





La marque de vêtements Patagonia est accusée d’avoir récolté, conservé et traité des données clients avec une GenAI. Une affaire qui souligne le casse-tête légal que les DSI doivent résoudre en la matière. Pas question de faire l’autruche pour autant.
Le concepteur et distributeur de vêtements de plein air Patagonia est poursuivi pour avoir enfreint la loi californienne sur la protection de la vie privée. L’entreprise exploiterait en effet l’IA générative de l’éditeur Talkdesk pour intercepter, enregistrer et analyser les conversations avec des clients sans leur permission. La plainte, déposée le 15 juillet, spécifie que l’éditeur redirige et stocke en temps réel tous les échanges avec des clients et des partenaires commerciaux vers ses propres serveurs et, après leur transcription, « utilise ses modèles d’IA pour analyser les mots des appelants afin de déterminer de quoi ils parlent et comment ils se sentent durant l’échange ». Une demande de requalification en class action a également été déposée.L’action en justice fait référence à l’un des produits d’IA de Talkdesk, Copilot, qu’il décrit lui-même comme un « assistant GenAI qui écoute, guide et assiste les agents du call center lors des interactions avec les clients. Par exemple, Copilot suggérera automatiquement des réponses pertinentes aux agents dans les chats, les e-mails, les appels et les SMS en fonction du contenu des échanges. Talkdesk enregistre toutes ces informations dans le cloud et crée un historique des interactions, ce qui permet aux entreprises de garder la trace des conversations précédentes des clients, même si elles ont eu lieu sur un support différent. Toutes ces données sont stockées sur les serveurs de Talkdesk. » De son côté, Patagonia affiche dans sa politique de confidentialité une description générique du type de partage de données qu’il exerce en général, mais elle ne précise absolument pas ce que fait Talkdesk.Le litige implique ainsi trois acteurs distincts : l’entreprise, en l’occurrence Patagonia ; un tiers, en l’espèce Talkdesk, fournisseur de solutions SaaS de call center à base d’IA ; les outils d’IA utilisés par l’un ou l’autre. L’action en justice vise ainsi directement Patagonia et Talkdesk, mais elle met aussi très clairement en cause la façon dont les IA exploitent les données récoltées.Migraines en vue pour les DSIUn des problèmes soulevés réside dans un paradoxe lié à l’exploitation de l’IA générative. Les DSI d’une entreprise sont en effet tenus d’identifier précisément toutes les données que le SI collecte et la manière dont elles sont utilisées. Reste qu’avec la GenAI, ils n’en ont tout simplement aucune idée ! De quoi rendre les DSI, mais aussi les services juridiques très nerveux.Mark Rasch, avocat spécialisé dans les questions de technologie et de confidentialité, imagine plusieurs scénarios dans une telle situation. Que se passerait-il, par exemple, si un consommateur appelait un retailer et se lançait dans une discussion animée au sujet d’un éventuel remboursement de produit ? Même une fois le problème résolu, l’analyse des émotions par la GenAI pourrait néanmoins étiqueter le client comme difficile et fauteur de troubles. Si des centaines d’autres retailers et entreprises utilisent ensuite le même logiciel, que se passe-t-il si celui-ci décide de conseiller aux call centers de ces organisations de couper court aux conversations avec ce client si elles durent trop longtemps ? Ou s’il recommande que toutes les demandes de remboursement de ce client soient rejetées ?L’absence totale de transparence de la GenAI« Avec l’IA, personne ne peut dire avec certitude comment les données sont utilisées ou comment elles seront utilisées à l’avenir, rappelle Mark Rasch. Cela signifie qu’il est probablement impossible de démontrer le lien de cause à effet. » Pour l’avocat, la racine du problème se trouve dans l’imprévisibilité de l’IA elle-même, en particulier de la GenAI. Il ne s’agit pas seulement ici des hallucinations.L’IA apprend et s’ajuste en permanence, ce qui signifie que personne ne peut savoir précisément comment elle va réagir, quelles données elle va recueillir, quelles informations elle va en déduire et comment elle va exploiter ces data.Or, comme le souligne Mark Rasch, « chaque fois qu’une entreprise collecte des données à quelque fin que ce soit, elle doit informer le client non seulement de ce qui est collecté, mais aussi de toutes les utilisations prévues. C’est particulièrement vrai lorsque les données sont exploitées à des fins d’IA. » Sauf qu’encore une fois, l’incertitude liée à l’IA peut rendre les deux tâches pratiquement impossibles.Tracer une limite claireCela oblige les DSI à distinguer clairement d’une part la data que leur équipe collecte délibérément et de quelle façon ce recueil est assuré, et, d’autre part, celle que l’IA collecte et comment elle va l’utiliser plus tard. Les DSI doivent s’en tenir strictement à ce qu’ils connaissent.L’avocat précise qu’il ne s’agit pas ici uniquement des mots utilisés, mais aussi de la façon dont ils sont prononcés, du numéro de téléphone et de l’adresse IP utilisés, de l’heure de la journée, des bruits de fond et de tout ce que l’IA peut détecter pour analyser la situation. Les consommateurs « abandonnent volontairement beaucoup de choses lorsqu’ils passent un appel téléphonique », explique Mark Rasch. « Quand la plupart des entreprises rédigent une politique de confidentialité, elles ne tiennent pas vraiment compte de la quantité d’informations qu’elles collectent. »Un champ de mines juridiqueL’avocate Shavon Jones, spécialisée dans les stratégies d’IA au service du développement économique, précise de son côté que la législation actuelle n’a encore pas sérieusement compris l’IA, ce qui place les DSI dans une position précaire. « Où tracer la limite de la responsabilité civile de l’IA ? Je pense que nous ne le saurons pas avant de nombreuses années. Les litiges en la matière ne sont encore qu’une sous-spécialité émergente du droit », ajoute-t-elle. « À chaque fois qu’un domaine émerge, il n’y a que deux façons de décider où se trouve la ligne de démarcation : les législateurs et les régulateurs peuvent promulguer des lois et des règles, et les avocats peuvent porter des affaires devant les tribunaux dans plusieurs juridictions et laisser ces affaires faire leur chemin jusqu’à l’obtention de décisions de la Haute Cour, pour injecter de la certitude dans le droit. Mais cela prendra de nombreuses années d’essais-erreurs. »« L’IA dans le domaine des données clients est un champ de mines juridique, et les récentes poursuites judiciaires soulignent le besoin urgent de limites claires », insiste de son côté James E. Wright, avocat à Los Angeles. « Les entreprises qui repoussent les limites de l’IA doivent se rendre compte que les données des clients ne sont pas un terrain de jeu ouvert à tous vents. La limite juridique doit être fermement tracée au niveau de la transparence et du consentement. Les clients doivent au moins savoir exactement comment leurs données sont utilisées et donner leur autorisation explicite. En deçà, cela relève de l’abus de confiance et, franchement, c’est une bombe à retardement juridique. »« Les tribunaux vont continuer de travailler à définir ce périmètre, mais les entreprises doivent prendre une longueur d’avance, reprend l’avocat. Jouer de façon irresponsable avec l’IA et les données ne fera qu’entraîner davantage de poursuites judiciaires et éroder la confiance des consommateurs. Il est temps pour les entreprises de faire preuve de sagesse et de respecter les règles. »
Des chercheurs ont trouvé un moyen, via des clés de test, de rendre inutile la fonction Secure Boot lors du démarrage des systèmes d’exploitation. Plusieurs modèles de PC et de serveurs sont concernés par la faille baptisée PKfail.
Des chercheurs en sécurité avertissent que certains fabricants de PC et de serveurs utilisent des clés cryptographiques non sécurisées comme base de confiance pour Secure Boot, une fonction de sécurité importante dans les ordinateurs modernes qui empêche les malwares de s’activer au début du processus de démarrage. L’une de ces clés a fait l’objet d’une fuite accidentelle, ce qui risque de rompre les garanties de démarrage sécurisé pour des centaines de modèles d’ordinateurs provenant de sept fabricants. Cependant, près de 900 modèles au cours des 12 dernières années utilisent des clés qui ont probablement été générées à des fins de test et qui n’auraient jamais dû être utilisées en production, selon un rapport de la société de sécurité Binarly, qui a baptisé ce problème PKfail. Au début de l’année, nous avons remarqué que la clé privée d’American Megatrends International (AMI) liée à la « clé principale » de Secure Boot, appelée Platform Key (PK), avait été exposée publiquement dans une fuite de données », écrivent les chercheurs. « L’incident s’est produit chez un ODM [original design manufacturer] responsable du développement de microprogrammes pour de nombreux fournisseurs de terminaux, y compris un basé aux États-Unis. Ces équipements correspondant à cette clé sont toujours déployés sur le terrain, et la clé est également utilisée dans des terminaux d’entreprise récemment mis sur le marché. »
Secure Boot est une fonctionnalité de l’UEFI (Unified Extensible Firmware Interface), qui a succédé au BIOS (Basic Input/Output System) traditionnel présent sur les anciens ordinateurs. En principe, le Secure Boot garantit que le système ne démarre qu’avec des logiciels et des firmwares fiables. Il est essentiel de garantir l’intégrité du processus de démarrage, car les codes malveillants qui s’exécutent à ce stade précoce prennent le contrôle total du système d’exploitation, en désactivant ou en contournant ses fonctions de sécurité. Avant que le système Secure Boot ne soit largement adopté, de nombreux malwares injectaient du code dans le chargeur de démarrage des ordinateurs compromis ou dans le BIOS/UEFI lui-même. Ces bootkits – rootkits au niveau du démarrage – donnent aux attaquants une persistance de haut niveau sur les systèmes compromis et la possibilité de cacher des fichiers et des processus à tous les produits de sécurité des points finaux fonctionnant sur ces systèmes. Secure Boot utilise le chiffrement à clé publique, celles-ci sont stockées dans l’UEFI étant utilisées pour valider les composants signés avec les clés privées correspondantes. Au cœur du système se trouve une clé publique appelée « Platform Key » : cette dernière est censée être générée par le fabricant de l’ordinateur et, selon les chercheurs de Binarly, devrait être renouvelée périodiquement et, idéalement, ne pas être réutilisée d’une ligne de produits à l’autre afin de limiter l’impact d’une compromission. En outre, la clé privée doit être stockée en toute sécurité dans des modules de sécurité matériels (HSM), d’où elle ne peut pas être facilement volée ou divulguée.
Une clé privée racine qui n’a rien à faire dans un dépôt public GitHub
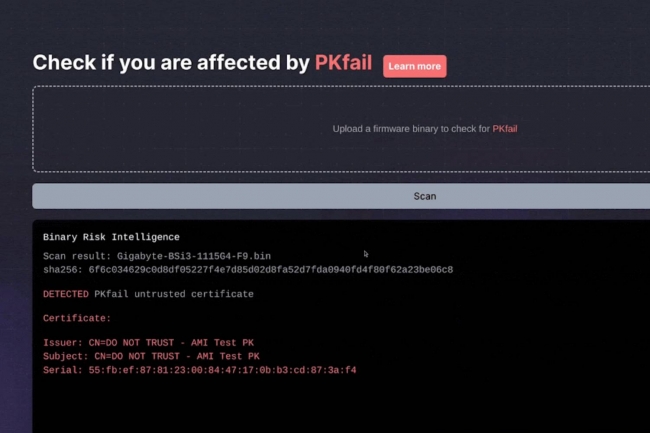
En aucun cas la clé privée racine d’un dispositif de sécurité aussi important ne devrait se retrouver dans un dépôt public sur GitHub, comme l’a fait la clé de la plateforme AMI trouvée par Binarly. Ce n’est pas le seul problème. AMI est l’un des trois fournisseurs de BIOS indépendants (IBV) qui produisent des implémentations UEFI de référence pour les fabricants de PC et les OEM, qui personnalisent ensuite ces implémentations pour leurs produits. Binarly estime que la génération de nouvelles clés de plateforme devrait faire partie de ce processus de personnalisation, car ce sont les fabricants de PC qui devraient être responsables de leurs « plateformes », et non une tierce partie. Le certificat de clé publique de la clé privée qui a fait l’objet d’une fuite comporte un champ Common Name qui indique « DO NOT TRUST – AMI Test PK » (ne pas faire confiance – AMI Test PK). Pourtant, il a été utilisé dans des centaines de modèles de sept fournisseurs différents.
« Cette clé a probablement été incluse dans leur implémentation de référence en espérant qu’elle serait remplacée par une autre clé générée en toute sécurité par les entités en aval de la chaîne d’approvisionnement », écrivent les chercheurs. « Les clés de test sont partagées avec des partenaires commerciaux et des fournisseurs en espérant qu’elles soient traitées comme des clés non fiables. En outre, la clé AMI qui a fait l’objet d’une fuite a été utilisée dans de nombreuses gammes de produits, des ordinateurs portables de jeu aux cartes mères de serveurs, ce qui accroît considérablement l’impact de la fuite dans tous les secteurs et pour tous les types d’utilisateurs.
Comment les attaquants peuvent-ils abuser de la clé divulguée ?
Secure Boot dispose de quatre emplacements de clés et de bases de données dans l’UEFI. La clé de plateforme, utilisée pour valider tous les composants du microprogramme, et une autre clé, appelée clé d’échange de clés (KEK), sont au cœur de ce système. La KEK peut servir pour mettre à jour une base de données appelée db, qui contient les signatures des chargeurs d’amorçage et d’autres composants EFI tiers autorisés à être exécutés, par exemple le chargeur d’amorçage Windows ou celui de Linux. Il peut également actualiser dbx, une base de données qui contient une liste noire de signatures, par exemple pour les bootloader vulnérables. Un attaquant disposant d’un accès privilégié au système d’exploitation d’un ordinateur qui exploite la fuite de PK peut générer une autre KEK, puis la signer et l’insérer dans l’emplacement KEK à l’aide d’outils tels que efi-updatevar. Il peut ensuite se servir de sa nouvelle clé pour modifier la base de données de signatures db afin d’y ajouter la signature d’un module .efi malveillant qu’il a créé et placé dans la partition EFI sur le disque. Ce module sera alors exécuté à l’amorçage, ce qui lui permettra de contrôler le démarrage et le noyau de Windows.
Les attaquants exploitent déjà les vulnérabilités connues de Secure Boot pour déployer des bootkits. L’année dernière, des chercheurs d’ESET ont mis en garde contre un nouveau bootkit UEFI appelé BlackLotus qui exploite une vulnérabilité de Windows connue sous le nom de Baton Drop (CVE-2022-21894) pour contourner la fonction via des composants de chargeur d’amorçage vulnérables. Il ne serait donc pas surprenant que des attaquants commencent à exploiter une fuite de la clé de plateforme. Il y a deux ans, des chercheurs d’Eclypsium ont découvert des vulnérabilités qui pouvaient être utilisées pour contourner Secure Boot, tandis que Binarly a présenté 12 autres failles qui pouvaient conduire à l’exécution de code à distance avant le démarrage dans les implémentations UEFI. La possibilité que le PK de test AMI soit tombé entre de mauvaises mains n’est pas à exclure. Selon les chercheurs de Binarly, le dépôt contenant la clé a été supprimé au bout de quatre mois, mais il a fallu cinq mois pour supprimer tous les forks. La clé privée n’était pas stockée en clair et était chiffrée, mais protégée uniquement par un mot de passe de quatre caractères qui pouvait être déchiffré en quelques secondes à l’aide d’outils de reconnaissance de mot de passe basique.
L’utilisation de clés de plateforme AMI de test dans les binaires des microprogrammes est courante.
Après avoir trouvé la clé divulguée, les experts ont découvert des rapports datant de 2016 selon lesquels certaines clés de plateforme contiennent des mots tels que « NE PAS FAIRE CONFIANCE » et « clé de test. » Il y avait même un identifiant de vulnérabilité (CVE-2016-5247) généré à l’époque pour plusieurs modèles Lenovo utilisant des clés de test AMI. Mais la clé qui a fait l’objet d’une fuite a été trouvée dans des micrologiciels publiés dès 2018 et plus récemment cette année. Pour savoir si la pratique est encore courante, les spécialistes de Binarly ont analysé leur base de données de dizaines de milliers de binaires de micrologiciels collectés au fil des ans et ont identifié 22 PK de test AMI différentes avec des avertissements « DO NOT TRUST » ou « DO NOT SHIP ». Ces clés ont été trouvées dans des binaires de microprogrammes UEFI pour près de 900 cartes mères d’ordinateurs et de serveurs différents provenant de plus de 10 fournisseurs, dont Acer, Dell, Fujitsu, Gigabyte, HP, Intel, Lenovo et Supermicro. Ensemble, ils représentaient plus de 10 % des images de microprogrammes de l’ensemble de la base.
Ces clés ne sont pas fiables, car elles ont probablement été partagées avec de nombreux fournisseurs, OEM, ODM et développeurs – et ont probablement été stockées de manière non sécurisée. Il est possible que certaines d’entre elles aient déjà fait l’objet d’une fuite ou d’un vol dans le cadre d’incidents non découverts. L’année dernière, un dump de données publié par un cybergang relatif au fabricant de cartes mères et d’ordinateurs Micro-Star International (MSI) comprenait une clé privée OEM d’Intel et, un an plus tôt, une fuite de données de Lenovo comprenait le code source d’un micrologiciel et les clés de signature Intel Boot Guard.
Binarly a mis en place un scanner en ligne permettant aux utilisateurs de soumettre des copies du micrologiciel de leur carte mère afin de vérifier s’il utilise une clé de test, et une liste des modèles de cartes mères concernés est incluse dans le bulletin de l’entreprise. Malheureusement, les utilisateurs ne peuvent pas faire grand-chose tant que les vendeurs n’ont pas fourni de mises à jour du micrologiciel avec de nouvelles clés de test générées de manière sécurisée, en supposant que les modèles de leurs cartes mères soient encore pris en charge. La première utilisation de ces clés de test trouvée par Binarly remonte à 2012.

Une mise à jour défectueuse de l’EDR CrowdStrike Falcon a placé des serveurs Windows et des PC dans un cycle de redémarrage infini, dont les organisations informatiques s’efforcent toujours de sortir. Zoom sur une panne d’ampleur exceptionnelle en 7 questions clefs.
L’éditeur de solutions de cybersécurité CrowdStrike a provoqué une série de pannes de systèmes informatiques dans le monde entier le vendredi 19 juillet, perturbant de nombreux secteurs d’activité et semant le chaos dans des aéroports, dans certaines institutions financières ou établissements de santé, entre autres. En cause, une mise à jour défectueuse de Falcon, la plateforme de détection et de réponse aux intrusions (EDR) de CrowdStrike, qui a fait planter les machines Windows et les a entraînées dans un cycle de reboot infini mettant hors service les serveurs et faisant apparaître des « écrans bleus de la mort » (BSOD, Blue Screen of Death) un peu partout dans le monde.1) Comment s’est déroulée la panne ?Les entreprises australiennes ont été parmi les premières à signaler des difficultés vendredi matin, et certaines ont continué à rencontrer des problèmes tout au long de la journée. À l’aéroport de Sydney, retards et annulations s’enchaînent. À 18 heures, heure normale à l’Est de l’Australie, Bank Australia a publié sur sa page d’accueil une annonce indiquant que les services de son centre de contact rencontraient toujours des problèmes.A mesure que la journée avance, les mauvaises nouvelles s’enchaînent. Les entreprises du monde entier rencontrent des difficultés. Les voyageurs des aéroports de Hong Kong, d’Inde, de Berlin et d’Amsterdam subissent des retards et annulations. L’administration fédérale de l’aviation des Etats-Unis indique que les compagnies aériennes américaines ont immobilisé tous leurs vols pendant un certain temps, rapporte le New York Times.2) Quel a été l’impact de la panne ?Les logiciels de CrowdStrike, l’une des plus grandes entreprises de cybersécurité au monde, sont très populaires au sein des entreprises du monde entier. On estime ainsi que plus de la moitié des entreprises du classement Fortune 500 utilisent ses produits de sécurité. C’est pourquoi les retombées de la mise à jour défectueuse ont été considérables, certains la qualifiant de « plus grande panne informatique de l’histoire ».Pour illustrer ces propos, plus de 3 000 vols intérieurs, à l’entrée ou en sortie des États-Unis ont été annulés le 19 juillet, et plus de 11 000 ont été retardés. Les avions ont continué à être cloués au sol dans les jours qui ont suivi, avec près de 2 500 vols annulés et plus de 38 000 vols retardés trois jours après la panne.La panne a également eu des répercussions importantes sur le secteur de la santé, certains systèmes de soins et hôpitaux reportant la totalité ou la plupart des actes programmés et les cliniciens étant obligés de revenir au papier et au crayon, faute de pouvoir accéder aux dossiers électroniques.Compte tenu de la nature du correctif et de la popularité du logiciel de CrowdStrike, les organisations informatiques ont travaillé jour et nuit pour restaurer leurs systèmes, mais nombre d’entre elles sont encore embourbées dans cette tâche plusieurs jours après la publication de la mise à jour défectueuse diffusée par CrowdStrike.3) Qu’est-ce que CrowdStrike Falcon ?CrowdStrike Falcon est un logiciel de détection et de réponse aux incidents pour les points d’accès. En jargon, un EDR. Ce type de solutions surveille les appareils des utilisateurs finaux sur un réseau pour détecter les activités et comportements suspects, réagissant automatiquement pour bloquer les menaces et sauvegarder les données des activités jugées à risque, en vue d’une enquête plus approfondie.Comme toutes les plateformes EDR, CrowdStrike dispose d’une visibilité maximale sur tout ce qui se passe sur un terminal – processus, modifications des paramètres du registre, activité sur les fichiers et le réseau – qu’il associe à des capacités d’agrégation et d’analyse des données afin de reconnaître et contrer les menaces via des processus automatisés ou une intervention humaine.Pour cette raison, Falcon est un logiciel doté d’un haut niveau de privilèges avec des accès très étendus aux systèmes qu’il surveille, ce qui le rend étroitement intégré aux systèmes d’exploitation. Un EDR dispose, par ailleurs, de la capacité à mettre fin aux activités qu’il juge malveillantes. Cette intégration étroite s’est avérée être une faiblesse pour les DSI dans le cas présent, rendant les machines Windows inopérantes en raison de la mise à jour défectueuse de Falcon.Crowstrike a également introduit dans Falcon for IT des capacités d’automatisation alimentée par l’IA, afin, selon l’éditeur, de combler le fossé entre les opérations informatiques et les opérations de sécurité.4) Quelle est la cause de la panne de CrowdStrike ?Dans un billet de blog publié le 19 juillet, George Kurtz, Pdg de CrowdStrike, s’est excusé auprès des clients et partenaires de l’entreprise. Séparément, l’entreprise a fourni les premiers détails sur les causes du désastre. Selon cette communication, une mise à jour défectueuse du contenu de sa plateforme Falcon EDR a été envoyée aux machines Windows à 04:09 UTC (Coordinated Universal Time) le vendredi 19 juillet. Une procédure tout ce qu’il y a de plus banal. CrowdStrike envoie généralement plusieurs fois par jour des mises à jour des fichiers de configuration (appelés « Channel Files ») pour les sondes Falcon déployées sur les endpoints.Le défaut qui a déclenché la panne se trouvait dans le Channel File 291, qui est stocké dans « C:NWindowsNSystem32NdriversNCrowdStrikeN » avec un nom de fichier commençant par « C-00000291- » et se terminant par « .sys ». Ce fichier transmet au capteur Falcon des informations sur la manière d’évaluer l’exécution de « tubes nommés », que les systèmes Windows utilisent pour la communication intersystème ou interprocessus. Ces commandes ne sont pas intrinsèquement malveillantes même si elles peuvent être utilisées à mauvais escient.Et, précisément, « la mise à jour qui a eu lieu à 04:09 UTC a été conçue pour cibler les « tubes nommés » associés à des activités malveillantes récemment observées et utilisés par des structures C2 [soit l’infrastructure de commande et contrôle des assaillants] courantes dans les cyberattaques », explique le document technique de l’éditeur. Sauf que, précise CrowdStrike, « la mise à jour de la configuration a déclenché une erreur logique qui a entraîné un plantage du système d’exploitation ».Lors du redémarrage automatique, les systèmes Windows sur lesquels le fichier Channel 291 défectueux était installé se bloquaient à nouveau, provoquant un cycle de redémarrage sans fin. Signalons que la mise à jour défectueuse n’a affecté que les systèmes fonctionnant sous Windows, les machines Linux et MacOS étant épargnées, selon l’éditeur.5) Comment CrowdStrike a-t-il réagi ?Selon la communication officielle, CrowdStrike a diffusé très rapidement un correctif supprimant le contenu défectueux du fichier Channel 291. 79 minutes seulement après l’envoi de la mise à jour défectueuse. Les machines qui n’avaient pas encore été mises à jour avec le Channel File 291 n’ont pas été affectées par l’erreur de l’éditeur. Mais les machines qui avaient déjà téléchargé le contenu défectueux n’ont pas eu cette chance.Pour remédier à la situation de ces systèmes bloqués dans un cycle de redémarrage sans fin, CrowdStrike a publié un autre billet de blog contenant une série d’actions à effectuer. On y trouve des suggestions pour la détection à distance et la récupération automatique des systèmes affectés, ainsi que des instructions détaillées pour mettre en place des solutions de contournement temporaires pour les machines physiques ou les serveurs virtuels touchés. Y compris des redémarrages manuels.6) Comment s’est déroulée la reprise après la panne ?Pour de nombreuses organisations, la reprise reste une problématique ouverte. L’une des solutions proposées pour remédier aux effets de la mise à jour consiste à redémarrer manuellement chaque machine en mode sans échec, à supprimer le fichier défectueux et à redémarrer l’ordinateur. PC par PC et serveur par serveur !Notons que certaines organisations, qui avaient mis en place des plans de renouvellement de leur matériel, envisagent de les accélérer afin de remplacer les machines touchées plutôt que d’engager les ressources nécessaires pour effectuer la réparation à la main de leur flotte.7) Quelles sont les retombées de cet échec pour CrowdStrike ?Outre la réparation de leurs machines Windows, les responsables informatiques et leurs équipes évaluent les leçons à tirer de cette panne de grande ampleur, beaucoup cherchant à éviter les points de défaillance uniques et à réévaluer leurs stratégies en matière de cloud.Quant à CrowdStrike, le Congrès américain a demandé à son Pdg de témoigner lors d’une audition portant sur cette panne technologique. Selon le New York Times, Mark Green (un Républicain élu à la chambre des représentants), président de la commission de la sécurité intérieure, et le représentant Andrew Garbarino (un autre élu républicain) ont envoyé une lettre à George Kurtz. Les Américains « méritent de savoir en détail comment cet incident s’est produit et quelles mesures d’atténuation CrowdStrike a prises », ont-ils écrit, selon le New York Times.
Déjà corrigée en 2019, une vulnérabilité débouchant sur un contournement des plugins d’authentification dans Docker Engine fait de nouveau parler d’elle. Cette régression de faille affecte les versions Docker Engine v19.03 et ultérieures qui s’appuient dessus.
La plateforme de conteneurisation open source Docker a exhorté les utilisateurs à corriger une vulnérabilité critique affectant certaines versions de Docker Engine qui permet une escalade des privilèges à l’aide de requêtes API spécialement élaborées. Répertoriée en tant que CVE-2024-41110, celle-ci a été découverte pour la première fois en 2018 et s’est vu attribuer un score CVSS de 10/10. Bien que la faille ait été corrigée par Docker peu de temps après, les versions ultérieures n’ont cependant pas reçu le correctif, selon un avis de sécurité du fournisseur. « En 2018, un problème de sécurité a été découvert où un attaquant pouvait contourner les plugins d’autorisation (AuthZ) », a indiqué Gabriela Georgia de Docker dans un billet de blog. « Bien que ce problème ait été corrigé dans Docker Engine v18.09.1 en janvier 2019, le correctif n’a pas été reporté sur les versions ultérieures, ce qui a entraîné une régression. » Toute personne dépendant des plugins AuthZ pour traiter les demandes d’accès et les réponses est potentiellement impactée, a ajouté Docker dans son bulletin de sécurité.
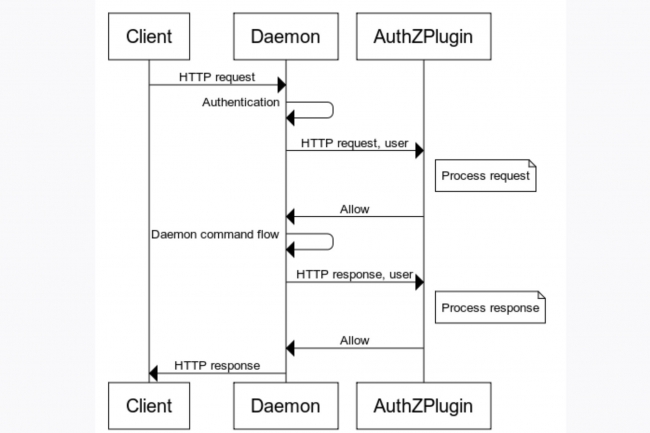
Selon le modèle d’autorisation par défaut de Docker, les utilisateurs ayant accès au daemon Docker peuvent exécuter n’importe quelle commande, a expliqué Gabriela Georgia. AuthZ peut ainsi être utilisé pour exercer un contrôle d’accès granulaire basé sur l’authentification et le contexte de la commande. Dans certaines circonstances, AuthZ peut être manipulé pour approuver des requêtes non autorisées en utilisant des requêtes API spécialement conçues. « Un attaquant pourrait exploiter un contournement en utilisant une requête API avec Content-Length fixé à 0, ce qui amènerait le daemon Docker à la transmettre au plugin AuthZ, qui pourrait approuver la requête de manière incorrecte », a déclaré Docker dans son bulletin de sécurité. Le plugin AuthZ aurait pu refuser la demande si le corps de la requête lui avait été transmis ce qui n’était pas le cas, a ajouté la société.
Un faible niveau d’exploit selon Docker
La vulnérabilité a été initialement corrigée dans une mise à jour de janvier 2019, dans Docker Engine v18.09.1. Cependant, les déploiements ultérieurs, y compris la v19.03 et les plus récentes, n’ont pas inclus le correctif, ce qui a entraîné une régression. « Cela a été identifié en avril 2024 et des correctifs ont été publiés pour les versions concernées le 23 juillet 2024 », a ajouté la société. « Le problème a été classé CVE-2024-41110. Bien que les systèmes soient restés vulnérables longtemps après l’application du correctif initial, Docker a assuré que l’exploitabilité du bogue restait faible. « La probabilité d’exploitation est faible », a ajouté Gabriela Georgia. Docker a néanmoins conseillé aux utilisateurs d’appliquer les correctifs disponibles dès maintenant, notamment parce que le problème a obtenu un score « faible » dans les évaluations de base CVSS pour la « complexité de l’attaque » et les « privilèges requis ». Les mesures correctives pour les versions affectées comprennent la mise à jour vers la version la plus récente et (si la mise à jour n’est pas possible) éviter l’utilisation des plugins AuthZ et restreindre l’accès à l’API Docker à des parties de confiance uniquement.
A noter que les utilisateurs de Docker Engine v19.03.x et des versions ultérieures qui ne s’appuient pas sur les plugins d’autorisation pour prendre des décisions de contrôle d’accès ainsi que les utilisateurs de toutes les versions de Mirantis Container Runtime ne sont pas touchés par ce trou de sécurité. Ceux des produits commerciaux et de l’infrastructure interne de Docker qui ne s’appuient pas sur les plugins AuthZ également.

Alors que de nombreuses entreprises peinent à remettre en service leurs systèmes Windows après la panne géante, le fournisseur de sécurité Crowdstrike a reconnu des lacunes en matière de testing. Les clients auront davantage de contrôle sur le moment et l’endroit où la mise à jour de Falcon Sensor sera faite.
CrowdStrike lève petit à petit le voile sur les causes de la mise à jour défectueuse du capteur de son agent Falcon (Falcon Sensor). Le fournisseur de cybersécurité a ainsi pointé plusieurs lacunes ayant entraîné depuis vendredi 19 juillet le plantage de millions d’ordinateurs Windows. Ces manquements concernent deux procédures : celle de mise à jour de signature d’exploit (Rapid Response Content) et celle de test d’intégrité de ses fichiers de canaux (Content Validator). Dans son analyse préliminaire de l’incident, Crowdstrike a confirmé que le plantage des ordinateurs de ses clients était dû à une faille dans le fichier Channel 291, qui fait partie d’une mise à jour de la configuration de ses capteurs diffusée sur les systèmes Windows à 04:09 UTC le 19 juillet. Dans son rapport, le fournisseur a fourni une première explication sur la manière dont cette faille a été déployée et a indiqué les changements qu’elle apporte à ses processus pour éviter que cela ne se reproduise. Crowdstrike n’est pas la seule entreprise à envisager des changements à la suite de l’incident : de nombreux DSI reconsidèrent également leur dépendance à l’égard des logiciels cloud comme ceux de Crowdstrike.
La revue de Crowdstrike décrit le processus de test rigoureux qu’elle applique aux nouvelles versions de son agent logiciel et aux fichiers de données par défaut qui les accompagnent – ce qu’elle appelle Sensor Content – mais indique que la faille se trouvait dans un type de mise à jour de signature d’exploit qu’elle appelle Rapid Response Content, qui fait l’objet de vérifications moins rigoureuses. Les clients ont la possibilité d’utiliser la dernière version de Sensor Content ou l’une des deux versions précédentes s’ils préfèrent privilégier la fiabilité plutôt que la couverture des attaques les plus récentes. Le contenu de réponse rapide est toutefois déployé automatiquement sur les versions de capteurs compatibles. Le contenu de réponse rapide est stocké dans un fichier binaire propriétaire qui contient des données de configuration plutôt que du code. Les fichiers sont livrés sous forme de mises à jour de la configuration du capteur Falcon, ce qui permet à la plateforme de mieux détecter les caractéristiques d’une activité malveillante en se basant sur la reconnaissance des comportements. Crowdstrike utilise son système de configuration du contenu pour créer des instances de modèles décrivant le comportement à détecter, en les stockant dans des fichiers de canaux qu’il teste ensuite à l’aide d’un outil appelé Content Validator.
Un compte à rebours vers la catastrophe
Falcon Sensor 7.11 a été mis à la disposition des clients le 28 février, introduisant un nouveau type de modèle pour détecter les nouvelles techniques d’attaque sur les communications interprocessus (IPC) qui abusent de ce que l’on appelle les Named Pipes. Le premier Channel File 291 a été mis en production le 5 mars après un test de résistance réussi. Les instances du modèle qui s’appuient sur le fichier de canal 291 ont été diffusées sans problème le 5 mars, le 8 avril et le 24 avril. Une catastrophe s’est produite lorsque deux autres instances de modèles ont été déployées le 19 juillet. « En raison d’un bogue dans Content Validator, l’une des deux instances de modèle a passé la validation bien qu’elle contienne des données de contenu problématiques », a déclaré Crowdstrike dans son rapport.
Ce qui semblait être une mise à jour mineure de la configuration d’un composant qui avait été testé et était déjà en production a en fait déclenché une vague de pannes. Néanmoins, le fournisseur a affirmé avoir agi de manière responsable avant ce qui s’est avéré être un désastre. « Sur la base des tests effectués avant le déploiement initial du type de modèle (le 5 mars 2024), de la confiance dans les vérifications effectuées par Content Validator et des précédents déploiements réussis de l’instance de modèle IPC, ces instances ont été déployées en production », a expliqué Crowdstrike. « Lorsqu’il a été reçu par le capteur et chargé dans l’interpréteur de contenu, le contenu problématique du fichier de canal 291 a entraîné une lecture de la mémoire hors limites, ce qui a déclenché une exception. Cette exception inattendue n’a pas pu être gérée de manière élégante, ce qui a entraîné un plantage du système d’exploitation Windows (BSOD) », a ajouté l’organisation.
Une amélioration des tests à venir
Dorénavant, les mises à jour de Crowdstrike seront testées localement avant d’être envoyées aux clients. Des tests de mise à jour du contenu et de retour en arrière seront effectués, ainsi que des tests supplémentaires de stabilité et d’interface du contenu. Les procédures existantes de traitement des erreurs dans l’interprète de contenu seront améliorées de sorte que, par exemple, les bogues ne fassent que planter le programme au lieu de déclencher une panne du système d’exploitation. Crowdstrike introduira également une stratégie de déploiement échelonné pour le contenu de réponse rapide à l’origine de l’incident du 19 juillet. Dans un premier temps, le nouveau contenu fera l’objet d’un « déploiement canari » afin de détecter les problèmes critiques, avant d’être diffusé auprès d’une part de plus en plus importante de sa base de clients. Elle permettra également aux clients de refuser les toutes dernières versions du contenu, en offrant « une sélection granulaire du moment et du lieu où ces mises à jour sont déployées ».
Les premières réactions à l’analyse de Crowdstrike et au plan de remédiation des experts en sécurité, tels que Kevin Beaumont, ont été positives. La réponse de Crowdstrike a été très bonne après l’erreur », a déclaré M. Beaumont dans un fil de discussion sur Twitter/X. “Ils réalisent clairement qu’ils doivent désormais donner la priorité à la sécurité”. « Ils ont clairement compris qu’ils devaient désormais donner la priorité à la sécurité.

Pour améliorer la résilience des SI, les DSI cherchent à éviter les points de défaillance uniques. A ce titre, la panne Crowdstrike pointe les limites des stratégies cloud les rendant trop dépendants à un fournisseur donné.
Les perturbations engendrées par la mise à jour défectueuse de CrowdStrike, qui a entraîné une panne mondiale des systèmes Windows, a provoqué une onde de choc dans la communauté IT. Pour les responsables informatiques, cet événement rappelle brutalement les risques inhérents à une dépendance excessive à un seul fournisseur, en particulier dans le domaine du cloud.L’incident qui a vu les systèmes Windows s’effondrer et afficher le fameux « écran bleu de la mort » (BSOD pour Blue screen of death), a mis en évidence les vulnérabilités des infrastructures fortement dépendantes au cloud. Bien que le problème soit en cours de résolution, il souligne les conséquences catastrophiques potentielles d’une défaillance d’un composant de sécurité essentiel. Cette situation doit pousser les DSI à s’interroger sur la résilience de leurs environnements cloud et à explorer d’autres stratégies.Réévaluer ses dépendances au cloud« Lorsqu’un problème d’une telle ampleur survient et provoque des perturbations aussi importantes, il est important et nécessaire de réévaluer les convictions, les décisions et les compromis qui ont permis d’aboutir à l’architecture actuelle », estime Abhishek Gupta, DSI de DishTV, l’un des plus grands fournisseurs de télévision par câble d’Inde. « Cette analyse peut déboucher sur un statu quo, mais ce réexamen est nécessaire », reprend le DSI, ajoutant que DishTV est déjà en train de réévaluer sa stratégie cloud de manière progressive après l’incident Crowdstrike.Shashank Jain, DSI de la société de services financiers Shree Financials, suggère, lui, un changement de stratégie : « les organisations et les RSSI doivent revoir leurs stratégies en matière de cloud, et la mise à jour automatique des correctifs doit être découragée. Tous les correctifs devraient d’abord être testés sur un environnement de test ». Et de souligner que malgré la réputation de CrowdStrike, l’incident soulève un problème de confiance. A cause de correctifs non testés qui ont eu un effet en cascade.Saurabh Gugnani, directeur et responsable de la cyberdéfense, de l’IAM et de la sécurité des applications au sein du groupe TMF, basé aux Pays-Bas, ajoute qu’une approche équilibrée des stratégies cloud constitue une voie pour atténuer ces risques. « Oui, elles [les entreprises] devraient revoir leurs stratégies cloud. Il faut davantage mixer toutes les solutions disponibles. »Réviser les plans de continuitéQuelques organisations ont déjà commencé à sauter le pas. « En réponse aux récentes perturbations qui ont affecté nos opérations critiques, nous avons proactivement mis à jour notre plan de continuité des activités pour faire face aux temps d’arrêt inattendus et minimiser leur impact sur la productivité et nos prestations de services », indique par exemple Shivkumar Borade, fondateur et directeur général de Mytek Innovations, une société de services IT indienne victime de l’effet BSOD. « Notre plan révisé comprend une gestion améliorée de la communication, avec plusieurs niveaux pour s’assurer que tous les employés sont bien informés des problèmes potentiels et de leur résolution ».Lors de la panne Crowdstrike, la communication interne de l’entreprise a été considérablement perturbée, l’ensemble de son réseau, y compris Outlook, Teams et SharePoint, étant hébergé sur Microsoft 365. « Cependant, notre application développée en interne n’a pas été affectée, car GoDaddy utilise sa propre infrastructure d’hébergement, souligne le dirigeant. Nous avons rencontré des problèmes avec quelques intégrations par API liées à la plateforme Azure, qui n’ont pas fonctionné pendant toute la journée. Ces perturbations ont entraîné une interruption des services pour nos clients et nos utilisateurs. »La confiance dans les outils de sécurité mise en causeL’une des principales préoccupations des DSI réside dans le lock-in, une dépendance à un fournisseur bloquant tout contournement aisé de ses services. La dépendance à l’égard d’un seul fournisseur de cloud, comme l’a montré l’incident CrowdStrike, crée un point de défaillance unique. Si un service critique de ce fournisseur est interrompu, cela peut avoir des conséquences considérables pour une organisation. Pour atténuer ce risque, les DSI peuvent miser sur des architectures multicloud ou hybrides, se traduisant par une répartition des applications sur plusieurs plates-formes.Allie Mellen, analyste chez Forrester, souligne l’importance d’outils et de services fiables pour faire face aux cybermenaces. « La fiabilité des outils et des services utilisés par les équipes de cybersécurité est essentielle face aux cyberattaques, dit-elle. Un incident comme celui-ci remet en question cette fiabilité. Cela va sans aucun doute susciter des interrogations et des inquiétudes de la part des dirigeants sur la manière de garantir la fiabilité de leurs systèmes, en particulier avec une technologie aussi intégrée dans les opérations quotidiennes que les logiciels de cybersécurité ».L’incident a mis en évidence la fragilité des systèmes dépendant du cloud, où un point de défaillance unique peut avoir des effets en cascade sur l’ensemble d’une organisation. Pour Sunil Varkey, professionnel de la sécurité et conseiller principal chez Beagle Security, « la confiance entre les fournisseurs de services cloud et les éditeurs de solutions de sécurité est désormais remise en question. Cette rupture de confiance devrait conduire à mettre davantage l’accent sur les solutions sans agent, qui peuvent offrir une sécurité accrue sans les vulnérabilités associées aux agents traditionnels. »8,5 millions de PC sous Windows touchésCar la panne provoquée par CrowdStrike constitue l’un des pires événements en matière de cybersécurité, compte tenu de l’ampleur de son impact. L’incident a touché des ordinateurs fonctionnant sous Windows dans divers secteurs, notamment les compagnies aériennes, les banques, les distributeurs, les maisons de courtage, les médias et les chemins de fer. Le secteur du voyage a été particulièrement touché, les compagnies aériennes et les aéroports d’Allemagne, de France, des Pays-Bas, du Royaume-Uni, des États-Unis, d’Australie, de Chine, du Japon, d’Inde, de Singapour et de Taïwan ayant rencontré d’importants problèmes avec les systèmes d’enregistrement et de billetterie, provoquant des retards de vols et le chaos dans certains aéroports. Microsoft a reconnu qu’environ 8,5 millions d’ordinateurs sous Windows avaient été touchés. L’impact a été tel que le Pdg de SpaceX et Tesla, Elon Musk, a décidé de supprimer CrowdStrike de tous les systèmes des entreprises qu’il dirige.Amélioration des pratiques de gestion des risquesL’incident a également mis en évidence la nécessité d’améliorer les pratiques de gestion des risques. Une plus grande diligence dans la reprise, le test rigoureux des mises à jour et leurs déploiements progressifs apparaissent désormais comme des pratiques indispensables. « Cet incident a servi de signal d’alarme, soulignant la nécessité d’une adaptation et d’une amélioration continue des pratiques de cybersécurité dans l’ensemble du secteur », reconnaît Gaurav Ranade, directeur de la technologie chez l’éditeur de logiciels RAH Infotech.D.R. Goyal, architecte chez Rakuten Symphony, une société du groupe Rakuten fournissant des services pour le marché des télécoms, plaide ainsi un mécanisme permettant de tester les mises à jour auprès d’utilisateurs sélectionnés avant leur diffusion complète : « Il devrait y avoir un mécanisme permettant de tester les mises à jour auprès de certaines organisations et d’un ensemble d’utilisateurs restreint avant de les diffuser à l’ensemble de la communauté et de la base d’utilisateurs, afin de réduire l’impact d’un incident potentiel. »À mesure que le paysage numérique évolue, garantir la résilience des systèmes basés sur le cloud devient incontournable. « L’incident a des implications très importantes sur l’économie mondiale ; des temps d’arrêt et de rétablissement plus longs auront un impact sur la productivité et l’économie », note Ashis Guha, fondateur de la société de conseils An Idea Global InnovationsTests approfondis des mises à jour et déploiements progressifsLes experts du secteur recommandent plusieurs stratégies pour préparer de futurs incidents, notamment des déploiements progressifs, des tests complets et des systèmes de sauvegarde robustes. Siddharth Ugrankar, cofondateur de la société de blockchain Qila, estime qu’un déploiement progressif et des tests approfondis des mises à jour auraient pu atténuer l’impact : « Si CrowdStrike avait déployé la mise à jour de manière progressive, l’impact aurait été bien moindre », juge-t-il.Les entreprises qui souhaitent éviter des problèmes similaires à l’incident CrowdStrike doivent renforcer leur gestion des mises à jour, en améliorant les protocoles de test dans divers environnements, en mettant en oeuvre des évaluations rigoureuses des risques et en renforçant les processus de gestion des changements avec une gouvernance solide associée, résume Moyukh Goswami, CTO de Nuvepro, société spécialisée dans la formation. « Il est essentiel de renforcer ses capacités de monitoring, d’affiner les plans de réponse aux incidents, en les adaptant aux défaillances consécutives aux mises à jour, et de favoriser des relations proactives avec les fournisseurs », ajoute le CTO.L’incident CrowdStrike souligne la nécessité pour les DSI de revoir et de renforcer leurs stratégies en matière de cloud computing. En mettant en oeuvre de solides pratiques de gestion des risques, en renforçant les mesures de sécurité et en diversifiant les solutions de cloud, les entreprises peuvent mieux se protéger contre de futures perturbations. Alors que l’industrie est toujours aux prises avec les implications de la panne Crowdstrike, l’accent doit être mis sur l’élaboration de stratégies de cloud résilientes, adaptables et testées en profondeur, afin de naviguer dans un paysage numérique toujours plus complexe.

Alors que la planète se remet doucement de la panne massive provoquée par la mise à jour défectueuse de Falcon Sensor de Crowdstrike, DSI et RSSI seraient bien avisés de dresser la liste des enseignements à tirer de cette expérience. Voici quelques considérations initiales à prendre en compte.
Que vous ayez survécu à la panne géante Crowdstrike ou que vous n’utilisiez pas cette solution et que vous ne fassiez que constater l’impact sur les autres, il est vital de prendre le temps de tirer les leçons de cet événement. Après tout, si vous n’avez pas pu vous en remettre facilement, vous risquez bien d’être perdu quand vous ferez face à une attaque par ransomware. Les enseignements à tirer amènent à des changements potentiels que vous pourriez envisager d’apporter à vos stratégies de…
Il vous reste 95% de l’article à lireVous devez posséder un compte pour poursuivre la lecture
Vous avez déjà un compte?

La start-up américano-israélienne spécialisée dans la gestion de la posture de sécurité cloud Wiz n’a pas donné suite à la proposition de rachat à 23 milliards de dollars de Google. La société vise une intrduction en bourse sans donner pour l’heure d’échéance.
Wiz ne tombera pas dans l’escarcelle de Google. La start-up américano-israélienne en cybersécurité a en effet décidé de mettre fin à ses négociations avecAlphabet, la maison-mère du géant de la recherche, qui auraient pu aboutir à un rachat de 23 Md$. Soit le plus important jamais réalisé pour le groupe. « Bien que nous soyons flattés par les offres que nous avons reçues, nous avons choisi de continuer à construire Wiz […] Il est difficile de dire non à des offres aussi honorables, mais grâce à notre équipe exceptionnelle, je peux faire ce choix en toute confiance », a expliqué le CEO de Wiz Assaf Rappaport, sans nommer spécifiquement Google ou Alphabet, dans un memo interne restranscrit par Techrunch. « Notre objectif est d’atteindre un chiffre d’affaires annuel récurrent d’un milliard de dollars, et nous pensons que nous pouvons atteindre cette étape de manière indépendante ».
Bien que les rumeurs d’acquisition fassent le tour de la toile depuis plus d’une semaine, ni Google ni Alphabet n’ont fait de commentaires à ce sujet. « Je pense qu’il s’agit d’une excellente validation du marché pour Wiz, et bien que l’offre soit presque deux fois supérieure à son évaluation, elle est tout à fait intéressante pour les investisseurs », a déclaré Neil Shah, vice-président chargé de la recherche et partenaire de Counterpart Research. Des rapports antérieurs indiquaient qu’Alphabet était en discussions avancées pour acquérir Wiz pour environ 23 Md$, ce qui représente une augmentation significative par rapport à l’évaluation de 12 Md$ que la start-up a reçue en mai à la suite d’une levée de fonds de 1 Md$. Cette acquisition aurait considérablement renforcé la division cloud computing de Google, un secteur où l’entreprise est actuellement à la traîne par rapport à des concurrents tels qu’Amazon Web Services et Microsoft Azure.
Des rachats récurrents en cybersécurité pour Google
Wiz propose des solutions de cybersécurité en gestion de la posture de sécurité cloud (CSPM) s’appuyant sur l’IA pour détecter les menaces et y remédier sur toutes les applications et services. Elle collabore avec plusieurs fournisseurs de cloud, dont Microsoft et Amazon, et compte parmi ses clients BMW, DocuSign, Morgan Stanley, Shell… L’entreprise compte 900 employés répartis entre les États-Unis, l’Europe, l’Asie et Israël. La décision de la jeune pousse d’entrer en bourse plutôt que de vendre à Google est considérée comme une décision stratégique visant à conserver son indépendance tout en développant ses activités et son chiffre d’affaires. Le mémo d’Assaf Rappaport témoigne d’une grande confiance dans le potentiel de Wiz. « Nous sommes déterminés à poursuivre notre trajectoire de croissance et à offrir une valeur exceptionnelle à nos clients grâce à l’innovation et au dévouement », a déclaré Reuters en citant le CEO de Wiz.
L’échec de cette opération marque un nouveau revers pour Alphabet dans ses récentes tentatives d’expansion. Tout récemment, Alphabet a renoncé à acquérir la société de logiciels de marketing en ligne HubSpot. Si l’opération Wiz s’était concrétisée, elle aurait constitué la deuxième acquisition majeure d’Alphabet dans le secteur de la cybersécurité après Mandiant pour 5,4 Md$ en 2022. « La trajectoire de croissance actuelle de Wiz et son potentiel de croissance sur le marché de la sécurité cloud (6 Md$ par an) et sur le marché global de la cybersécurité (200 Md$ par an) au cours des cinq prochaines années font qu’il est difficile de laisser de l’argent sur la table », a ajouté Neil Shah. Les récents rachats de Google en cybersécurité comprennent également Siemplify ou encore Chronicle Detect.
Des objectifs élevés de croissance
Malgré les défis, les dirigeants de Wiz restent optimistes quant à l’avenir. Assaf Rappaport a souligné que l’entreprise se concentrait à nouveau sur la poursuite d’une introduction en bourse et sur la réalisation d’objectifs de croissance substantiels. L’entreprise prévoit de tirer parti de ses technologies de cybersécurité robustes et de sa présence significative sur le marché pour stimuler sa croissance. « Notre voie reste claire, nous continuerons à innover et à être leader dans le domaine de la cybersécurité », poursuit Reuters en citant Assaf Rappaport. Les demandes de commentaires de Google et de Wiz sont pour l’heure restées sans réponse.
La panne de CrowdStrike a fait la une des journaux internationaux vendredi en perturbant le monde. Après plusieurs jours de travail acharné Microsoft lance un outil pour remettre en marche les PC concernés.
A moins d’habiter sur une autre planète vous avez dû largement entendre parler de la panne géante provoquée par une mise à jour défectueuse de CrowdStrike. Si vous avez eu la chance de ne pas souffrir personnellement de cet incident de grande ampleur, vous connaissez certainement une entreprise ou une organisation qui a été touchée. La bonne nouvelle ? Microsoft a publié un outil de récupération pour aider les informaticiens à contourner le blocage résultant de la mise à jour Falcon Sensor de CrowdStrike, ce qui devrait permettre de réduire les délais de récupération.
Le bug de CrowdStrike a été corrigé peu de temps après son apparition, mais les ordinateurs affectés doivent être restaurés manuellement. Avec plus de 8,5 millions d’ordinateurs Windows concernés, la remise en route est pour le moins fastidieuse. Microsoft contourne ce problème en proposant un outil téléchargeable qui peut être installé sur une clé USB amorçable (et toute la démarche qui va avec), le même type d’outil que celui que vous avez probablement utilisé pour installer une nouvelle copie de Windows. Les responsables informatiques devraient être en mesure de télécharger et d’installer l’outil à partir de n’importe quelle machine Windows encore en état de marche.
800 vols Delta Airlines annulés lundi à cause de la panne
The Verge rapporte que cet outil de récupération devrait être en mesure de corriger Windows pour qu’il puisse démarrer sans avoir à redémarrer l’ordinateur quinze fois (c’était une solution proposée à un moment donné). Les retombées immédiates du désastre de CrowdStrike semblent être contenues même si par exemple Delta Airlines a fait encore état ce lundi de plus de 800 vols annulés avec des centaines de personnes obligées de dormir dans des halls d’aéroport. Quoi qu’il en soit la réputation de l’entreprise en pâtira certainement dans un avenir proche. Le cours des actions cotées en bourse de CrowdStrike est passé de plus de 350 $ la semaine dernière à 267 $ lundi, faisant fondre la valorisation du groupe de plusieurs dizaines de milliards de dollars en quelques jours.
Et cela ne fait pas non plus les affaires de Microsoft. Car il est difficile de ne pas associer le problème CrowdStrike à Windows lorsqu’il a entraîné le retour du tristement célèbre écran bleu de la mort.

Lors de la catastrophe informatique provoquée par CrowdStrike ce week-end, c’est une version obsolète de Windows qui a permis d’éviter des dégâts encore plus importants.
Vendredi dernier, une panne informatique mondiale a paralysé des millions de terminaux Windows dans le monde entier. Cette catastrophe a été qualifiée de plus grande catastrophe informatique de tous les temps. En raison d’une mise à jour défectueuse poussée par le fournisseur de cybersécurité CrowdStrike, de nombreux systèmes Windows sont tombés en panne et n’ont pas pu redémarrer en raison d’une boucle infinie d’écrans bleus, de redémarrages et d’autres écrans bleus. Le problème a depuis été en grande partie résolu, mais l’impact se fait toujours sentir puisque l’incident CrowdStrike Falcon a provoqué des pannes dans le contrôle du trafic aérien, les hôpitaux, les services d’urgence, la répartition du fret, etc. Cependant, certaines entreprises n’auraient pas été affectées pour une raison curieuse : elles n’utilisaient pas de logiciels modernes, mais faisaient fonctionner leurs ordinateurs sous Windows 95 ou même sur des systèmes plus anciens.
Préservé grâce à un système d’exploitation vieux de 32 ans
Bien que presque tous les vols aux États-Unis aient dû être annulés en raison de l’incident de CrowdStrike, au moins une compagnie aérienne a pu éviter la panne : Southwest Airlines n’a signalé aucun problème avec ses opérations. Selon certaines informations , une grande partie des systèmes de Southwest Airlines sont basés sur Windows 95 et Windows 3.1. Ce dernier a plus de 32 ans et est donc plus que dépassé. Windows 95 n’est plus d’actualité non plus, mais la compagnie aérienne ne semble pas s’en soucier.
Entre-temps, un tweet présumé de Southwest Airlines a fait le tour du monde , disant : « Eh bien, eh bien, eh bien. Regardez qui a besoin de la vieille Southwest Airlines maintenant, car tous nos systèmes fonctionnent sur un seul Commodore 64 dans un entrepôt d’Arlington. Allez au diable. »
Cependant, il est désormais avéré que ce tweet était un faux. Néanmoins, le message est devenu viral.
La Russie épargnée
Les compagnies aériennes américaines ne sont pas les seules à ne pas vouloir s’adapter aux nouvelles technologies. Il est également probable que les pannes de système aient été rares en Russie, car le pays n’a reçu aucun produit américain depuis le début de la guerre en Ukraine. La mise à jour CrowdStrike n’a pas non plus été installée sur leurs systèmes, comme l’a notamment rapporté Business Insider. En règle générale, les versions de logiciels et les systèmes informatiques obsolètes sont considérés comme particulièrement vulnérables aux pannes de systèmes et aux attaques de piratage. Dans ce cas précis, les entreprises qui s’appuient sur des logiciels obsolètes ont eu une chance exceptionnelle. L’incident CrowdStrike montre avant tout à quel point les systèmes mondiaux sont interconnectés et fragiles. Une seule vulnérabilité ou erreur suffit à affecter des millions de personnes dans le monde.