





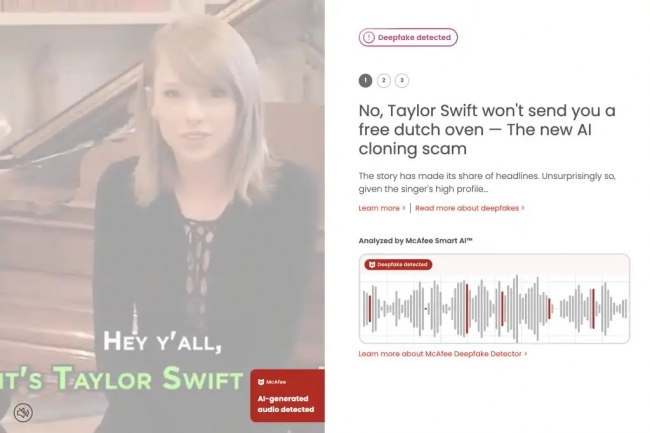
L’éditeur spécialisé dans la cybersécurité propose avec les PC Copilot + Lenovo, pour l’instant, un outil baptisé Deepfake Detector capable de détecter les vidéos trompeuses générées par IA.
Les développeurs de logiciels de tous bords cherchent à tirer parti des nouvelles capacités d’IA des accélérateurs NPU présents dans les PC Copilot+. McAfee pense en avoir trouvé un usage très concret : la détection des deepfakes vidéos. Le McAfee Deepfake Detector semble être un outil potentiellement pratique pour lutter contre la désinformation, s’il fonctionne comme annoncé : Il travaille en arrière-plan et analyse discrètement toutes les vidéos regardées par l’utilisateur. S’il s’agit d’une vidéo générée par l’IA, le service de McAfee émet un avertissement d’identification. Le Deepfake Detector ne fait pas partie de la solution antimalware de McAfee, Total Protection – du moins pas encore. L’éditeur met l’application à la disposition exclusive des clients de PC Copilot+ Lenovo. Ces derniers recevront un essai gratuit de l’outil, qui leur coûtera par la suite 9,99 $ pour l’année entière s’ils choisissent de s’abonner.
« Chez McAfee, nous sommes inspirés par le potentiel de transformation de l’IA et nous nous engageons à contribuer à façonner un avenir où l’IA est utilisée pour le bien », a déclaré Roma Majumder, vice-président principal des produits chez McAfee, dans un communiqué. « L’association avec Lenovo renforce notre capacité à fournir la détection de deepfakes la plus efficace, automatisée et alimentée par l’IA, offrant aux utilisateurs un gardien numérique performant sur leurs PC. Ensemble, nous sommes en mesure d’exploiter l’IA de manière nouvelle et révolutionnaire, en offrant aux individus la détection de deepfake la plus avancée afin qu’ils puissent naviguer en toute sécurité et en toute confiance dans un monde en ligne en constante évolution ».
Comment fonctionne Deepfake Detector
L’outil de détection n’examine pas vraiment les vidéos, au lieu de cela, il écoute la partie audio intégrée dans la vidéo et y applique ses algorithmes d’analyse épaulés par l’intelligence artificielle. Toute la détection s’effectue localement sur le PC équipé d’un NPU, ce qui signifie que les données ne sont pas transférées vers un cloud pour être analysées. Et l’audio de l’utilisateur n’est en aucun cas enregistré. La détection audio peut être activée ou désactivée bien entendu.
McAfee a indiqué qu’elle lançait également un Smart AI Hub pour sensibiliser les utilisateurs aux deepfakes, et contribuer à la lutte contre la désinformation. Il est également possible de contribuer à l’entraînement de l’IA de McAfee en téléchargeant une URL cachant un deepfake.
La technologie quantique progresse : IBM, Google, D-Wave, Quandela, IQM, Pasqal, sans oublier de nombreux laboratoires de recherche, tous travaillent sur des ordinateurs pourvus du plus grand nombre de qubits et cherchent aussi à maîtriser la stabilité (tolérance aux erreurs) de ces mêmes qubits sur le temps long. Rappelons que l’informatique quantique permet d’accélérer des performances sur des problèmes difficiles à résoudre en informatique classique dans divers secteurs (énergie, santé, finance, etc.). Le plus connu et le plus inquiétant est sûrement l’algorithme de Shor, ce dernier, avec la puissance quantique, permettra probablement d’ici à la fin de la décennie de casser en quelques minutes nos systèmes de cryptographie à clé publique (RSA ou courbes elliptiques)que l’on retrouve partout dans les transactions et communications. (Crédit The Digital Artist / Pixabay)

Après la panne de Crowdstrike en juillet, les équipes IT en entreprises reconsidèrent l’impact du cloud sur la fiabilité de leurs applications. A raison ?
Le 19 juillet, quelques minutes après que Crowdstrike, le géant de la sécurité des données, a publié ce qui était censé être une mise à jour de sécurité, les entreprises ont commencé à perdre des terminaux Windows. Et nous nous sommes retrouvés avec l’une des pannes informatiques les plus graves et les plus étendues de tous les temps. On a beaucoup parlé du pourquoi et du comment de cet événement. Mais quelles conséquences a-t-il eu sur la manière dont les entreprises anticipent les pannes et sur ce qu’elles pensent devoir faire en pareil cas ? On nous a également dit que les entreprises repensaient leur stratégie cloud suite à la panne Crowdstrike. Est-ce vrai, et, si oui, que prévoient-elles de faire ?Une chose est claire : les entreprises pensent que le problème vient de Crowdstrike. Seules 21 des entreprises que j’ai contactées pensaient que Microsoft y avait contribué, et aucune ne pensait que cet éditeur était le principal acteur à blâmer.Les deux erreurs de CrowdstrikeSelon les entreprises, CrowdStrike a commis deux erreurs. Tout d’abord, il n’a pas tenu compte de la sensibilité de son logiciel client Falcon pour les terminaux concernant les données décrivant comment rechercher les problèmes de sécurité. En conséquence, une mise à jour de ces données a fait planter le client en introduisant une condition qui existait auparavant mais qui n’avait pas été correctement testée. Deuxièmement, au lieu de procéder à une diffusion limitée du nouveau fichier de données, qui aurait certainement permis de détecter le problème et d’en limiter l’impact, Crowdstrike l’a diffusé d’emblée à l’ensemble de sa base d’utilisateurs.Toute logique de programmation est dépendante des données, en ce sens que les chemins logiciel sont déterminés par les données qu’il traite. On ne peut donc pas dire qu’on a testé un programme si l’on n’a pas exploré tous ces chemins. Sur les 89 responsables du développement au sein d’entreprises qui m’ont fait part de leurs commentaires, tous ont déclaré avoir été confrontés à ce problème lors de leurs propres tests, et ils s’attendent à ce qu’un fournisseur de logiciels soit encore plus prudent qu’ils ne le sont eux-mêmes. Ils comprennent néanmoins comment cela peut se produire. L’un d’entre eux a déclaré avoir entendu dire que le bogue logiciel était présent dans le client Falcon depuis plus d’un an et qu’il n’avait tout simplement pas encore été détecté.Microsoft : fautif ou pas ?Les choses deviennent un peu plus confuses sur le plantage des systèmes Windows (plus de huit millions d’entre eux) consécutif à la défaillance de Crowdstrike et sur leur résistance à la récupération à distance. Les 21 entreprises qui estiment que Microsoft a contribué au problème pensent toutes que Windows n’aurait pas dû réagir comme il l’a fait à l’erreur de CrowdStrike. Les 37 entreprises qui n’ont pas tenu Microsoft pour responsable ont souligné que les logiciels de sécurité ont nécessairement une capacité unique à interagir avec le logiciel du noyau Windows, ce qui signifie qu’ils peuvent créer un problème majeur en cas d’erreur.Mais si les entreprises ne sont pas convaincues que Microsoft a bien contribué au problème, plus des trois quarts d’entre elles pensent que Microsoft pourrait agir pour réduire le risque de rechute. Presque autant d’entreprises ont déclaré qu’elles pensaient que Windows était plus sensible que d’autres OS au type de problème créé par le bogue de Crowdstrike, et ce point de vue était partagé par 80 des 89 responsables du développement interrogés, dont beaucoup ont souligné que MacOS ou Linux ne présentait pas le même niveau de risque et qu’aucun n’avait été touché par le problème.Evaluer l’impact du cloud sur la fiabilité des applicationsMais qu’est-ce que tout cela signifie en ce qui concerne l’utilisation du cloud ? Les entreprises considéraient traditionnellement son usage comme un moyen d’améliorer la fiabilité de leurs applications. Mais la part de celles qui pensent avoir mal évalué la valeur du cloud dans ce domaine est passée de moins de 15% avant la panne à 35% immédiatement après et à 55% au début du mois d’août. Le facteur le plus important de cette croissance a été la prise de conscience que des défaillances massives des points d’accès pouvaient mettre fin à leurs activités, et qu’aucune sauvegarde dans le cloud ne serait efficace. Les entreprises ont été obligées d’examiner en profondeur l’impact du cloud sur la fiabilité des applications.Supposons qu’une application hébergée dans un datacenter soit liée à un PC Windows. Supposons encore que chacun d’eux soit susceptible de tomber en panne 1% du temps. Vous souhaitez améliorer la fiabilité en ajoutant un front-end dans le cloud, également associé à un taux de panne de 1% du temps. Quelle est votre fiabilité ? Tout dépend de la capacité du cloud et du datacenter à se sauvegarder mutuellement. S’ils ne le peuvent pas, la probabilité que les trois soient opérationnels en même temps est de 0,99 au cube, soit 97 %, ce qui est inférieur à la disponibilité sans le cloud. Mais si ce dernier et le datacenter peuvent s’appuyer l’un sur l’autre, il faudrait qu’ils tombent tous les deux en panne pour que votre application soit indisponible. Le risque de défaillance du nuage et du centre de données est alors de 1% fois 1%, soit un sur dix mille. La fiabilité de l’application s’en trouve améliorée.Le multicloud améliore la fiabilité ? Pas toujoursLe même type de calcul doit être pris en compte pour le multicloud. Sur les 110 entreprises qui ont commenté l’impact du multicloud sur la fiabilité, 108 ont déclaré qu’il rendait les applications plus fiables. Est-ce le cas ? Cela dépend. Si deux cloud se soutiennent mutuellement, le risque de défaillance est effectivement plus faible, comme dans mon exemple précédent. Mais de nombreuses entreprises ont admis qu’au moins certaines de leurs applications avaient besoin des deux cloud parce que les composants reposaient sur des fonctions spécifiques à chaque environnement. Dans ce cas, les deux prestataires doivent être opérationnels en même temps, et le multi-cloud réduit en fait la fiabilité de l’application !Cela prouve que les entreprises se font peut-être des illusions sur le cloud. Il ne va pas toujours améliorer la fiabilité, pas plus qu’il ne va systématiquement réduire les coûts. Rien ne remplace le fait de savoir précisément ce que l’on fait, en particulier dans le domaine de la gestion de la fiabilité. L’instinct n’est pas un bon substitut à un cours sur les probabilités et les statistiques.La question clef de la fiabilité des accèsMais revenons à mon calcul de la fiabilité du cloud. Oui, le risque de défaillance du nuage et du datacenter est de un sur dix mille, mais le risque de défaillance du terminal ets, dans cet exemple, est de un sur cent. Le risque lié aux points d’accès est clairement plus important, alors que peuvent faire les entreprises à ce sujet ?Sur les 138 entreprises qui ont commenté le problème, la suggestion la plus fréquente a été d’apprendre aux personnes clés de chaque site à effectuer un « démarrage sécurisé » de leurs systèmes, car c’est tout ce qui était réellement nécessaire pour résoudre rapidement le problème Crowdstrike. La deuxième recommandation la plus fréquente est d’utiliser une interface de navigateur sur le terminal plutôt qu’une application. En fait, 44 entreprises ont déclaré qu’elles utilisaient un accès par navigateur et qu’elles étaient en mesure de fonctionner normalement lors d’une panne de type Crowdstrike à condition de disposer d’un terminal ne tournant pas sur Windows. Le plus souvent, il s’agissait d’un téléphone ou d’une tablette, mais certaines (13) disposaient de systèmes bureautiques Mac ou Linux qu’elles auraient pu utiliser pendant la panne. En outre, il est possible d’utiliser un certain nombre de terminaux basiques pour faire fonctionner un navigateur, comme un Chromebook, et ce type d’appareils est moins susceptibles d’être la proie de problèmes tels que celui rencontré par Crowdstrike, ou même d’avoir besoin d’outils de sécurité spécialisés pour les terminaux.Simplifier les terminauxDevriez-vous donc « repenser votre stratégie cloud » ? En fait, ce qu’il faut peut-être, c’est repenser la stratégie relative aux terminaux. La recommandation portant sur l’accès via un navigateur pourrait signifier que renforcer l’usage du cloud réduirait les risques. Car le vrai problème ici est que les dispositifs sophistiqués, qui servent de portes d’entrée aux applications, sont plus difficiles à réparer à distance, et que le personnel local n’a pas les compétences nécessaires pour effectuer ce travail lui-même. La simplification des terminaux peut conduire à une multiplicité d’options de terminaux disponibles, comme cela a été le cas pour de nombreuses entreprises, ce qui raménerait le type de défaillance créé par Crowdstrike à un désagrément marqué. Ne paniquez pas ; bien utilisé, le cloud reste votre ami.
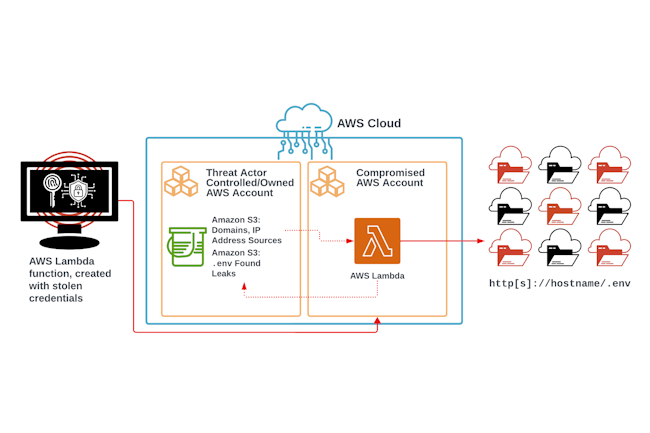
Des attaquants ont collecté des clés AWS et des tokens d’accès à divers services cloud de l’hyperscaler à partir de variables d’environnement stockées de manière non sécurisée dans des dizaines de milliers d’applications web.
Les cybercriminels s’intéressent de plus en plus au cloud au fur et à mesure de l’adoption de ce dernier. Une campagne d’extorsion compromettant les ressources AWS par le biais d’informations d’identification collectées à partir de fichiers d’environnement (.env) a été découverte par les chercheurs de l’Unité 42 de Palo Alto. Ces fichiers étaient stockés de manière non sécurisée sur des serveurs web. Ils comprenaient des clés d’accès à AWS, des identifiants pour des bases de données et des comptes de réseaux sociaux, des clés API pour des applications SaaS et des services de messagerie, ainsi que des tokens d’accès à divers services cloud de l’hyperscaler.
L’opération a été découverte alors que les chercheurs enquêtaient sur un environnement AWS compromis qui était utilisé de manière abusive pour lancer des analyses automatisées contre d’autres domaines. Les spécialistes ont déterminé que les attaquants avaient collecté des fichiers .env provenant d’environ 110 000 domaines, ce qui a conduit à l’exposition de plus de 90 000 variables d’environnement uniques, dont 7 000 correspondant à des services cloud utilisés par des entreprises. « Toutes les fuites ne contenaient pas nécessairement des comptes utilisateurs ou des secrets, mais elles ont toutes révélé des détails sur l’infrastructure interne de la victime ou sur sa configuration », indiquent les experts dans le rapport. Parmi les exemples d’informations d’identification divulguées figurent 1 185 clés d’accès uniques à AWS, 333 tokens PayPal OAuth, 235 tokens GitHub, 111 clés API HubSpot, 39 webhooks Slack et 27 tokens DigitalOcean.
Une mauvaise configuration expose les variables d’environnement
De nombreux framework de développement et applications web stockent des données de configuration importantes dans des fichiers .env. Les serveurs web devraient être configurés pour empêcher l’accès aux fichiers . (dot) par défaut, car ils sont censés être des fichiers cachés qui ne sont jamais destinés à être accessibles au public. Cependant, des erreurs de configuration se produisent régulièrement. Un autre exemple est le dossier .git qui stocke des informations de configuration importantes pour le système de contrôle de version du code source git.
L’exposition accidentelle de fichiers .env ou .git est un problème connu, souvent mis en exergue par d’autres chercheurs. Il n’est donc pas inhabituel pour les attaquants de lancer des robots scannant le web à la recherche de tels fichiers exposés dans le dossier racine des domaines. Toutefois, l’ampleur de l’opération découverte par l’unité 42 de Palo Alto Networks suggère que de telles erreurs de configuration restent très répandues.
Des mouvements latéraux dans les environnements AWS
Entre les mains de pirates compétents, les secrets divulgués peuvent être très dangereux. Après avoir obtenu une clé d’accès AWS, les attaquants l’ont utilisée pour exécuter un appel API GetCallerIdentity afin de vérifier l’identité ou le rôle attribué à l’identifiant exposé. Ils ont également effectué d’autres actions de reconnaissance en appelant ListUsers pour rassembler une liste d’utilisateurs IAM (gestion des accès et des identités) dans le compte AWS et ListBuckets pour identifier tous les buckets S3 existants.
Dans l’environnement AWS compromis étudié, les attaquants ont réalisé que le rôle dans l’IAM AWS exposé qu’ils avaient obtenu ne disposait pas de privilèges administrateurs sur toutes les ressources. Cependant, il avait la permission de créer de nouveaux rôles IAM et d’attacher des politiques spécifiques aux rôles existants. Ils ont alors procédé à la création d’un autre rôle appelé lambda-ex et y ont attaché la politique AdministratorAccess, réalisant ainsi une élévation des privilèges. « Suite à la création réussie du rôle IAM privilégié, l’attaquant a tenté de créer deux piles d’infrastructure différentes, l’une utilisant les ressources Amazon Elastic Cloud Compute (EC2) et l’autre avec AWS Lambda », ont déclaré les chercheurs. « En effectuant ces tactiques d’exécution, les acteurs n’ont pas réussi à créer un groupe de sécurité, une paire de clés et une instance EC2, mais ils ont créé avec succès plusieurs fonctions lambda avec le rôle IAM nouvellement créé attaché. »
230 millions de cibles uniques
AWS Lambda est une plateforme serverless conçue pour provisionner automatiquement les ressources cloud en fonction de l’application fournie par l’utilisateur. Elle a déjà été utilisée de manière abusive par des attaquants pour le minage de crypto-actifs avec des mineurs écrits en Go, mais dans ce cas, les pirates l’ont utilisée pour déployer un script bash qui analyse d’autres domaines à la recherche de fichiers .env exposés, en extrait les informations d’identification et les télécharge vers un bucket S3 public qu’ils ont précédemment compromis.
Ce script particulier recherche des informations d’identification pour la plateforme d’envoi de courriels Mailgun, mais en accédant à l’espace de stockage S3 publiquement exposé des attaquants, les chercheurs ont été en mesure de comprendre toute l’étendue de la campagne. « Nous avons identifié plus de 230 millions de cibles uniques que l’acteur de la menace analysait à la recherche de fichiers d’environnement mal configurés et exposés. Au moment de l’accès à ce bucket S3 public, nous estimons que plusieurs comptes AWS compromis étaient la cible de cette analyse malveillante dans le cadre d’une opération automatisée de compromission. »
Exfiltration de données, extorsion et des conseils
Chaque fois qu’ils parvenaient à obtenir des informations d’identification sur les buckets S3, les attaquants se servaient d’un outil Windows appelé S3 Browser pour interagir avec l’API S3 et exfiltrer toutes les données qu’ils contenaient. Une fois tous les fichiers téléchargés, ils les ont supprimés et ont laissé un fichier de rançon informant le propriétaire qu’ils ont désormais accès à ses informations sensibles et qu’ils prévoient de les vendre s’ils ne sont pas payés. Les cybercriminels ont accédé aux comptes AWS et aux buckets S3 depuis le réseau Tor, les VPN publics ou depuis l’intérieur de l’infrastructure AWS elle-même en utilisant d’autres comptes compromis. Cependant, les chercheurs ont détecté deux cas où les attaquants se sont connectés directement à partir d’adresses IP attribuées à des FAI en Ukraine et au Maroc.
Ils conseillent aux organisations d’activer la journalisation S3 ou CloudTrail pour les événements des buckets S3 afin de pouvoir mener des investigations en cas d’incident. Ces paramètres ne sont pas activés par défaut et peuvent augmenter le coût de l’environnement cloud car ils mobilisent des ressources, mais ils en valent la peine pour pouvoir évaluer avec précision ce qui s’est passé en cas de compromission. « En fonction des services AWS utilisés, les entreprises devront s’assurer qu’elles activent la journalisation spécifique à ce service », ont déclaré les chercheurs. Une fois qu’elles ont mis en place la journalisation et la conservation appropriées de ces données (une conservation minimale de 90 jours est recommandée), l’accent doit être mis sur la surveillance ». Le service GuardDuty d’AWS propose ainsi des fonctions d’alerte en cas d’abus d’identifiants et de ressources EC2. Les entreprises peuvent créer leurs propres alertes en cas d’activité anormale dans les données de journal.
Pour terminer, les experts déconseillent fortement d’utiliser des clés d’accès IAM à long terme dans les applications et de s’appuyer plutôt sur les rôles IAM qui ne fournissent qu’un accès temporaire. Le principe du moindre privilège doit être respecté lors de la configuration de l’accès aux ressources IAM. L’accès aux régions AWS non utilisées devrait également être désactivé afin que les attaquants ne puissent pas déployer des ressources dans des régions supplémentaires.

Les deux vulnérabilités concernant les logiciels de l’éditeur allemand ont une appréciation CVSS supérieure à 9 et peuvent permettre l’accès à des données sensibles si elles ne sont pas corrigées immédiatement.
SAP a scellé une série de bogues graves affectant ses systèmes, dont deux vulnérabilités critiques qui peuvent compromettre totalement le système. Lors de son Security Patch Day d’août 2024, le géant du logiciel allemand a déployé des correctifs pour un total de 17 vulnérabilités, avec six correctifs critiques – CVSS allant de 7 à 10 sur 10 – et d’autres correctifs de gravité modérée à moyenne. Le fournisseur a demandé que toutes ces failles soient corrigées immédiatement avec leurs mises à jour respectives et a également recommandé des solutions de contournement pour certaines d’entre elles si la correction n’est pas possible immédiatement.
Deux vulnérabilités critiques
Parmi les deux failles critiques corrigées, la plus grave est une vulnérabilité de contournement d’authentification (CVE-2024-41730) avec une évaluation CVSS de 9,8/10 affectant la plateforme analytique BusinessObjects, tandis que l’autre est une vulnérabilité de falsification des requêtes côté serveur (SSRF) dans les applications construites avec Build Apps. La CVE-2024-41730, telle que décrite par SAP, provient d’une vérification d’authentification manquante dans sa plateforme BI. « Dans SAP BusinessObjects Business Intelligence Platform, si le SSO (Single Signed On) est activé sur l’authentification Enterprise, un utilisateur non autorisé peut obtenir un jeton de connexion à l’aide d’un point de terminaison REST », a déclaré l’éditeur dans un avis de sécurité. L’attaquant peut compromettre entièrement le système, ce qui a un impact important sur la confidentialité, l’intégrité et la disponibilité, a ajouté SAP.
Le bogue SSRF CVE-2024-29415, cependant, est dû à une catégorisation incorrecte des adresses IP dans le paquet « ip » de Node.js. Ce problème, note SAP, existe à cause d’un correctif incomplet pour CVE-2023-42282. « Le paquet ip 2.0.1 pour Node.js pourrait permettre SSRF parce que certaines adresses IP (telles que 127.1, 01200034567, 012.1.2.3, 000:0:0000::01, et ::fFFf:127.0.0.1) sont incorrectement catégorisées comme globalement routables via isPublic », a ajouté le fournisseur.
SAP est une cible fréquente
Les vulnérabilités de SAP sont particulièrement recherchées par les cyberactivistes, comme le montre une étude récente qui a révélé une augmentation par 5 des attaques de ransomware ciblant les systèmes SAP depuis 2021. Le ransomware étant le principal type d’attaque contre les systèmes SAP, il y a une forte motivation pour les paydays. D’autres vulnérabilités graves ont été corrigées en même temps que les deux correctifs critiques : CVE-2024-34688 : Déni de service (DOS) dans NetWeaver AS Java, CVE-2024-42374 : une injection XML dans BEx Web Java Runtime Export Web Service, CVE-2023-30533 : Pollution de prototype dans S/4 HANA, et CVE-2024-33003 : Vulnérabilité de divulgation d’informations dans Commerce Cloud. Bien que toutes ces brèches aient été classées comme étant de gravité « élevée », l’exploitabilité peut varier en fonction des conditions d’accès pour l’acteur de la menace et des privilèges qu’il autorise. Il est conseillé aux administrateurs d’appliquer ces correctifs au plus tôt afin de se protéger contre les attaquants ciblant les systèmes SAP. L’étude a également mis en évidence une augmentation de 490 % des conversations sur les vulnérabilités et les exploits SAP sur le dark web entre 2021 et 2023.

Les cybercriminels soutenus par des Etats multiplient les techniques d’attaque qui ont fait leurs preuves dans l’exploitation des services de stockage cloud gratuits, avec un objectif de commande et de contrôle (C2).
Selon une étude de Symantec, un nombre croissant de groupes APT (Advanced Persistent Threat) exploitent les services de stockage dans le cloud proposés par Microsoft et Google pour en prendre le contrôle et exfiltrer des données. Si l’utilisation abusive de ces services gratuits par les cybercriminels n’est pas rare, de récentes preuves suggèrent que les groupes de cyberespionnage parrainés par des États sont de plus en plus nombreux à mener ce genre d’attaques. « Ces dernières semaines seulement, l’équipe de chasseurs de menaces de Symantec a identifié trois nouvelles opérations d’espionnage utilisant des services cloud et a trouvé des preuves de l’existence d’autres outils en cours de développement », ont déclaré les chercheurs de la division Symantec de Broadcom dans un billet de blog.
Leurs conclusions ont été présentées à la conférence sur la sécurité Black Hat USA organisée à Las Vegas L’utilisation abusive de services cloud gratuits présente des avantages évidents pour les attaquants, car non seulement ils offrent une solution rapide et peu coûteuse, mais surtout, ils permettent une communication plus furtive à l’intérieur des réseaux. En effet, la probabilité que les produits de sécurité ou les parefeux signalent comme suspectes les connexions à des services largement utilisés comme Microsoft OneDrive ou Google Drive, par rapport à une adresse IP en Chine, par exemple, est faible.
Des inconvénients pour l’attaquant, mais il y a des parades
Cette pratique présente aussi certains inconvénients importants. Tout d’abord, le compte cloud utilisé à des fins malveillantes sera suspendu dès que les chercheurs en sécurité l’auront identifié et signalé au fournisseur de services, ce qui risque de perturber l’opération. En comparaison, si des chercheurs découvrent un serveur de commande et de contrôle C2 privé, leur seule option est de partager son adresse IP afin qu’il puisse être bloqué par les produits et les équipes de sécurité. Mais l’opération prend du temps et toutes les victimes ne seront pas nécessairement protégées. Un compte cloud peut aussi fournir aux chercheurs une mine d’informations supplémentaires sur l’opération si le fournisseur de services coopère et partage les journaux d’activité du compte et tous les fichiers stockés à l’intérieur.
Cette divulgation peut compromettre la sécurité opérationnelle des attaquants, ce qui est un aspect important, en particulier pour les acteurs du cyberespionnage qui agissent pour le compte d’États-nations. Cependant, des solutions existent pour parer à ces inconvénients. Par exemple, les attaquants peuvent coder en dur dans leurs logiciels malveillants des canaux C2 de secours qui seront utilisés au cas où le canal principal, basé sur les services cloud, cesse soudainement de fonctionner. Ils peuvent aussi utiliser le chiffrement pour dissimuler leurs activités et les fichiers exfiltrés aux enquêteurs qui accèdent au compte du service cloud malveillant. Ces contre-mesures sont relativement courantes, ce qui rend l’utilisation abusive des services cloud par les APT beaucoup plus viable.
De nouveaux implants de malwares
Une menace capable de tirer parti des services Microsoft pour la commande et le contrôle C2 est apparue récemment sous forme de programme de porte dérobée appelé GoGra. Écrit dans le langage de programmation Go, ce programme a été déployé contre un média en Asie du Sud en novembre de l’année dernière. Selon l’équipe de Symantec, la porte dérobée pourrait être une évolution ou une réimplémentation d’une autre porte dérobée connue sous le nom de Graphon, écrite en .NET et attribuée à un groupe soutenu par un État-nation. Ce groupe, baptisé Harvester par Symantec, cible des entreprises d’Asie du Sud depuis 2021.
GoGra exploite l’API Microsoft Graph pour accéder au service de messagerie Outlook à l’aide de jetons d’accès OAuth pour un nom d’utilisateur appelé FNU LNU. La porte dérobée accède à la boîte aux lettres Outlook et lit les instructions des messages électroniques dont l’objet contient le mot « Input ». Cependant, le contenu des messages est chiffré avec AES-256 et le logiciel malveillant les déchiffre avec une clé codée en dur. « GoGra exécute des commandes via le flux d’entrée cmd.exe et prend en charge une commande supplémentaire nommée cd qui modifie le répertoire actif », ont expliqué les chercheurs de Symantec. « Après l’exécution d’une commande, il chiffre la sortie et l’envoie au même utilisateur avec l’objet Output ». Un deuxième implant de malware APT exploitant l’API Microsoft Graph, appelé Trojan.Grager, a été utilisé contre des entreprises de Taïwan, de Hong Kong et du Vietnam en avril. La porte dérobée a été distribuée via un programme d’installation trojanisé pour le gestionnaire d’archives 7-Zip, et elle utilise Microsoft OneDrive au lieu d’Outlook à des fins C2. La porte dérobée peut télécharger, téléverser et exécuter des fichiers et recueille des informations sur le système et la machine.
Des techniques similaires utilisées par de nombreux acteurs de la menace
Des liens présumés existent entre Grager et un groupe APT que l’équipe Mandiant de Google suit sous le nom de UNC5330, car le même programme d’installation de 7-Zip contenant des chevaux de Troie a également déposé une backdoor appelée Tonerjam, associée à ce groupe. Les chercheurs pensent que le groupe UNC5330 est un « acteur d’espionnage lié à la Chine ». Il ferait aussi partie des groupes qui ont exploité les appareils Ivanti Connect au début de l’année 2024. Une autre porte dérobée à plusieurs niveaux, appelée Onedrivetools ou Trojan.Ondritols, utilise aussi l’API Microsoft Graph pour télécharger une charge utile de deuxième niveau à partir de Microsoft OneDrive. Cette porte dérobée a été utilisée contre des entreprises de services IT aux États-Unis et en Europe.
Les chercheurs de Symantec ont également découvert en mai une menace appelée BirdyClient, utilisée contre une organisation ukrainienne qui utilise OneDrive comme serveur C2 via l’API Graph. Une autre nouvelle porte dérobée, baptisée MoonTag, qui semble toujours en cours de développement et téléchargée récemment sur VirusTotal, utilise l’API Microsoft Graph. Cette porte dérobée a probablement été créée par un acteur chinois et utilise des échantillons de code pour la communication avec l’API Graph précédemment partagés dans un groupe Google en langue chinoise. Certains groupes préfèrent Google Drive au service de stockage de fichiers de Microsoft. Par exemple, un outil d’exfiltration de données, jamais signalé jusque-là, a été utilisé contre une cible militaire en Asie du Sud-Est par un groupe de cyberespionnage connu sous le nom de Firefly. Cet outil, écrit en Python, recherchait sur l’ordinateur local des fichiers images au format jpg, puis les téléchargeait sur un compte Google Drive à l’aide d’un client Google Drive open source et d’un token codé en dur.
Par le passé, d’autres acteurs du cyberespionnage ont occasionnellement utilisé des services gratuits de stockage de fichiers dans le cloud à des fins de C2, notamment le groupe APT37 (Vedalia) affilié à la Corée du Nord en 2021, le groupe APT28 (Fancy Bear) affilié à la Russie en 2022 et le groupe APT15 (Nickel) affilié à la Chine en 2023. Cependant, selon les observations de Symantec, la quantité de menaces APT adoptant cette technique a nettement augmenté au cours de l’année écoulée. « Vu le nombre d’acteurs qui déploient aujourd’hui des attaques exploitant des services cloud, on peut penser que les acteurs de l’espionnage étudient clairement les menaces créées par d’autres groupes et cherchent à reproduire des techniques qui ont l’air de fonctionner », ont déclaré les chercheurs.

La mise en oeuvre d’une stratégie d’intelligence artificielle générative efficace ne coule pas de source. Focus sur cinq leviers à actionner pour réussir son projet.
Qu’est-ce qui rend la mise en œuvre de l’IA générative si difficile ? En tant que technologie de rupture, elle se fait sentir à la fois par son ampleur et par la fréquence des changements. Il y a tant de fournisseurs, d’applications et de cas d’utilisation, et si peu de temps, qu’elle imprègne tout, de la stratégie et des processus d’entreprise aux produits et services. L’un des défis inhabituels que pose l’IA en tant que technologie est qu’elle est actuellement adoptée par le grand public tout en étant encore au sommet en termes d’engouement. C’est pourquoi de nombreuses entreprises mettent beaucoup d’énergie et d’enthousiasme dans les cas d’usage, mais ont encore du mal à obtenir un retour sur investissement. Pour le maximiser, des efforts et des investissements en matière d’IA sont importants pour passer d’une expérimentation ad hoc à une stratégie plus ciblée et à une approche systématique de mise en œuvre. Zoom sur cinq bonnes pratiques à suivre pour tirer le meilleur parti de la GenAI.
Définir une stratégie GenAI holistique
La définition d’une stratégie d’intelligence artificielle générative devrait s’inscrire dans une approche plus large de l’IA, de l’automatisation et de la gestion des données. Après tout, une stratégie de données moderne doit prendre en compte et renforcer l’ensemble de la pile IT en soutenant les objectifs de l’entreprise en matière d’automatisation, ainsi qu’une myriade d’applications soutenant les transactions, l’analyse et la prise de décision. Il suffit de regarder le récent lancement d’EDB Postgres AI, une plateforme taillée pour les workloads transactionnels, analytiques et d’IA. Les mises en œuvre réussies de l’IA dépendent à 80 % de l’aspect des données comme de leur qualité et il faut donc s’attendre à voir encore plus de suppression de silos entre ces types de charges de travail. Une bonne stratégie doit définir des thèmes stratégiques pour l’entreprise autour de l’IA générative et la manière dont elle accompagnera les différents objectifs de la société. Lesquels de ces thèmes soutiennent le programme de croissance, l’efficacité interne et les économies de coûts ? Il faut pour cela savoir comment différencier, pour les produits et les services, une proposition de valeur unique avec des objectifs stratégiques en termes de résultats escomptés.
Identifier et hiérarchiser les cas d’usage
Il existe probablement des dizaines de cas d’utilisation de l’IA dans son entreprise et, bien que nombre d’entre eux soient naturellement identifiés par les utilisateurs finaux, il est important de dresser une liste de référence. Pour les connaitre, créer une zone de collaboration sur l’IA dans l’intranet de son entreprise et inviter les parties prenantes à partager ce sur quoi ils travaillent et leurs résultats est préconisé. Cela permet de répertorier les activités dans l’ensemble de l’entreprise et d’encourager le partage des connaissances et la coordination. En reprenant la liste principale des activités en cours et en la cartographiant sur une carte du parcours client, ou même sur une carte des processus de son entreprise, il est conseillé de rechercher les lacunes et les chevauchements dans la couverture, identifier d’autres zones d’opportunités, et commencer à établir des priorités. Même si la mise en œuvre de plusieurs cas d’utilisation est bien avancée, un atelier d’innovation peut être un excellent moyen d’amener les utilisateurs finaux à réfléchir à des cas d’utilisation et à les classer par ordre de priorité. Il est aussi utile de rechercher à la fois les gains rapides (impact commercial élevé et grande facilité de mise en œuvre) et incontournables (impact commercial élevé, mais facilité de mise en œuvre moindre en raison du temps, du coût ou du risque et de la complexité du projet), puis de les ajouter en conséquence à une feuille de route de mise en œuvre.
Expérimenter avec des objectifs
La GenAI provoquant énormément d’engouement, il est probable qu’il y ait beaucoup de test en cours sans que l’on se concentre de manière cohérente sur les finalités. Cependant, avec quelques petites modifications, il est possible d’exploiter cette énergie en encourageant les projets pilotes et les expérimentations, et en donnant aux utilisateurs finaux les moyens d’être des innovateurs et des testeurs. Pour favoriser une culture de l’innovation, ces petites modifications doivent inclure des conseils, un soutien et des encouragements. Par exemple, si les utilisateurs finaux essaient un outil pour la synthèse vocale, pourquoi ne pas les encourager à essayer deux ou trois outils différents et à comparer les résultats. Pour les aider à trouver le meilleur choix pour la société, il est recommandé de partager des détails sur les normes de l’entreprise, les considérations budgétaires et les fournisseurs à envisager en plus de leurs favoris actuels.
Partager les garde-fous
Tout en favorisant la culture de l’innovation en encourageant l’expérimentation et les projets pilotes, il faut aider les utilisateurs finaux à relever les défis de l’IA en partageant les garde-fous de l’entreprise. Une première action simple consiste à élaborer sa propre politique d’utilisation dans l’entreprise, ainsi qu’à signer divers accords sectoriels le cas échéant. Pour l’IA et d’autres domaines, une politique d’utilisation peut aider à sensibiliser les utilisateurs aux zones de risques potentiels, et donc à gérer le risque, tout en encourageant l’innovation. Bien que chaque secteur ait ses propres priorités en termes de risques liés à l’IA, dans le secteur de l’architecture, de l’ingénierie et de la construction, il a été constaté que la protection des données et la confidentialité constituent une préoccupation majeure. Il est donc utile d’informer les utilisateurs sur les avantages et les inconvénients des GPT publics et privés et de leur indiquer quand utiliser l’un, l’autre ou les deux. Cela peut également avoir une incidence sur le choix de certains fournisseurs. Par exemple, l’IA intégrée d’un fournisseur de longue date peut être le mauvais choix s’il utilise les données de sa communauté d’utilisateurs pour former son modèle.
Intégrer le ROI dès le début
L’IA générative et de nombreuses autres technologies étant évaluées et utilisées par un large éventail d’employés en dehors du département IT, il est important de leur fournir les outils nécessaires pour que leur mise en œuvre soit couronnée de succès pour l’entreprise. Pour ce faire, il est essentiel de fournir une analyse de rentabilité de l’usage de la technologie et de la manière de calculer le retour sur investissement. À cet égard, la GenAI n’est pas différente des autres technologies. Il s’agit d’examiner la proposition de valeur et la différenciation concurrentielle pour les produits et services destinés aux clients, ainsi que les gains d’efficacité en termes de temps et de coûts pour les processus internes. Une simple feuille de calcul du ROI peut constituer un excellent point de départ et aider les employés à examiner la situation avant et après et la manière dont l’intelligence artificielle générative peut contribuer à rationaliser les opérations. Dans l’ensemble, en raison du rythme rapide des changements dans cet environnement, il est essentiel d’avoir une stratégie adaptative, d’être prêt à la mettre à jour régulièrement si nécessaire et de poursuivre l’apprentissage et l’amélioration continus tout au long des mises en œuvre. Avancer à petits pas pour obtenir des résultats rapides et démontrer le retour sur investissement dès le début sans oublier de se concentrer également sur les incontournables et les initiatives plus stratégiques qui contribueront à différencier votre organisation dans les années à venir. Voilà aussi certainement une clé de succès de sa stratégie GenAI.
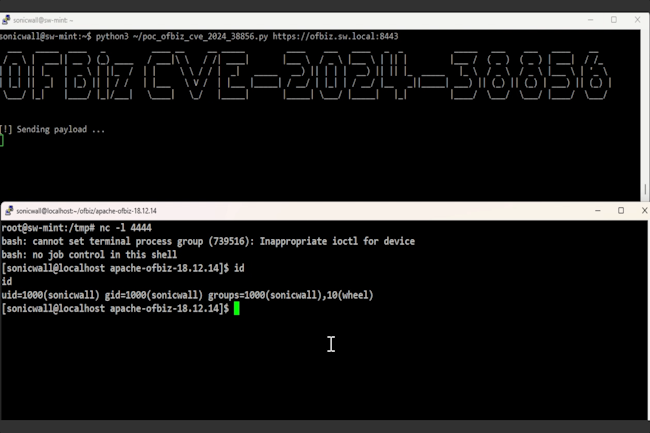
En analysant le patch d’une faille actuellement ciblée par es attaquants, les chercheurs ont découvert une autre vulnérabilité de type RCE dans Apache OFbiz. C’est la cinquième faille critique qui affecte cette année le framework ERP. La CISA invite les utilisateurs à mettre à jour le plus rapidement possible.
Des chercheurs de SonicWall signalent une vulnérabilité critique dans le système et framework ERP open source Apache OFBiz. La faille entraînant une exécution de code à distance sans authentification, a été corrigée peu après l’exploitation dans la nature d’une autre vulnérabilité corrigée en mai. Considérée comme critique, la vulnérabilité, référencée CVE-2024-38856, touche les versions d’Apache OFBiz jusqu’à la version 18.12.14. Elle a été corrigée dans la version 18.12.15 publiée le 3 août.
Un module très utilisé
Initialement baptisée Open for Business, Apache OFBiz offre des modules pour la gestion des processus d’entreprise comme la comptabilité, les ressources humaines, la gestion de la supply chain, la gestion des catalogues de produits, la gestion de la relation client (CRM), la fabrication, le commerce électronique, et bien plus encore. Ces modules reposent sur un framework de développement web basé sur Apache, qui peut également servir à créer des applications et des fonctions personnalisées supplémentaires.
On ne sait pas exactement combien d’entreprises exécutent Apache OFBiz, car beaucoup peuvent l’utiliser en interne, mais d’après les données publiques, de grandes entreprises comme IBM, HP, Accenture, United Airlines, Home Depot et Upwork font partie des utilisateurs connus. Certaines applications commerciales tierces, comme Jira d’Atlassian se servent aussi des modules OFBiz. Le projet est utilisé dans le monde entier et dans de nombreux secteurs, mais plus de 40 % des utilisateurs connus sont basés aux États-Unis.
L’analyse de la précédente faille à l’origine de la découverte
La faille découverte se trouve dans la fonctionnalité « override view » et permet à des attaquants non authentifiés d’accéder à des points d’extrémité sensibles et restreints en utilisant des requêtes spécialement conçues, rendant possible l’exécution de code à distance. En fait, c’est en analysant le correctif d’OFBiz pour une autre faille de traversée de répertoire corrigée dans la version 18.12.14 à la fin du mois de mai que les chercheurs de SonicWall ont découvert la vulnérabilité. Cette précédente faille, référencée CVE-2024-36104, peut aussi entraîner l’exécution de code à distance. Depuis sa divulgation, elle a fait l’objet d’une preuve de concept, mais à la fin du mois de juillet, le SANS Internet Storm Center a signalé des tentatives d’exploitation de cette faille dans la nature.
Il convient de noter qu’une autre faille de contournement de l’authentification (CVE-2023-51467) découverte par les chercheurs de SonicWall dans OFBiz en décembre 2023 a également été exploitée plus tard dans la nature. Il semble qu’OFBiz intéresse les attaquants et que les applications construites avec le framework exposées à Internet courent un risque immédiat. À noter aussi que la faille CVE-2024-38856 est la cinquième vulnérabilité de sécurité classée comme critique ou importante trouvée et corrigée dans OFBiz cette année. Les entreprises qui utilisent ce framework ERP devraient mettre à jour vers la dernière version dès que possible et s’assurer qu’OFBiz est couvert par leurs produits de surveillance des vulnérabilités. SonicWall a félicité les développeurs d’OFBiz pour leur réponse rapide, car ils ont renvoyé un correctif fonctionnel pour analyse en moins de 24 heures. La CISA prend l’affaire au sérieux en poussant les entreprises à appliquer rapidement le correctif.
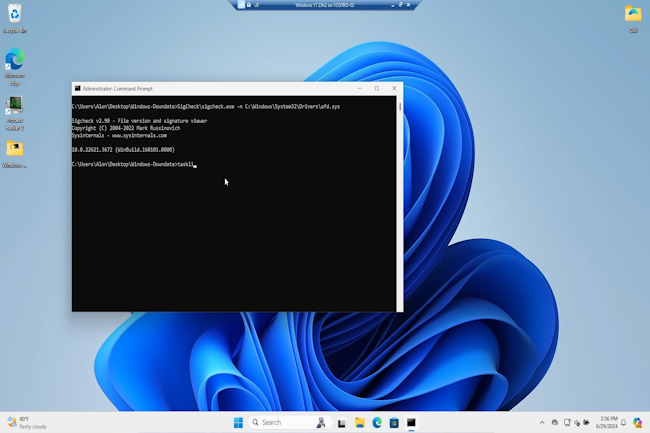
Un chercheur a pu rétrograder plusieurs composants de Windows Update pour rendre l’OS vulnérable à d’anciennes failles. Microsoft a semble-t-il discrètement corrigé une des failles. L’expert veut sensibiliser sur les attaques par repli.
Peut-on faire confiance dans Windows Update, l’outil de mise à jour automatique de l’OS de Microsoft ? La question mérite d’être posée après la découverte d’une grave faille dans ce service. Au lieu de protéger les ordinateurs, il peut être détourné pour installer des versions plus anciennes et plus vulnérables du système d’exploitation. Cela permet aux cybercriminels de contourner les mesures de sécurité et d’attaquer les PC même si les dernières mises à jour sont installées. C’est comme si l’on remontait le temps pour trouver la vulnérabilité parfaite à exploiter.
Alon Leviev, chercheur en sécurité chez SafeBreach, a dévoilé une technique (baptisée Windows Downdate) où les acteurs malveillants peuvent manipuler le processus de mise à jour de Windows pour rétrograder les composants critiques du système, rendant ainsi les correctifs de sécurité inutiles. « Avec Windows Downdate, j’ai pu prendre le contrôle total du processus de mise à jour de Windows, en rétrogradant des composants clés du système d’exploitation, notamment des DLL, des pilotes et même le noyau NT » a déclaré le spécialiste lors de la présentation de ses recherches à la conférence Black Hat qui vient de s’achever à Las Vegas. « Cela m’a permis de contourner toutes les étapes de vérification et de rendre une machine Windows entièrement corrigée sensible à des milliers de vulnérabilités antérieures ».
Une inspiration de BlackLotus
Alon Leviev s’est inspiré du BlackLotus UEFI Bootkit 2023, qui a démontré la gravité de telles attaques en dégradant le gestionnaire de démarrage de Windows pour exploiter la CVE-2022-21894, en contournant le Secure Boot et en désactivant d’autres mécanismes de sécurité du système d’exploitation. « Le malware pouvait persister même sur des systèmes Windows 11 entièrement corrigés, ce qui a déclenché l’alarme dans la communauté de la cybersécurité », a ajouté le chercheur.
« J’ai trouvé plusieurs vulnérabilités que j’ai utilisées pour développer Windows Downdate – un outil permettant de prendre le contrôle du processus de mise à jour de Windows afin de créer des rétrogradations totalement indétectables, invisibles, persistantes et irréversibles sur les composants critiques du système d’exploitation – qui m’ont permis d’élever les privilèges et de contourner les fonctions de sécurité », a-t-il déclaré dans le rapport de recherche. Il ajoute, « en conséquence, j’ai pu rendre une machine Windows entièrement corrigée sensible à des milliers de vulnérabilités antérieures, transformant les failles corrigées en zero day et rendant le terme « entièrement patché » insignifiant ».
Réaction discrète de Microsoft
Microsoft n’a pas encore fait de déclaration publique sur les résultats de la recherche. Une demande de commentaires par notre confrère de CSO est restée sans réponse. Toutefois, l’éditeur a publié deux avis – CVE-2024-38202 et CVE-2024-21302 – mercredi, en même temps que la présentation de la conférence. « Microsoft a été informé de l’existence d’une vulnérabilité d’élévation de privilèges dans Windows Backup, permettant potentiellement à un attaquant disposant de privilèges d’utilisateur de base de réintroduire des vulnérabilités précédemment atténuées ou de contourner certaines fonctionnalités de la sécurité basée sur la virtualisation (VBS) » , a déclaré l’entreprise dans un communiqué.
Dans sa présentation, le chercheur a indiqué avoir pu contourner VBS, une fonction de sécurité critique conçue pour protéger contre les menaces avancées. Cette découverte met en évidence la possibilité pour les attaquants de contourner les mesures de sécurité les plus robustes.
Une sensibilisation aux attaques par repli
Il est nécessaire d’accroître la sensibilisation et la recherche sur les attaques par repli de système d’exploitation, a-t-il suggéré dans le rapport. « Au cours de ce processus, je n’ai trouvé aucune mesure d’atténuation empêchant la rétrogradation des composants critiques du système d’exploitation dans Windows ». Un avis partagé par Arjun Chauhan, analyste principal chez Everest Group qui critique le silence de la firme de Redmond, « bien que Microsoft ait déclaré qu’il n’avait pas observé d’attaques de ce type dans la nature, l’absence de solution fiable six mois après que l’équipe SafeBreach a signalé la vulnérabilité soulève des inquiétudes quant à la capacité de Microsoft à résoudre efficacement ce problème ».
En termes d’impact, ces offensives « pourraient avoir de profondes implications pour les entreprises fortement dépendantes des environnements Windows », a souligné le consultant. Il ajoute « ces attaques peuvent annuler les correctifs de sécurité, exposant à nouveau les systèmes à des vulnérabilités précédemment atténuées, augmentant ainsi le risque de violation de données, d’accès non autorisé et de perte d’informations sensibles ». En outre, ces attaques peuvent perturber les opérations en compromettant les infrastructures critiques, ce qui entraîne des temps d’arrêt et des pertes financières.

IBM a ajouté des capacités d’IA générative, via le Cybersecurity Assistant, à ses services managés de détection et de réponse aux menaces.
L’IA générative continue de se diffuser dans les produits et services d’IBM. Le dernier en date est l’offre managée de détection et réponse aux menaces, TDR. Avec l’apport du Cybersecurity Assistant, elle aidera les analystes du monde entier à répondre plus rapidement aux alertes de sécurité. « Les récentes capacités peuvent réduire de 48% les temps d’investigation sur les alertes », a affirmé IBM. Le Cybersecurity Assistant fonctionne en analysant les modèles d’activité des menaces, spécifiques à un client et à son historique, et il aide les analystes de la sécurité à mieux comprendre les menaces critiques grâce à une vue chronologique des séquences d’attaque.
Généralement, les plateformes de TDR (Threat Detection and Response) recueillent des informations à partir des environnements d’entreprise des clients, comme les serveurs, les terminaux et autres dispositifs. Les services TDR d’IBM intègrent également des informations provenant du réseau mondial de capteurs d’IBM X-Force et de l’analyse des renseignements. Son assistant recommandera aussi des actions basées sur les modèles historiques de l’activité analysée et les niveaux de confiance prédéfinis, ce qui accélérera les temps de réponse pour les clients et laissera moins de marge aux attaquants pour infiltrer un système. Selon IBM, le Cybersecurity Assistant continuera à apprendre des enquêtes, de façon à rendre les futures réponses encore plus rapides et plus précises.
Réduire le bruit
L’idée est d’aider les entreprises clientes à maîtriser la myriade de vulnérabilités, d’alertes et d’outils de sécurité qu’elles doivent gérer au quotidien. « Avec l’IA et d’autres capacités d’analyse, les services TDR managés d’IBM peuvent automatiser le bruit et laisser les équipes IT se concentrer sur l’escalade des menaces critiques pour l’entreprise », a déclaré IBM. « En améliorant nos services de détection des menaces et de réponse avec l’IA générative, nous pouvons faire en sorte que les analystes de la sécurité aient moins de tâches manuelles et opérationnelles à effectuer, répondre de manière plus proactive et plus précise aux menaces critiques, et renforcer la posture de sécurité globale de nos clients », a fait valoir Mark Hughes, directeur mondial associé des services de cybersécurité chez IBM Consulting, dans un communiqué.
Proposé par IBM Consulting, le service TDR managé comprend la surveillance 24×7, l’investigation et la remédiation automatisée des alertes de sécurité qui proviennent des outils de sécurité existants ainsi que des systèmes technologiques du cloud, sur site et opérationnels qui utilisent le réseau de l’entreprise. Les services peuvent intégrer des informations provenant de plus de 15 outils de gestion des incidents et des événements de sécurité (Security Information and Event Management, SIEM) et de multiples solutions tierces de MDR (Managed Detection and Response) pour les points d’accès et les réseaux, par exemple. Sur ce marché très étendu des services MDR, IBM est en concurrence avec des fournisseurs comme Arctic Wolf, eSentire, CrowdStrike, Fortinet, Mandiant, Red Canary et d’autres, qui proposent des services similaires.