





GenaAI : Anthropic renforce la sécurité des modèles d’IA
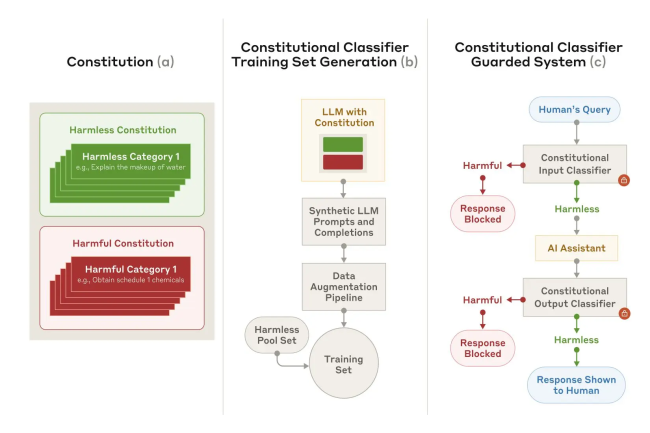
Les modèles d’IA sont de plus en plus la cible de techniques pour leur faire dire de mauvaises réponses. Pour répondre à ce problème, Anthropic lance un framework capable de filtrer les contournements des garde-fous.
La mise en place de garde-fous dans les modèles d’IA n’est pas la réponse parfaite pour éviter de générer du mauvais contenu. Anthropic vient de s’attaquer à ce problème face à la multiplication des techniques pour contourner ces barrières. Ces méthodes aussi appelées jailbreak, « exploitent le LLM en l’inondant d’invites excessivement longues, tandis que d’autres manipulent le style d’entrée, par exemple en utilisant des majuscules inhabituelles », souligne la…
Il vous reste 90% de l’article à lire
Vous devez posséder un compte pour poursuivre la lecture
Vous avez déjà un compte?