





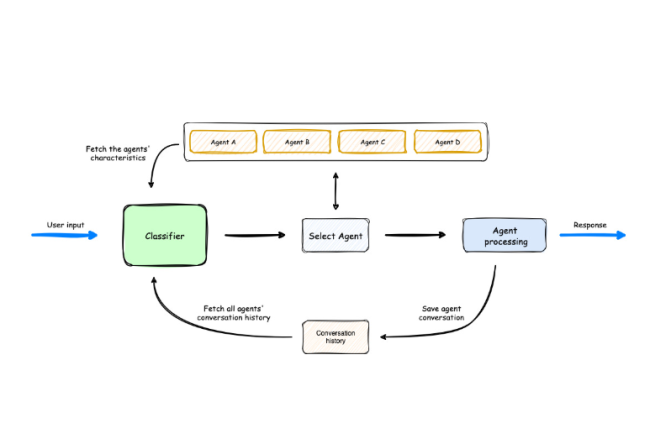
Le laboratoire d’AWS a présenté le projet open source Multi-Agent Orchestrator pour administrer la prolifération des agents IA.
Un récent rapport de SNS Insider a évalué le marché mondial des agents IA à 3,7 Md$ en 2023 et devraient atteindre les 103,6 Md$ d’ici 2032 avec un taux de croissance annuel de 44,9% pendant cette période. Cette progression indique un changement fondamental dans la façon dont l’informatique distribuée et l’automatisation vont être abordées. La récente publication du framework Multi-Agent Orchestrator d’AWS Lab sur GitHub représente une étape importante dans cette…
Il vous reste 93% de l’article à lireVous devez posséder un compte pour poursuivre la lecture
Vous avez déjà un compte?

L’ingénierie du chaos fait de plus en plus d’émules. Mais cette méthode de stress test des infrastructures IT comporte des avantages et des inconvénients à soupeser avant son adoption.
Après avoir eu son heure de gloire au sein de Netflix (et l’outil Chaos Monkey), l’ingénierie du chaos séduit de plus en plus d’entreprise (Mano Mano, SNCF…). Pour autant, casser volontairement un système d’information pour voir comment il réagit et l’améliorer n’est pas une décision à prendre à la légère.
Les sociétés doivent examiner attentivement les ressources exigées, les risques introduits et l’alignement de la démarche sur des objectifs stratégiques plus larges. Il est essentiel de comprendre ces facteurs pour décider si cette approche doit être un élément central ou un outil complémentaire dans la stratégie IT d’une entreprise. Chaque organisation doit déterminer dans quelle mesure elle suivra cette évolution technologique et le temps qu’elle peut attendre pour que son fournisseur IT lui propose des solutions.
Des erreurs de plus en plus fréquentes et coûteuses
Les récentes actualités montrent que les erreurs humaines (mauvaises configuration, problème de code…), les attaques de type DDoS et les pannes peuvent avoir un impact important sur la résilience des infrastructures IT. Ainsi sur les campagnes par déni de service, Cloudflare a enregistré 4 millions d’attaques au deuxième trimestre 2024, en forte progression par rapport au trimestre précédent. Les fournisseurs de cloud ne sont pas épargnés non plus par les défaillances de serveurs ou les cyberattaques. L’actualité la plus emblématique de cet été a eu lieu le 19 juillet avec la panne des services Microsoft Azure. Elle était liée à une mise à jour défectueuse du capteur Falcon de Crowdstrike. Plusieurs firmes ont été touchées avec de lourdes conséquences financières. La compagnie Delta Airlines évoque un manque à gagner de 500 M$.
Cet incident a été un signal d’alarme pour plusieurs raisons. En premier, la plupart des entreprises ont commencé à se rendre compte de leur vulnérabilité. La production pouvait s’arrêter à cause d’une erreur stupide. Deuxièmement, le coût total de cet événement a été beaucoup plus élevé que ce à quoi s’attendaient la plupart des entreprises. Il a également eu un impact plus important que prévu sur des questions non techniques comme les relations publiques et avec les clients. Enfin, l’enseignement que l’on en a tiré, c’est que le plus grand risque vient des personnes et non de la technologie. Se préparer à ces erreurs, donc de se tourner vers l’ingénierie du chaos, est donc devenu une réflexion dans nombre d’organisations, en mettant dans la balance les bénéfices et les contraintes.
Avantages de l’ingénierie du chaos
Supposons qu’une grande société du e-commerce mette en œuvre l’ingénierie du chaos pour tester la résilience de son système cloud pendant les périodes de pointe des achats. Elle utilise un outil dédié pour simuler des charges de trafic accrues qui imitent les conditions du Black Friday. L’équipe introduit délibérément des temps de latence et des arrêts de serveur aléatoires pour observer comment le système réagit au stress. Au cours de ces tests, ils découvrent des goulets d’étranglement dans l’architecture de leur base de données que les tests traditionnels auraient dû déceler. Grâce à des mesures en temps réel, ils mettent rapidement en œuvre des stratégies adaptatives comme la mise à l’échelle automatique des ressources du serveur et l’optimisation des requêtes de la base de données.
En répétant continuellement ces expériences de chaos, la plateforme de commerce électronique résiste non seulement aux pressions simulées, mais améliore sa capacité à s’adapter automatiquement aux pics inattendus. Cela garantit, ou devrait garantir, une expérience client transparente pendant les périodes de vente critiques. Cette approche proactive transforme un chaos potentiel en une opportunité de renforcer la résilience de l’infrastructure. C’est du moins l’idée.
Inconvénients de l’ingénierie du chaos
Malgré ses avantages, l’ingénierie du chaos pose des défis et des questions importants aux entreprises. En premier lieu, il y a l’intensité des ressources mobilisées. En effet, la mise en œuvre de cette méthode nécessite des investissements substantiels dans les bons outils, du personnel qualifié et du temps pour simuler et analyser efficacement les scénarios. Cela peut grever les budgets et détourner l’attention des principaux objectifs de l’entreprise. Autre point de friction, les possibles impacts opérationnels car l’introduction intentionnelle d’erreurs comporte des risques inhérents. Les sociétés doivent être prudentes, car ces pratiques peuvent perturber les services, affecter les performances et créer des effets secondaires indésirables susceptibles d’entraîner le mécontentement des clients ou des pertes financières.
Par ailleurs, l’ingénierie du chaos peut détourner l’attention d’initiatives plus stratégiques. Les entreprises donnent souvent la priorité à des projets simples, basés sur le retour sur investissement, qui contribuent directement à la croissance. S’engager à fond dans la méthode pourrait les détourner de la poursuite d’innovations ou d’améliorations opérationnelles qui présentent des avantages immédiats. Il faut aussi prendre en considération la gestion de la complexité. L’ingénierie du chaos exige une compréhension approfondie des interdépendances au sein des systèmes. Un défi qui pourrait dissuader les entreprises d’appliquer efficacement les principes de cette démarche.
Une choix réfléchi et équilibré
L’ingénierie du chaos offre un mécanisme de défense proactif contre les faiblesses des systèmes, mais les sociétés doivent en évaluer les risques par rapport à leurs objectifs stratégiques. Investir massivement dans l’ingénierie du chaos peut être justifié pour certains, en particulier dans les secteurs où la disponibilité et la fiabilité sont cruciaux. D’autres, en revanche, feraient mieux de se concentrer sur l’amélioration des normes de cybersécurité, la mise à jour de l’infrastructure et le recrutement de talents.
Par ailleurs, il y a lieu de se demander ce que comptent offrir les fournisseurs de services cloud en la matière ? Beaucoup d’entreprises se lancent sur les clouds publics parce qu’elles veulent transférer une partie de la charge aux fournisseurs, y compris l’ingénierie de la fiabilité. Parfois, le modèle de responsabilité partagée est trop axé sur les souhaits des fournisseurs de cloud plutôt que sur ceux de leurs clients. Il est peut-être temps que certains acteurs cloud passent à la vitesse supérieure. Certains l’ont déjà fait comme AWS. En fin de compte, les entreprises devraient réfléchir à la manière dont l’ingénierie du chaos s’inscrit dans leur stratégie IT plus large. En intégrant des éléments qui correspondent à leurs objectifs plutôt qu’en adoptant la méthode en bloc, les sociétés peuvent bénéficier des idées sans être détournées de leurs missions principales. Comme pour toute innovation, la clé réside dans une application judicieuse.

Le cloud squatting vient s’ajouter à la longue liste des menaces qui planent sur les entreprises, avec à la clé des rsques d’accès par des pirate à des données présentes sur un cloud public. Des solutions existent cependant pour s’en préserver.
La plupart des problèmes de sécurité constatés dans le cloud sont souvent la conséquence d’un acte commis malencontreusement par une personne. Désolé d’être aussi direct, mais les pirates sont rarement ingénieux. Il faut plutôt regarder du côté de la mauvaise configuration des ressources cloud, comme le stockage et les bases de données, qui créent des vulnérabilités faciles à éviter. Pour s’en préserver, la formation constitue la vraie première ligne de défense et non pas les outils de sécurité sophistiqués. Ce point est souvent ignoré, étant donné que les budgets sont consacrés à l’achat de nouveaux outils plutôt qu’à former les administrateurs à éviter les erreurs. C’est très contrariant, si l’on considère l’investissement nécessaire par rapport à la valeur ajoutée.
Même si le cloud squatting est présenté comme une nouvelle menace, cela fait plusieurs années que son existence est connue. Ce qui a changé, c’est que de plus en plus d’actifs sont déplacés dans le cloud public et que de plus en plus de gens doivent s’en occuper, si bien que la vulnérabilité regagne de l’intérêt. Peut-être que les acteurs malveillants parviennent mieux à l’exploiter. Le principal problème, c’est que souvent, les suppressions d’actifs dans le cloud ne donnent pas lieu également à celles des enregistrements associés, ce qui peut créer des risques de sécurité pour les sous-domaines. Or, le fait de ne pas éliminer aussi les enregistrements permet aux attaquants d’exploiter les sous-domaines en créant des sites de phishing ou de logiciels malveillants non autorisés. Voici donc ce que l’on appelle le cloud squatting. En général, les ressources sont provisionnées et désallouées de manière programmatique. L’allocation d’actifs comme les serveurs virtuels et l’espace de stockage est rapide et ne demande généralement que quelques secondes. Mais la désallocation est plus complexe, et c’est là que les problèmes surviennent. Plusieurs enregistrements pointant vers des ressources cloud temporaires pour différentes applications et outils sont créés. Sauf qu’ensuite, les entreprises ne parviennent pas à supprimer les ressources cloud et les enregistrements associés.
Des moyens pour atténuer le cloud squatting
Identifier et corriger le risque du cloud squatting est un défi pour les grandes entreprises qui possèdent un grand nombre de domaines. De plus, les équipes d’infrastructure globales ont des niveaux de formation variables, et quand l’équipe d’administration de la sécurité comporte plus de 100 personnes ou plus, le problème se reproduit plusieurs fois par mois. Mais il est possible de l’éviter. Pour limiter ce risque, les équipes de sécurité conçoivent des outils internes pour passer au peigne fin les domaines de l’entreprise et identifier les sous-domaines qui pointent vers les plages IP des fournisseurs de services cloud. Ces outils vérifient la validité des enregistrements IP attribués aux actifs de l’entreprise. Ces enregistrements sont attribués automatiquement par les fournisseurs de services cloud. Pour ma part, je suis toujours inquiet quand les entreprises créent et déploient leurs propres outils de sécurité, car elles risquent d’y introduire une vulnérabilité.
L’atténuation du cloud squatting ne se limite pas à la création de nouveaux outils. Les entreprises peuvent également utiliser des adresses IP réservées. Cela signifie qu’elles doivent transférer leurs propres adresses IP dans le cloud, puis maintenir et supprimer les enregistrements obsolètes et utiliser les noms DNS de manière systématique. Ce n’est pas grave, si l’on n’est pas spécialiste des réseaux et si l’on ne connait pas les DNS de ses IRS. L’idée est d’empêcher l’exploitation des anciens enregistrements non supprimés. Quoi qu’il en soit, le processus n’est pas complexe. Il faut aussi que l’entreprise applique une politique qui bloque le codage en dur des adresses IP et l’utilisation d’adresses IPv6 réservées pour peu qu’elles sont proposées par le fournisseur de services cloud.
Une menace connue mais grandissante
Ce risque peut être traité en deux étapes : d’abord, délimiter la surface d’attaque en mettant en œuvre les stratégies d’atténuation susmentionnées. Ensuite, appliquer des politiques d’utilisation des noms DNS et maintenir régulièrement des enregistrements pour que la gestion soit efficace. Cela peut paraître peu contraignant à juste titre. Cependant, deux phénomènes constatés actuellement font que le cloud squatting devient de plus en plus une menace. Il s‘agit de l’expansion rapide des déploiements dans les clouds pendant la pandémie. Durant cette période, des quantités massives de données ont été poussées dans les clouds. Des domaines ont été alloués pour trouver ces données sans trop réfléchir à la suppression de ces domaines une fois qu’ils sont devenus inutiles. Or ce point est souvent omis dans les manuels de déploiement. Quand on interpelle les gens à ce sujet, ils répondent généralement qu’ils « n’ont pas eu le temps d’y penser ». Il y a aussi la pénurie de talents à laquelle les entreprises sont confrontées en ce moment. La plupart de ces problèmes peuvent être attribués à une formation inadéquate ou à l’embauche d’administrateurs de clouds de niveau inférieur pour maintenir les choses en l’état. Souvent, les certifications permettent d’obtenir un emploi, alors que l’expérience réelle est plus importante. Cela laisse donc à penser que la plupart des entreprises devront se confronter au problème de manière pratique pour en comprendre l’impact. Et bien souvent plus tôt qu’il n’y parait.