par défaut dans Chrome, optant pour DuckDuckGo, au sein duquel la fonction publicitaire a également été désactivée en guise de précaution supplémentaire. « C’est un peu ironique parce que nous dépendons nous-mêmes des publicités de Google, alors nous avons un peu l’impression de nous tirer une balle dans le pied. Mais il devrait exister un équilibre intégrant la validation des annonces et l’interdiction de concevoir des publicités orientant l’internaute vers une URL détournant sa recherche », souligne Martin Belak.L’espoir de créer le débatIl précise également que ce n’est pas Google dans son ensemble qui déplaît à Strawberry, d’autres secteurs d’activité du fournisseur travaillant d’arrache-pied des sujets comme les services de monitoring du cloud, le blocage des tiers dans le navigateur, etc. « Ils investissent des milliards dans la cybersécurité au sein de leurs autres activités, mais pas dans la publicité, et cela devient très étrange pour moi en tant que client », explique-t-il.Martin Belak n’espère pas que la décision de Strawberry affectera Google au-delà de la création d’un débat. Il souligne qu’il ne s’agit pas non plus d’un problème qui peut être résolu par l’authentification à deux facteurs et autres, car les fraudeurs interceptent aujourd’hui les jetons qui sont générés en temps réel et automatiquement. En outre, Google n’est pas la seule entreprise à être confrontée à ce problème, que d’autres entreprises parviennent toutefois à mieux contrôler. « Pourquoi ne peuvent-ils pas vérifier leurs annonceurs alors qu’Apple peut contrôler les applications qui entrent dans l’App Store ? Nous sommes un petit acteur, mais nous avons pointé du doigt un dysfonctionnement et nous verrons ce que cela donnera », conclut Martin Belak.
Atteignant 1,2 Md€ en 2024, le montant des amendes pour manquements au règlement général sur la protection des données personnelles a reculé de 33 % d’une année sur l’autre. Mais le nombre de signalements de violations de données dans le même temps augmenté de 8,3 %.
Les violations du règlement général sur la protection des données personnelles (RGPD) par les entreprises ont donné lieu à des amendes totales de 1,2 Md€ en 2024, selon un rapport du cabinet d’avocats international DLA Piper. Cette somme est en baisse de 33 % par rapport à 2023, rompant ainsi une série de sept années d’augmentation des amendes. Selon le cabinet, l’une des raisons de cette diminution est qu’une amende de 1,2 Md€ avaitété imposée à la seule société Meta en 2023, soit le même montant que pour l’ensemble de l’année 2024. Une somme qui reste le record à ce jour.
« Après avoir constaté une augmentation des montants de sanction administrative depuis l’entrée en vigueur du RGPD en 2018, nous observons désormais une diminution. Cela est dû au fait qu’aucune grande amende record n’a été émise en 2024. Cependant, le nombre de signalements de violations de données personnelles a continué de progresser », a indiqué Anna Jussil Broms, responsable de la propriété intellectuelle et de la technologie chez DLA Piper en Suède.
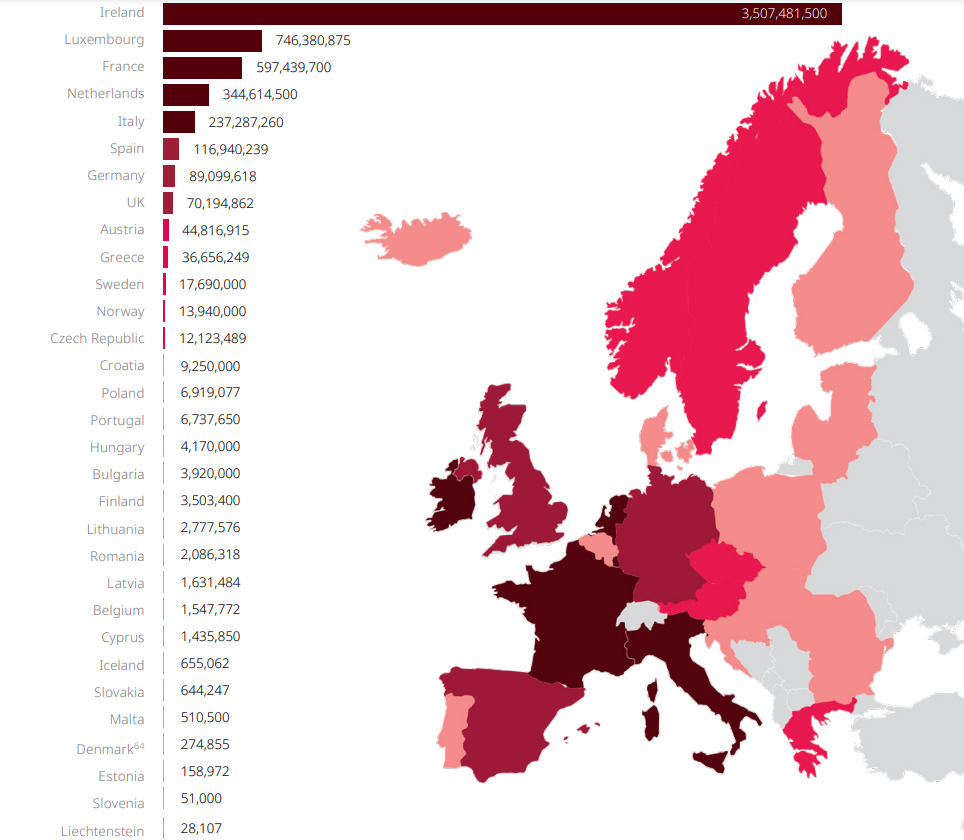
Montant des amendes en euros imposées par les pays européens depuis l’entrée en vigueur du RGPD le 25 mai 2018. (crédit : DLA Piper)
Une surveillance multisectorielle accrue
Les notifications de vols ou de compromission de données en 2024 ont atteint une moyenne de 363 par jour, contre 335 par jour l’année précédente, soit une progression de 8,3 %. Comme auparavant, ce sont les grandes entreprises IT et les géants des médias sociaux qui ont été les plus touchés par les amendes. Les plus importantes en 2024 ont été émises par le régulateur irlandais et ont visé LinkedIn (310 M€) et Meta (251 M€).
« Il est clair que le contrôle du RGPD continue d’évoluer et de s’adapter. Nous constatons une observation accrue dans d’autres secteurs que les grandes entreprises technologiques et de médias sociaux. Par exemple, l’accent mis sur la gouvernance et la surveillance a conduit l’autorité néerlandaise de protection des données à examiner si les membres de l’équipe de direction de Clearview AI peuvent être tenus personnellement responsables des violations du RGPD, suite à une amende de 30,5 M€ infligée à l’entreprise », a fait savoir Gustav Lundin, associé chez DLA Piper.
Atteignant 1,2 Md€ en 2024, le montant des amendes pour manquements au règlement général sur la protection des données personnelles a reculé de 33 % d’une année sur l’autre. Mais le nombre de signalements de violations de données dans le même temps augmenté de 8,3 %.
Les violations du règlement général sur la protection des données personnelles (RGPD) par les entreprises ont donné lieu à des amendes totales de 1,2 Md€ en 2024, selon un rapport du cabinet d’avocats international DLA Piper. Cette somme est en baisse de 33 % par rapport à 2023, rompant ainsi une série de sept années d’augmentation des amendes. Selon le cabinet, l’une des raisons de cette diminution est qu’une amende de 1,2 Md€ avaitété imposée à la seule société Meta en 2023, soit le même montant que pour l’ensemble de l’année 2024. Une somme qui reste le record à ce jour.
« Après avoir constaté une augmentation des montants de sanction administrative depuis l’entrée en vigueur du RGPD en 2018, nous observons désormais une diminution. Cela est dû au fait qu’aucune grande amende record n’a été émise en 2024. Cependant, le nombre de signalements de violations de données personnelles a continué de progresser », a indiqué Anna Jussil Broms, responsable de la propriété intellectuelle et de la technologie chez DLA Piper en Suède.
Montant des amendes en euros imposées par les pays européens depuis l’entrée en vigueur du RGPD le 25 mai 2018. (crédit : DLA Piper)
Une surveillance multisectorielle accrue
Les notifications de vols ou de compromission de données en 2024 ont atteint une moyenne de 363 par jour, contre 335 par jour l’année précédente, soit une progression de 8,3 %. Comme auparavant, ce sont les grandes entreprises IT et les géants des médias sociaux qui ont été les plus touchés par les amendes. Les plus importantes en 2024 ont été émises par le régulateur irlandais et ont visé LinkedIn (310 M€) et Meta (251 M€).
« Il est clair que le contrôle du RGPD continue d’évoluer et de s’adapter. Nous constatons une observation accrue dans d’autres secteurs que les grandes entreprises technologiques et de médias sociaux. Par exemple, l’accent mis sur la gouvernance et la surveillance a conduit l’autorité néerlandaise de protection des données à examiner si les membres de l’équipe de direction de Clearview AI peuvent être tenus personnellement responsables des violations du RGPD, suite à une amende de 30,5 M€ infligée à l’entreprise », a fait savoir Gustav Lundin, associé chez DLA Piper.
De plus en plus populaire, les logiciels en Python ne sont pas exempts de problèmes de sécurité. Un responsable de PyPi a déployé le projet Quarantine visant à éviter la prolifération de logiciels malveillants.
Pour faire face au détournement généralisé de programmes Python à des fins malveillantes, les administrateurs du Python Package Index (PyPI) ont lancé un projet pour renforcer la sécurité. Nommé Quarantine, l’initiative a été lancée en début d’année 2024 et elle vient d’être déployée en ce début d’année 2025. Elle consiste à identifier et à empêcher les paquets contenant des malwares de proliférer au sein de la…
Il vous reste 93% de l’article à lireVous devez posséder un compte pour poursuivre la lecture
Vous avez déjà un compte?
Un chercheur a découvert une faille API dans ChatGPT donnant la capacité à des attaquants d’employer son crawler pour lancer des attaques DDoS contre des sites web. Prévenus, ni OpenAI ni Microsoft n’ont pour l’heure réagi.
ChatGPT, propriété d’OpenAI, présenterait une vulnérabilité où des acteurs malveillants seraient capables de lancer des attaques par déni de service distribué (DDoS) sur des cibles qui ne se doutent de rien. Selon une découverte faite par le chercheur en sécurité allemand Benjamin Flesch, le crawler de l’assistant IA utilise pour collecter des données sur l’internet afin de l’améliorer peut être piégé pour lancer des attaques en déni de service sur des sites web. « Le crawler ChatGPT peut être déclenché pour attaquer un site web victime par le biais d’une requête HTTP à l’API ChatGPT non reliée », a déclaré le chercheur dans un repo Github dans lequel et décrit son PoC. « Ce défaut dans le logiciel OpenAI provoquera une attaque DDoS sur le site web victime, en utilisant plusieurs plages d’adresses IP Microsoft Azure sur lesquelles le robot de ChatGPT est en cours d’exécution ». M. Flesch précise que la découverte a été faite en janvier 2025 et qu’elle a depuis été portée à la connaissance d’OpenAI et de Microsoft, qui n’ont pas encore reconnu l’existence de la vulnérabilité.
Il a souligné que l’API ChatGPT présentait une faille importante lors du traitement des requêtes HTTP POST. L’API exige une liste d’URL, mais ne vérifie pas s’il y a des liens hypertextes en double et n’impose pas de limite à leur nombre, ce qui autorise potentiellement des milliers de liens hypertextes dans une seule requête HTTP. « Il est communément admis que les liens hypertextes vers un même site web peuvent être écrits de différentes manières », a déclaré M. Flesch. « En raison de mauvaises pratiques de programmation, OpenAI ne vérifie pas si un lien hypertexte vers la même ressource apparaît plusieurs fois dans la liste. » L’API traite individuellement chaque hyperlien dans une requête POST, en utilisant les serveurs Microsoft Azure, ce qui entraîne de nombreuses tentatives de connexion simultanées au site cible. Le volume important de connexions provenant des serveurs OpenAI qui en résulte peut potentiellement submerger le site web ciblé.
La même API déjà ouverte aux attaques par injection de prompt
Selon une autre divulgation faite par Benjamin Flesch, la même API est également vulnérable aux attaques par injection de prompt. Le problème vient du fait que l’API accepte des paramètres « urls » contenant des commandes textuelles pour leur LLM. Il peut être exploité afin que le crawler réponde via l’API à des questions au lieu de récupérer des sites web comme prévu.
« En raison du grand nombre d’invites qui peuvent être soumises via le paramètre urls, ce défaut logiciel pourrait servir à ralentir les serveurs d’OpenAI », a ajouté le chercheur. Bien que la reconnaissance et l’énumération des failles soient encore attendues, il a placé la gravité de la faille permettant le DDoS à 8,6 sur 10 sur l’échelle CVSS, en raison de sa nature basée sur le réseau, de sa faible complexité, de l’absence d’exigence de privilèges ou d’interaction avec l’utilisateur, et de l’impact élevé sur la disponibilité des services. Les demandes envoyées à OpenAI pour obtenir un accusé de réception et d’autres détails sur la faille n’ont reçu aucune réponse jusqu’à la publication de cet article.

Basé sur un projet open source dédié à Kubernetes, Connectivity Link de Red Hat fournit des fonctions de gestion de trafic et de sécurité des applications dans des écosystèmes multicloud.
Après avoir dévoilé récemment OpenShift Virtualization Engine pour les déçus de VMware, Red Hat s’intéresse à la connectivité des applications dans les environnements multicloud complexes. Dans ce cadre, la filiale d’IBM lance Connectivity Link avec plusieurs fonctions comme la gestion du trafic, l’application de politiques et le contrôle d’accès basé sur les rôles,…. La solution est basée sur le projet open source Kuadrant, retenu par la CNCF (cloud native computing foundation)…
Il vous reste 91% de l’article à lireVous devez posséder un compte pour poursuivre la lecture
Vous avez déjà un compte?