






Afin d’optimiser le processus d’accueil de son système de sécurité des bâtiments par reconnaissance faciale, Alcatraz AI propose une inscription mobile basée sur le Web et une gestion du consentement en matière de protection de la vie privée.
Pour renforcer la sécurité des bâtiments et faciliter l’enregistrement des employés et des visiteurs, le fournisseur de systèmes de contrôle d’accès Alcatraz AI a doté son produit de reconnaissance faciale Alcatraz AI Rock d’une inscription mobile basée sur le Web et d’une gestion du consentement en matière de protection de la vie privée. Rock s’appuie sur un dispositif edge installé près des portes des bâtiments et des zones sécurisées, qui utilise la cartographie faciale 3D et l’apprentissage machine pour effectuer l’authentification faciale. « La mise à jour ajoute au système une capacité d’inscription par mobile et rationalise l’accueil en permettant aux nouveaux employés et aux visiteurs de s’inscrire à distance et en toute sécurité via leurs propres appareils mobiles et tablettes », a expliqué Blaine Fredrick, vice-président des produits chez Alcatraz AI. La mise à jour du processus de gestion du consentement comporte une option « opt-in » sur les appareils mobiles, de façon à ce que les entreprises clientes d’Alcatraz puissent informer les utilisateurs finaux sur l’utilisation et la gestion de leurs données personnelles, qu’ils peuvent choisir d’accepter ou de refuser.
Avec ces deux améliorations apportées à Rock, Alcatraz AI espère réduire le coût global et la complexité du processus d’inscription et permettre également aux entreprises de se conformer aux lois sur la protection de la vie privée comme le règlement général sur la protection des données (RGPD) de l’UE, la loi sur la confidentialité des informations biométriques (Biometric Information Privacy Act, BIPA) des États-Unis et les directives de l’autorité centrale de protection des consommateurs (Central Consumer Protection Authority, CCPA) de l’Inde. « Le système initie les inscriptions en envoyant des QR codes et des liens directement depuis les équipes de sécurité des entreprises qui ont installé le système Rock, en utilisant une authentification multifactorielle, y compris par le biais de courriels, pour reconfirmer l’accès », a ajouté M. Blaine.
Inscription mobile et problèmes de sécurité
« L’activation de l’accès distribué avec la fonction d’inscription mobile peut cependant soulever des inquiétudes quant aux tentatives malveillantes d’usurper l’identité de visiteurs valides », fait remarquer Michael Sampson, analyste senior chez Osterman Research. « On peut à juste titre être préoccupé par des problèmes de sécurité s’ils s’appuient sur l’appareil mobile personnel du futur employé et sur son adresse électronique personnelle (à laquelle un lien ou un code QR est envoyé) », a déclaré M. Sampson. « Si le compte de messagerie du futur employé a été compromis par du phishing ou d’autres systèmes de vols d’identifiants, un acteur de la menace pourrait s’enregistrer en tant qu’employé, et obtenir l’accès au bâtiment. Il y a quelques obstacles à franchir, mais la chaîne de sécurité est affaiblie quand des appareils personnels et des adresses personnelles sont utilisés », a ajouté l’analyste.
En dehors de cela, cette capacité de gestion du consentement en matière de protection de la vie privée d’Alcatraz AI devrait permettre une transparence dans l’utilisation des données des utilisateurs. « Le consentement est une bonne chose, il est même essentiel. Il y a beaucoup de règles de conformité à appliquer dans ce domaine, notamment le processus de révocation du consentement et la possibilité pour l’employé de savoir où sont traitées ses données biométriques », a déclaré M. Sampson. Alcatraz AI Rock dispose d’une série d’outils de conformité et de sécurité, en particulier la surveillance en temps réel des journaux d’événements, des calendriers de conservation des données personnalisables et des suppressions définitives de données. Les nouvelles fonctionnalités d’inscription mobile et de gestion du consentement seront généralement disponibles au deuxième trimestre 2023 pour tous les clients d’Alcatraz AI qui utilisent la version cloud d’Alcatraz AI Rock. Pour l’instant, le fournisseur n’a pas précisé si les nouvelles fonctionnalités seront déployées sur la version sur site de son produit.

La dernière variante V3G4 de Mirai pour créer des botnets dotées de capacités DDoS a exploité 13 vulnérabilités différentes au cours de trois campagnes malveillantes en 6 mois selon l’équipe de chercheurs en sécurité Unit 42 de Palo Alto Network. Sa particularité : cibler des terminaux IoT connectés à des serveurs Linux.
Selon des chercheurs de l’équipe de cybersécurité de Unit 42 de Palo Alto Network, une variante de Mirai – le malware botnet utilisé pour lancer des attaques DDoS massives dont le créateur a fini par être débusqué – a ciblé 13 failles dans des terminaux IoT connectés aux serveurs Linux. Une fois compromis par la variante, baptisée V3G4 de Mirai, ils peuvent être entièrement contrôlés par des attaquants et faire partie d’un botnet servant pour d’autres campagnes incluant des attaques DDoS. « Les vulnérabilités ont moins de complexité d’attaque que les variantes précédemment observées, mais elles maintiennent un impact critique sur la sécurité qui peut conduire à l’exécution de code à distance », a déclaré Unit 42 dans un dernier rapport.
L’activité V3G4 a été observée entre juillet et décembre de l’année dernière, dans trois campagnes selon Unit 42. Les trois campagnes semblaient être liées à la même variante et au même botnet Mirai pour plusieurs raisons, selon les chercheurs. Ils ont noté que les domaines avec l’infrastructure de commande et de contrôle (C2) codée en dur et utilisée pour maintenir les communications avec les systèmes infectés, contenaient le même format de chaîne de caractères. De plus, les téléchargements de scripts shell sont similaires et le botnet utilisé dans toutes les attaques présente des fonctions identiques. L’acteur malveillant déployant V3G4 a exploité des vulnérabilités qui pourraient conduire à l’exécution de code à distance, selon Unit 42. Une fois exécuté, le malware active une fonction pour vérifier que le périphérique hôte a déjà été infecté. Si tel est le cas, il se répandra sur un autre. Il tentera également de désactiver un ensemble de processus à partir d’une liste codée en dur, comprenant d’autres familles de logiciels malveillants de botnet concurrents.
De nombreuses failles exploitées
Alors que la plupart des variantes de Mirai utilisent la même clé pour le chiffrement de chaîne, la V3G4 utilise plusieurs clés de chiffrement XOR – une opération logique booléenne – pour différents scénarios, indique la recherche. V3G4 contient un ensemble d’identifiants de connexion par défaut ou faibles pour effectuer des attaques par force brute via les protocoles réseau Telnet et SSH, et se propager à d’autres machines. Après quoi il établit le contact avec le serveur C2 et attend de recevoir des commandes pour lancer des attaques DDoS contre des cibles selon Unit 42.
V3G4 a exploité de nombreuses vulnérabilités, notamment celles de l’outil de gestion FreePBX pour les serveurs de communication Asterisk (CVE-2012-4869), Atlassian Confluence (CVE-2022-26134), l’outil d’administration système Webmin (CVE-2019-15107), des routeurs DrayTek Vigor (CVE-2020-8515 : et CVE-2020-15415), ou encore le système de gestion Web C-Data (CVE-2022-4257). Les chercheurs de Unit 42 recommande également d’appliquer des correctifs et des mises à jour pour remédier aux vulnérabilités, lorsque cela est possible.
Un botnet redoutable
Au cours des dernières années, Mirai a tenté d’envelopper ses tentacules autour du SD-WAN, de cibler les systèmes de visioconférence d’entreprise et d’utiliser Native Linux pour infecter plusieurs plates-formes. Le botnet Mirai était une itération d’une série de packages de logiciels malveillants développés par Paras Jha, étudiant de premier cycle à l’Université Rutgers. Jha l’a posté en ligne sous le nom « Anna-Senpai », en le nommant Mirai (japonais pour « le futur »). Le botnet encapsulait certaines techniques sophistiquées y compris une liste de mots de passe codés en dur.
En décembre 2016, Paras Jha et ses associés ont plaidé coupables de crimes liés aux attaques de Mirai. Mais à ce moment-là, le code était déjà parti dans la nature et utilisé pour d’autres opérateurs de botnet. Cela signifiait que n’importe qui pouvait l’utiliser pour essayer d’infecter des terminaux IoT et lancer des attaques DDoS, voire même vendre cette capacité au plus offrant. De nombreux cybercriminels ont fait exactement cela, ou sont en train de peaufiner et d’améliorer le code pour le rendre encore plus difficile à combattre. La première grande vague d’attaques de Mirai a eu lieu le 19 septembre 2016 et a été utilisée contre l’hébergeur français OVH. Mirai était également responsable d’une attaque DDoS cette même année contre le fournisseur DNS Dyn avec environ 100 000 terminaux infectés. En conséquence, les principales plates-formes et services Internet n’étaient pas disponibles pour les utilisateurs en Europe et en Amérique du Nord.

La ratification du cadre transatlantique en matière de politique de protection des données a rencontré un obstacle. Une commission du Parlement européen a en effet rejeté un projet de décision estimant qu’il n’était pas conforme à la réglementation de l’UE en matière de RGPD.
La commission des libertés civiles, de la justice et des affaires intérieures du Parlement européen a recommandé à la Commission européenne de rejeter le projet de cadre de protection des données UE-États-Unis, qui régirait la manière dont les informations personnelles des citoyens européens sont traitées par les entreprises américaines. La décision de la commission – officiellement, un projet de proposition de résolution – représente un rejet de la recommandation de la Commission européenne, annoncée en décembre, selon laquelle le cadre relatif à la confidentialité des données devrait être adopté. La recommandation stipulait que la législation américaine offre désormais un niveau « adéquat » de protection des données personnelles des utilisateurs européens des services des entreprises américaines.
Toutefois, selon la commission parlementaire, le cadre proposé pour la protection des données n’est pas entièrement conforme au règlement général sur la protection des données (RGPD) de l’UE, en particulier à la lumière de la politique américaine actuelle qui permettrait la collecte à grande échelle et sans mandat des données des utilisateurs à des fins de sécurité nationale. Toujours selon la commission, un décret émis par l’administration Biden ne constitue pas une protection supplémentaire suffisante pour plusieurs raisons, notamment la mutabilité de la politique adoptée par décret – elle peut simplement être annulée ou modifiée par le président à tout moment – et l’insuffisance des garanties qu’il prévoit.
Le pacte sur les données avec les États-Unis jugé vague
En particulier, la commission parlementaire a noté que le décret est trop vague, qu’il laisse aux tribunaux américains – qui seraient les seuls à interpréter la politique – une marge de manœuvre pour approuver la collecte en masse de données à des fins de surveillance et de renseignement. Par ailleurs, il ne s’applique pas aux données auxquelles ont accès les tribunaux en vertu de lois américaines telles que le Cloud Act et le Patriot Act. Les principaux points soulevés par la commission parlementaire font écho à ceux de nombreux détracteurs de l’accord dans l’UE, ainsi qu’aux critiques de l’Union américaine pour les libertés civiles (ACLU), qui a déclaré que les États-Unis n’avaient pas réussi à mettre en œuvre une réforme significative de la surveillance.
Dans sa proposition de résolution, la commission parlementaire a déclaré que « contrairement à tous les autres pays tiers qui ont reçu une décision d’adéquation en vertu du RGPD, les États-Unis n’ont toujours pas de loi fédérale sur la protection des données ». En bref, la commission a déclaré que la loi nationale américaine est tout simplement incompatible avec le cadre du RGPD, et qu’aucun accord ne devrait être conclu tant que ces lois ne sont pas plus alignées. La réponse négative de la commission cette semaine au cadre proposé pour la protection des données n’était toutefois qu’un projet de résolution non contraignant et, bien qu’il s’agisse d’un point de friction, il ne met pas officiellement un terme au processus d’adoption, car son approbation n’était pas nécessaire pour faire avancer l’accord. Ce n’est pas une surprise que le comité ait émis une recommandation négative, selon Lartease Tiffith, vice-président exécutif pour la politique publique de l’Interactive Advertising Bureau, qui a soutenu le projet de cadre. « Il a un point de vue particulier sur toutes les questions liées à la vie privée et aux libertés civiles », a-t-il déclaré. « Nous devrons voir ce que la [Commission européenne] décidera ».

Les équipes en charge des enquêtes post-mortem et de réponse aux incidents cyber sont confrontées à des charges de travail croissantes dans un contexte de cyberattaques en constante évolution. Elles subissent aussi un déficit de recrutement et un manque d’automatisation efficace.
L’évolution de la cybercriminalité pèse lourdement sur les équipes d’investigation numérique et de réponse aux incidents (DFIR), entraînant un épuisement professionnel important et un risque réglementaire potentiel. C’est ce qu’indique l’enquête State of Enterprise DFIR 2023 réalisée par Magnet Forensics. L’entreprise a interrogé 492 professionnels du DFIR en Amérique du Nord et en Europe, au Moyen-Orient et en Afrique travaillant dans des entreprises de secteurs variés (technologie, fabrication, secteur public, télécommunications, soins de santé…). Les répondants ont décrit le paysage actuel de la cybercriminalité comme évoluant au-delà des rançongiciels et affectant leur capacité à enquêter sur les menaces et les incidents, indique Magnet Forensics.
Des équipes stressées et épuisées
Plus de la moitié (54 %) des professionnels du DFIR interrogés ont déclaré se sentir épuisés dans leur travail. Pour 64 %, l’excès d’alerte contribue à cette fatigue. L’augmentation des enquêtes et des données qui y sont associées est un problème « important » ou « extrême » pour les entreprises, selon 45 % des personnes interrogées, tandis que 42 % ont cité l’évolution des techniques de cyberattaque comme un problème « important » ou « extrême ». Cela représente une augmentation de 50 % par rapport au rapport DFIR 2022. « Une conséquence très réelle est qu’il faut trop de temps pour identifier la cause profonde des attaques », indique le rapport de 2023. « Cela peut entraîner des conséquences plus coûteuses et plus longues pour les sociétés tout en rendant plus difficile les leçons à tirer de ces attaques et la préparation à de futurs incidents ». La plupart des structures représentées dans l’enquête sont donc plus susceptibles d’externaliser ces tâches.
Le stress et l’épuisement professionnel ont un impact sur les équipes de cybersécurité depuis un certain nombre d’années, des recherches de 2022 soulignant l’effet de la surcharge d’informations et de l’exténuation sur les performances du SOC. Les répondants de Magnet Forensics ont généralement convenu que les difficultés de recrutements, mais aussi les problèmes d’intégration et le manque d’automatisation constituent des facteurs supplémentaires à l’accablement général. Un investissement accru dans l’automatisation est jugé « très » ou « extrêmement » précieux pour une gamme de fonctions DFIR, y compris l’acquisition à distance des endpoints cibles et le traitement des preuves numériques, ont déclaré la moitié des répondants.
Des entreprises face aux risques réglementaires
Les pratiques d’orchestration, d’automatisation et de réponse aux incidents de sécurité informatique (SOAR) sont déjà en place dans de nombreux SOC note le rapport. « Bien qu’elles soient importantes pour le confinement et la correction des menaces, ces activités liées aux runbooks sont distinctes de celles effectuées par les solutions d’automatisation du forensic, qui exécutent un pipeline de transformation des données en orchestrant, automatisant, exécutant et surveillant les flux de travail forensics », a-t-il ajouté. Reste que ces outils doivent être mieux adaptés pour être compatibles avec l’orchestration des services d’alertes et de réponses à incident déjà mis à place.
Les pressions de la charge de travail du DFIR exposent les entreprises à des risques réglementaires accrus, en particulier les règles relatives au signalement des incidents. Les deux tiers (67 %) des répondants ont déclaré que leur rôle avait été impacté par les récentes législations en matière de signalement, mais près de la moitié (46 %) ont déclaré qu’ils n’avaient pas le temps de comprendre les réglementations en matière de cybersécurité en raison de leur charge de travail. « Idéalement, les réglementations devraient être lues et interprétées par des professionnels du droit qui peuvent les traduire en informations claires et exploitables pour les praticiens du DFIR », peut-on lire dans le rapport. « S’il n’est pas possible d’obtenir une interprétation juridique officielle, les dirigeants du DFIR doivent s’assurer que les équipes disposent des ressources dont elles ont besoin pour lire et assimiler les informations, en complément d’un accès limité à un conseiller juridique pour des exigences particulièrement déroutantes », a-t-il ajouté.
Exfiltration de données et compromission de mails, incidents les plus courants
L’exfiltration de données/vol d’IP est l’incident de sécurité le plus fréquemment rencontré par les personnes interrogées, 35 % des répondants indiquant que leur structure rencontre ce type d’incident de sécurité « assez » ou « très » fréquemment. La compromission des e-mails professionnels (BEC) est la deuxième plus courante (34 %) et se produit désormais plus fréquemment que les ransomwares, qui étaient la menace de sécurité numéro 1 dans le rapport de l’année dernière. Cependant, les terminaux infectés par des ransomwares ont toujours le plus grand impact sur les organisations, selon l’enquête.
L’évolution des menaces BEC est une tendance notable. En janvier, des chercheurs en sécurité ont démontré comment le chatbot ChatGPT peut servir à rendre les attaques d’ingénierie sociale telles que les escroqueries BEC plus difficiles à détecter et plus faciles à réaliser. La technologie pour générer des variations uniques du même leurre de phishing avec un texte écrit grammaticalement correct et de type humain, mais ils peuvent créer des chaînes d’e-mails entières pour les rendre plus convaincants et peuvent même générer des messages en utilisant le style d’écriture de personnes réelles sur la base d’échantillons. En août 2022, les escrocs BEC ont contourné l’authentification multifacteurs (MFA) Microsoft 365 pour accéder au compte d’un dirigeant d’entreprise avant d’ajouter un deuxième dispositif d’authentification pour un accès persistant. Selon les chercheurs, la campagne était généralisée et ciblait de grosses transactions pouvant atteindre plusieurs millions de dollars chacune.

Plusieurs interruptions de service ont touché Oracle Cloud Infrastructure et NetSuite. Des incidents sonnant comme un avertissement aux administrateurs systèmes sur la résilience des environnements cloud.
Une succession de pannes a touché cette semaine Oracle Cloud Infrasture (OCI). L’interruption de service la plus importante a débuté lundi à 17h30 GMT et s’est prolongée jusqu’à mercredi 22h30 GMT. Elle a impacté les clients en Amérique du Nord et du Sud, en Australie, en Asie-Pacifique, au Moyen-Orient, en Afrique mais aussi en Europe.
« Les ingénieurs d’Oracle ont identifié un problème de performance au sein du backbone prenant en charge l’API OCI Public DNS, ce qui a empêché certaines demandes de services entrantes d’être traitées comme prévu », a expliqué la société. Dans une mise à jour, la firme a indiqué avoir mis en place « une approche d’atténuation adaptative utilisant des optimisations du back-end en temps réel et un réglage fin de la gestion de la charge DNS pour traiter les requêtes actuelles ».
Oracle a précisé que la panne a eu un effet domino sur ses clients. Ceux qui se servaient d’OCI Vault, API Gateway, Oracle Digital Assistant et OCI Search avec OpenSearch, par exemple, peuvent avoir reçu des erreurs ou des échecs de type 5xx (qui sont associés à des problèmes de serveur). Les clients d’Identity ont également eu des soucis lors de la création et de la modification de nouveaux domaines. De leur côté, les utilisateurs Analytics Cloud, Integration Cloud, Visual Builder Studio et Content Management ont vu la création d’instances échouée.
NetSuite victime d’un problème d’alimentation dans un datacenter
Un peu plus tôt dans la semaine, c’est l’ERP NetSuite (racheté en 2016 par Oracle) qui est tombé en carafe pendant près d’une journée. Big red n’a pas donné les raisons de cette interruption, mais nos confrères de The Register rapportent que le datacenter de Boston a été touché. « De la fumée a été signalée sur un équipement électrique dans la salle d’alimentation dans un datacenter utilisé par Oracle NetSuite », peut-on lire dans un tweet. En conséquence, les pompiers ont coupé l’alimentation du site et l’ont évacué.
Suite à cet arrêt, des clients ont signalé sur Reddit qu’ils n’étaient pas en mesure de récupérer des données enregistrées une demi-heure avant le début de la panne. Un utilisateur a publié une déclaration qui aurait été envoyée par NetSuite, confirmant que le « point de restauration se situait environ 30 minutes avant la panne. »
La résilience du cloud en question
Oracle n’est pas le seul à subir des pannes comme le montre les récents désagréments subis par les clients d’Outlook, Teams, mais aussi Exchange Online, SharePoint Online et OneDrive for Business. Ces interruptions démontrent si les acteurs du cloud disposent de datacenters redondants dans presque toutes les régions, les pertes de données sont possibles. Un risque à prendre en compte selon Sam Higins, analyste chez Forrester, « les solutions basées sur le cloud, comme leurs équivalents sur site, doivent être architecturées pour une véritable haute disponibilité et continuité ».
Il ajoute, « avoir une base cloud et une empreinte mondiale ne vous donne pas immédiatement un temps de disponibilité de 100% pour une application. Surtout pour celles ayant un long historique et un patrimoine on premise ».
Confrontées à un paysage de la sécurité en pleine mutation, les entreprises s’appuient de plus en plus sur le zero trust et de nouveaux outils de sécurité, indique un rapport du fournisseur de gestion des identités et des accès (IAM) Okta.
Publié aujourd’hui, le rapport d’Okta s’est intéressé à l’utilisation des applications et aux tendances en matière de sécurité dans sa large base d’utilisateurs. Parmi les autres tendances identifiées, le rapport du fournisseur de gestion des identités et des accès (IAM) note que les politiques de sécurité de type zerro trust sont devenues plus courantes et que l’adoption de différents types d’outils de sécurité a nettement augmenté.
Okta, qui a interrogé 17 000 clients dans le monde entier pour réaliser ce rapport, a constaté que l’utilisation de la confiance zéro parmi ses clients est passée de 10 % il y a deux ans, à 22 % aujourd’hui, ce qui indique à la fois que le zero trust est plus populaire que jamais et qu’une large part du marché reste à conquérir. Selon Okta, les entreprises technologiques sont les principaux adoptant de la confiance zéro, 34 % d’entre elles déployant au moins un système dans une configuration de confiance zéro, et 7 % en déployant deux. Le secteur financier et bancaire est également un domaine populaire pour les déploiements de confiance zéro, avec 26% utilisant au moins une configuration de confiance zéro, et 5% avec deux.
Kandji fait une percée remarquée
Selon le rapport de l’éditeur, les outils de sécurité, depuis la gestion des appareils mobiles (Mobile Device Management ou MDM) jusqu’aux applications de formation, se vendent de plus en plus cher dans tous les secteurs. Sans surprise, les outils de VPN et de pare-feu représentent la catégorie la plus importante, avec une croissance de 31 % du nombre de clients d’une année sur l’autre. Les applications de gestion et de sécurité des points d’extrémité suivent de près, avec une croissance de 25 %. Selon le rapport, l’application individuelle ayant connu la plus forte croissance parmi les utilisateurs d’Okta au cours de l’année écoulée est Kandji, une application MDM pour iOS et Mac. Cette application a gagné 172 % de clients supplémentaires au cours de l’année écoulée.
Les ventes d’outils de formation à la sécurité comme KnowBe4 et Proofpoint Security Awareneness Training ont également connu une croissance rapide, comme déjà mentionné, avec une augmentation considérable de 436 % au cours des quatre dernières années. Compte tenu de l’augmentation des attaques de ransomware, ce chiffre élevé est tout à fait compréhensible. Les outils de surveillance de l’infrastructure et d’accès aux serveurs sont également en hausse : le nombre de clients a augmenté de 66 % et 75 % respectivement au cours des deux dernières années.

Avec cette première solution de sécurité de la start-up Descope, les développeurs pourront intégrer des fonctions d’authentification et de gestion des utilisateurs dans leurs applications.
Fondée en avril 2022 par Rishi Bhargava, Slavik Markovich, Dan Sarel, Meir Wahnon, Doron Sharon, Guy Rinat, Aviad Lichtenstadt et Gilad Shriki, l’entreprise israélienne Descope vient de lever 53 M$ de fonds d’amorçage, qui comprennent des investissements de Dell Technologies, du CEO de Crowdstrike, George Kurtz, et du CEO de Rubrik, Bipul Sinha. Sa plateforme doit aider les développeurs à ajouter des fonctions d’authentification et de gestion des utilisateurs à leurs applications aussi bien BtoC que BtoB. Disponible dès maintenant, le logiciel SaaS est accessible gratuitement aux développeurs jusqu’à 7 500 utilisations mensuelles actives pour les applications B2C et jusqu’à 50 locataires pour les applications B2B. Au-delà, ils devront payer 0,10 dollars par utilisateur et 20 dollars par locataire. Selon Descope, la plateforme facilite la mise en place d’une authentification sans mot de passe.
Descope affirme que son dernier produit permet aux entreprises de :
– Créer des flux d’authentification et des écrans pour l’utilisateur final à l’aide d’un concepteur de flux visuel ;
– Ajouter de manière transparente différentes méthodes d’authentification sans mot de passe à des applications du genre Magic link, de biométrie et de clés d’accès (basées sur WebAuthn), des applications d’authentification et des identifiants de réseaux sociaux ;
– Valider, fusionner et gérer les identités tout au long du parcours de l’utilisateur ;
– Préparer ses applications professionnelles pour l’entreprise grâce à l’authentification unique (Single Sign-On, SSO), au contrôle d’accès, à la gestion des locataires et au provisionnement automatisé des utilisateurs ;
– Améliorer la protection des utilisateurs en activant facilement l’authentification multifactorielle (MFA), l’authentification par paliers ou l’authentification biométrique dans les applications.
Gérer les identités avec Descope
La plateforme de Descope propose différentes options d’intégration : un constructeur de flux de travail et un éditeur d’écran sans code, un ensemble de SDK client et backend, et des API REST complètes.
Les développeurs qui créent des flux d’authentification avec Descope pourront choisir différentes manières de valider les identités, notamment en confirmant l’adresse de messagerie des utilisateurs, leur numéro de téléphone ou tout autre identifiant choisi via des liens magiques – ou Magic link – à usage unique envoyés par courriel, ou de mots de passe à usage unique. La validation de l’identité peut également se faire par le biais de fournisseurs d’identité d’entreprise, notamment Azure Active Directory et Okta. Une fonction permet également de fusionner les identités quand un utilisateur s’identifie, par exemple, en utilisant une méthode et, à une autre occasion, en choisit une autre. Certains systèmes créent deux comptes différents pour le même utilisateur, ce qui peut entraîner une perte de données. « Descope garantit que, si un utilisateur s’identifie avec une nouvelle méthode d’authentification, son identité est fusionnée avec toutes les inscriptions utilisant d’autres méthodes d’authentification après validation de l’identité. Les applications disposent ainsi d’une vue unifiée de leurs utilisateurs et ces derniers bénéficient d’une bien meilleure expérience », a expliqué Rishi Bhargava, le cofondateur de Descope.
Moins d’options pour casser l’authentification
Très souvent, c’est en s’appuyant sur des comptes utilisateurs compromis que les attaquants parviennent à s’introduire dans les systèmes des entreprises. Comme beaucoup d’autres fournisseurs, Descope mise sur l’augmentation de la sécurité en utilisant d’autres méthodes d’authentification. Cette multiplication des verrous limite les options des attaquants, car elle empêche les attaques par force brute, le bourrage d’identifiants et la pulvérisation de mots de passe. La solution utilise également l’empreinte digitale des terminaux et plusieurs autres facteurs pour savoir si les utilisateurs se connectent à partir d’un nouvel appareil, d’un lieu inhabituel, etc. Les développeurs d’applications peuvent choisir d’ajouter une authentification renforcée dans ces cas et demander un facteur d’authentification supplémentaire. Descope mise sur le passage à l’authentification sans mot de passe des géants de la technologie comme Apple, Google et Microsoft, mais aussi sur le risque que les mots de passe continuent de représenter pour la sécurité des entreprises.
« Descope prétend simplifier et accélérer la mise en œuvre de méthodes diversifiées d’authentification sans mot de passe pour les développeurs d’applications. L’authentification et la gestion des utilisateurs sont complexes et longues à mettre en œuvre », a expliqué M. Bhargava. « Ce qui ressemble au départ à un simple poste de dépense se transforme souvent en investissements pluriannuels. Construire et maintenir l’authentification en interne retarde le temps de mise sur le marché d’une application, distrait les développeurs de leur travail prioritaire et peut conduire à des failles de sécurité », a ajouté le cofondateur de Descope.
La start-up israélienne Oligo Security cible les vulnérabilités du code logiciel avec une technologie avancée de filtrage sans agent.
Fondée en 2023, après quelques trimestres en mode confidentiel pour assurer le développement de son produit à l’abri des regards, la start-up israélienne Oligo Security commercialise son logiciel éponyme, apportant une approche repensée de la sécurité (surveillance, observabilité et remédiation) des applications reposant sur des packages open source. Utilisant une technologie baptisée extended Berkeley Packet Filter (eBPF), elle est capable de réaliser une analyse sans agent du code réexploité.
Étant donné la prévalence du code open source dans les logiciels modernes – Oligo affirme qu’il représente quelque chose comme 80 ou 90 % – la recherche de vulnérabilité potentielle est devenue une nécessité dans les entreprises désirant contrôler plus finement le travail final des développeurs. La génération actuelle de solutions est toutefois “brouillonne”, selon Oligo. Elle aurait tendance à produire beaucoup de faux positifs et à ne pas contextualiser les alertes dans un temps d’exécution donné. Cette dernière tendance n’est pas utile pour établir des priorités de remédiation.
Le tableau de bord d’Oligo Security rapporte les vulnérabilités dans le code open source des apps. (Crédit : Oligo)
La plupart des outils de surveillance de la sécurité de ce type sont basés sur le RASP (Runtime application self-protection), qui nécessite un agent installé au plus de l’application, selon Jim Mercer, vice-président de la recherche d’IDC pour devops et devsecops. L’eBPF, en revanche, permet aux programmes de s’exécuter à l’intérieur du système d’exploitation, agissant comme une machine virtuelle dans le noyau qui permet la collecte de données à partir des applications et des ressources réseau, offrant un niveau granulaire d’observabilité et permettant la création d’un SBOM (software bill of materials) dynamique. « L’un des principaux avantages de la solution Oligo est qu’elle est sans agent et qu’elle exploite l’eBPF », a déclaré M. Mercer. « Une critique traditionnelle de la technologie RASP est que l’agent introduit une certaine surcharge dans votre application. »
Oligo contextualise les alertes de sécurité
De plus, puisque l’offre Oligo, basée sur eBPF et sans agent, fonctionne au niveau du système d’exploitation, elle peut mettre les alertes en contexte – en donnant la priorité aux corrections des vulnérabilités qui sont des déviations actives de la politique de permission d’une bibliothèque de code donnée, explique la start-up. Cela permet de gagner du temps de développement en se concentrant sur les surfaces d’attaque réelles, et pas seulement sur les vulnérabilités potentielles connues. L’approche d’Oligo, cependant, n’est pas sans écueils potentiels, selon M. Mercer. Tout d’abord, elle n’est conçue que pour détecter les vulnérabilités connues, alors que certains types de systèmes basés sur le RASP peuvent identifier de nouvelles insécurités dans le code natif et le code source ouvert. En outre, le système d’alerte plus sélectif peut, s’il est configuré de manière inexperte, passer à côté de problèmes potentiellement graves.
« Je soupçonne que la clé ici est une gestion saine des politiques, et il pourrait incomber à Oligo de fournir un contenu qui peut aider les organisations à écrire des politiques sûres, sans être gênés par les perturbations », a déclaré M. Mercer. Néanmoins, l’analyste a noté que l’approche d’Oligo est susceptible d’attirer une grande variété de clients potentiels, étant donné l’omniprésence susmentionnée du code source ouvert, et pourrait même être utilisée pour rechercher des vulnérabilités dans les logiciels commerciaux. « Dans l’ensemble, [l’approche plus sélective d’Oligo] est probablement une bonne chose, car il existe des bibliothèques open source que vous pouvez utiliser et qui présentent des vulnérabilités, mais vous ne les utilisez pas de manière vulnérable », a-t-il déclaré. La technologie de la société est déjà utilisée par des entreprises sur les marchés de l’informatique, des logiciels d’analyse et de l’immobilier, bien que les données actuelles sur les prix et la disponibilité n’aient pas été immédiatement disponibles. D’autres entreprises de cybersécurité ont également exploité l’eBPF. Par exemple, en août de l’année dernière, Traceable AI a ajouté eBPF à sa plateforme de sécurité pour une observabilité et une visibilité plus approfondies des API.

Rien n’est plus mauvais pour une entreprise que d’être débordé en en temps de crise. Les RSSI doivent prendre l’initiative d’élaborer un plan de communication post-cyberattaque qui informe précisément les parties prenantes et suscite la confiance au sein de l’entreprise.
Les réponses aux récentes cyberattaques suggèrent que les entreprises peuvent avoir du mal à faire passer le bon message au milieu d’un incident. Bien que la gestion de la communication autour d’un incident ne soit pas du ressort direct du RSSI, la mise en place d’un plan de communication est un élément essentiel de la cyberpréparation. « La communication est un élément essentiel d’une bonne stratégie cybernétique, et elle doit être préparée et pratiquée dans les organisations avant qu’un incident ne se produise », explique Eden Winokur, responsable cyber chez Hall & Wilcox, qui aide notamment les entreprises à gérer les cyberincidents.
Le conseil d’Eden Winokur est de pécher par excès de transparence, tout en veillant à l’exactitude lorsqu’il s’agit de répondre à un cyberincident. « La cybersécurité n’est pas seulement un risque informatique. C’est vraiment un risque d’entreprise, et un élément clé de la cyberpréparation comprend une stratégie de communication au sein de l’organisation et avec les parties prenantes externes ». S’il s’agit d’un incident important, il est vital de s’engager avec des personnes qui ont une expérience spécifique dans la gestion des cyberattaques. « Nous recommandons souvent de faire appel à des experts pour aider les entreprises à comprendre les implications de leurs communications et la façon dont certaines choses seront reçues par le public ou les médias », note Mme Winokur.
Etablir un plan détaillé
Bien que les associations ou les gouvernements ne fournissent que peu de conseils officiels sur l’élaboration d’un plan de communication, l’équipe de communication, en collaboration avec la direction générale, le service juridique et l’équipe du RSSI, doit participer à l’élaboration de la réponse. Elle doit tenir compte des obligations de divulgation prévues par les réglementations sur la protection de la vie privée, les sociétés cotées en bourse et les organismes d’application de la loi. Eden Winokur recommande de commencer par analyser et enregistrer toutes les parties prenantes pertinentes de l’organisation, internes et externes, et de tenir ce registre à jour au fur et à mesure que les choses changent.
« Nous recommandons également aux entreprises de passer en revue leurs principaux contrats et de comprendre quelles sont leurs obligations en matière de communication avec les clients ». Les déclarations préparées qui ont déjà été approuvées peuvent être adaptées rapidement et jetteront les bases d’une réponse organisée. « Il doit y avoir des modèles qui peuvent être adaptés à la question spécifique en jeu », poursuit Eden Winokur. Ces modèles peuvent être envoyés aux employés, au gouvernement, aux parties prenantes, aux clients, sur le site web et à tout autre endroit où cela peut être nécessaire.
Ne pas précipiter la communication avec les parties prenantes après l’incident
Lorsque des cyberincidents se produisent pour la première fois, l’envie de rassurer, voire de contenir l’incident, est forte. Mais le besoin de précision est primordial, prévient Andrew Moyer, vice-président exécutif et directeur général de Reputation Partners, qui gère les communications de crise. « Vous voulez être le premier à planter le drapeau narratif », dit-il. Si les entreprises prennent de l’avance et publient des déclarations définitives, basées sur ce qu’elles ont compris à un moment donné, pour ensuite se rétracter ou changer d’avis, le désastre peut être encore plus grand. Soudain, un cyberincident se transforme en une véritable crise de relations publiques. Si les choses changent, comme elles ont tendance à le faire, cela peut soulever des questions quant à la crédibilité de l’organisation. « Ce que vous ne voulez pas faire, c’est dire quelque chose avec une telle spécificité que vous risquez de devoir revenir en arrière et de perdre votre crédibilité », explique M. Moyer.
Les cyberattaques devenant de plus en plus régulières chaque année, le grand public a un certain niveau de compréhension, voire d’attente, quant aux incidents qui se produisent. Par conséquent, Andrew Moyer pense que les gens sont plus à l’aise avec des déclarations nuancées, de sorte que « vous ne vous mettez pas dans un coin absolu ». Au lieu de viser des chiffres exacts, par exemple, il recommande d’utiliser un langage qui inclut « des termes d’échelle relative tels que ‘Nous sommes conscients qu’il s’agit d’un nombre limité de personnes touchées’ plutôt que ‘nous pensons qu’il s’agit de 1 000 personnes’ ». Toute personne en position de première ligne a besoin d’un signe d’alerte précoce que quelque chose s’est produit et d’une ligne directe avec les décideurs pour soulever la question de savoir quand il est nécessaire d’activer le plan de crise. « Il est essentiel, dans le cadre de toute stratégie de communication, de s’assurer que vous êtes précis et de reconnaître si une enquête est en cours, et de faire cette déclaration encore et encore. Il s’agit en partie d’élaborer ces documents sous forme de modèles dès le début, afin que les personnes concernées les examinent et les approuvent. Et vous pouvez avancer un peu plus vite », explique M. Moyer.
S’assurer de l’existence d’un bon plan de communication
Un plan de communication existant aura cartographié le flux d’informations pour s’assurer que les bonnes personnes sont informées assez rapidement pour s’organiser et diffuser l’information afin que tout le monde reçoive un message cohérent. Il peut établir l’équipe de réponse à la crise, qui comprend le RSSI, le responsable de la communication et les RH, s’il s’agit d’une violation interne. L’objectif est de faire en sorte que chacun comprenne son rôle et sa responsabilité dans cette réponse particulière, ainsi que la préférence de l’organisation pour l’équilibre entre rapidité et précision.
Cependant, la force d’un plan dépend de sa mise à l’épreuve. « La révision vous donne la possibilité d’évaluer régulièrement vos risques. Y a-t-il de nouveaux risques auxquels nous n’avons pas pensé l’année dernière et contre lesquels nous devons nous préparer ? Y a-t-il des lacunes et des vulnérabilités que nous pouvons corriger ? » Disposer d’un plan entièrement élaboré, c’est éviter le problème de se fier à la mémoire collective de l’organisation sur la façon de gérer les crises. « Cela permet également de s’assurer que si vous êtes la personne qui possède toutes ces connaissances institutionnelles, et que vous partez à la retraite ou que vous partez, il y a quelque chose vers quoi se tourner en cas de violation », ajoute Andrew Moyer.
Le recours au conseil externe, un atout dans la gestion de crise
En matière de cybersécurité, il y a une liste d’éléments à prendre en compte, notamment les exigences de notification aux niveaux national, local, fédéral et international, les dispositions contractuelles avec les partenaires ou les clients, etc. C’est pourquoi M. Moyer recommande de disposer d’un conseil externe et d’un service de communication de crise en numérotation rapide. « Le fait d’avoir ces relations établies à l’avance vous permet d’agir plus rapidement sur le moment ». Il peut également arriver que l’on doive mettre un frein à la communication parce qu’elle peut potentiellement aggraver la situation. Les conseils en communication externe sont alors utiles. « Ils peuvent évaluer des critères clés pour décider si vous devez changer votre posture, de plus réactive à plus proactive. Devons-nous changer le message ou le récit que nous diffusons ? » poursuit Andrew Moyer.
Pour les RSSI, Andrew Moyer recommande de mettre en place un bon plan opérationnel et de le communiquer en interne aux autres parties prenantes, tout en comprenant comment leur réponse opérationnelle s’intègre dans une réponse de communication. C’est une voie à double sens. « Ainsi, les responsables de la communication comprennent la réponse opérationnelle et l’équipe de réponse opérationnelle – les RSSI – comprend ce à quoi la réponse de communication doit ressembler », explique-t-il. « Il s’agit de les encourager à établir ce lien entre ces fonctions, si ce n’est pas le cas actuellement ». « Il ne s’agit pas de surcharger de communications une personne qui se concentre sur une réponse opérationnelle critique ; il s’agit simplement de s’assurer que le flux d’informations, la structure et le processus en place dans une organisation permettent d’avoir les meilleures chances que cela se produise ».
La détection des incidents donne le ton des communications
La détection précoce n’est pas seulement essentielle pour limiter les dégâts, elle fait aussi partie intégrante de la gestion de la réponse. Paul Black, associé des services d’expertise judiciaire de KPMG et spécialiste de la réponse aux cyberincidents, explique que la façon dont les organisations découvrent qu’elles ont été victimes d’un incident peut déterminer la manière dont elles y répondent. Il arrive souvent que les organisations ne se rendent compte qu’il y a eu une violation que quelque temps plus tard, parfois lorsque leurs données commencent à apparaître sur le dark web. « Il y a souvent une réaction de panique et des communications de panique parce qu’il est assez courant pour les organisations d’apprendre d’un tiers, qu’il s’agisse d’un client ou d’un consommateur, ou même d’un concurrent, d’un organisme d’application de la loi ou d’un organisme de réglementation, que des données se trouvent sur le dark web. Elles ne peuvent donc pas nécessairement prendre les devants », explique M. Black.
S’ils parviennent à comprendre rapidement la cause profonde, cela ouvre la voie « pour s’assurer que les bonnes parties prenantes sont impliquées, que les bonnes notifications sont faites, que les données peuvent être gérées et que les communications avec les tiers peuvent être gérées de manière appropriée », ajoute-t-il. « L’élément de détection et de sensibilisation est en fait lié à l’élément de communication, car plus tôt vous êtes informé, mieux vous êtes en mesure de comprendre et de transmettre l’information. Et peut-être que ce lien n’a pas toujours été vraiment explicite dans l’espace de sécurité et pour les RSSI ».
Paul Black recommande aux entreprises d’utiliser leur cyberassurance lorsqu’elle couvre les relations publiques et la communication de crise. Cela peut aider à répondre aux incidents, notamment lors des discussions sur les « joyaux de la couronne » de l’organisation et sur la manière de gérer les obligations de divulgation. Dans certains cas, le moyen de communication peut faire partie du problème, comme dans le cas de la compromission du courrier électronique professionnel (BEC), et il peut donc être nécessaire de le fermer pendant un certain temps, ce qui ne fait qu’ajouter aux difficultés. Avant tout, il est essentiel de disposer d’une chaîne de commandement établie pour gérer les incidents, qui tienne compte de l’aspect communication interne et externe.
Simuler des scénarios d’attaque est la meilleure des préparations
Il faut également tenir compte du fait qu’à l’ère des communications numériques, il est aussi important de communiquer en interne que de divulguer en externe. « Ces choses peuvent être incroyablement sensibles. Il n’est peut-être pas approprié de communiquer en interne pour dire : « Nous avons subi une violation de données, nous enquêtons dessus », car le lendemain, cela pourrait faire la une des journaux », explique-t-il. M. Black encourage également les RSSI et les hauts responsables à prendre le temps de simuler des scénarios pour tester le plan d’intervention. « Il s’agit de faire transpirer les hauts dirigeants dans un scénario de cyberattaque, ce qui ne correspond pas nécessairement à un plan de réponse aux incidents préétabli », explique-t-il.
Il conseille aux RSSI de ne pas éviter les exercices difficiles et de se contenter d’une séance d’information par crainte d’embarrasser les hauts responsables de l’organisation. « C’est la pire chose à faire, car il faut mettre les gens sous pression en leur faisant vivre un scénario dans un environnement sûr. C’est comme ça que les incidents fonctionnent, c’est une pression immense ». « Le meilleur résultat, c’est si cette organisation repart avec 100 lacunes identifiées et que chacun a une liste de 20 points d’action qu’il doit corriger. Cela signifie que, collectivement, vous avez identifié les points sur lesquels les capacités de réponse ne sont pas à la hauteur, que vous pouvez y remédier et ensuite augmenter vos capacités », explique M. Black. « Les entreprises qui réagissent le plus efficacement ont pris le temps de se mettre au défi et de mettre à l’épreuve leurs dirigeants, et de tirer les leçons de ces exercices ».
L’utilisation accrue des passerelles et des routeurs cellulaires industriels expose les dispositifs IIoT aux attaquants et augmente la surface d’attaque des réseaux OT.
L’utilisation accrue des passerelles et des routeurs cellulaires industriels expose les dispositifs IIoT aux attaquants et augmente la surface d’attaque des réseaux OT (technologies opérationnelles). Les équipes OT sont souvent amenées à connecter des systèmes de contrôle industriel (ICS) à des centres de contrôle et de surveillance à distance via des solutions sans fil et cellulaires, parfois avec l’aide d’interfaces de gestion basées sur le cloud et gérées par les fournisseurs. Or, ces solutions de connectivité, également appelées dispositifs IoT industriels sans fil, augmentent la surface d’attaque des réseaux OT et peuvent fournir aux attaquants distants un raccourci vers des portions de réseau précédemment segmentés contenant des contrôleurs critiques. Cette semaine, un rapport publié par l’entreprise de cybersécurité industrielle Otorio met en évidence les vecteurs d’attaque auxquels ces terminaux sont sensibles ainsi que les vulnérabilités que les chercheurs d’Otorio ont trouvées dans plusieurs de ces produits. « Les appareils IoT sans fil industriels et leurs plateformes de gestion basées sur le cloud sont des cibles attrayantes pour les attaquants qui cherchent à prendre pied dans les environnements industriels », indiquent les chercheurs d’Otorio dans leur rapport, en pointant « des exigences minimales en termes d’exploitation et d’impact potentiel ».
Un changement dans l’architecture traditionnelle des réseaux OT
La sécurité des technologies de l’information a généralement suivi le modèle PERA (Purdue Enterprise Reference Architecture) pour décider de l’emplacement des couches de contrôle d’accès et de la segmentation. Ce modèle, qui date des années 1990, divise les réseaux informatiques et OT des entreprises en six niveaux (Levels) fonctionnels.
Level 0 : il désigne l’équipement qui influence directement les processus physiques et comprend des éléments comme les vannes, les moteurs, les actionneurs et les capteurs.
Level 1, ou couche de contrôle de base : il comprend les contrôleurs de terrain comme les automates programmables industriels (Programmable Logic Controllers, PLC) et les unités terminales distantes (Remote Terminal Unit, RTU) qui contrôlent ces capteurs, vannes et actionneurs en fonction de la logique (programmes) déployée par les ingénieurs.
Level 2, ou couche de contrôle de supervision : il comprend les systèmes de contrôle de supervision et d’acquisition de données (Supervisory Control and Data Acquisition, SCADA) qui collectent et traitent les données reçues des contrôleurs de niveau Level 1.
Level 3, ou couche de contrôle du site : il comprend les systèmes qui soutiennent directement les opérations d’une usine, comme les serveurs de base de données, les serveurs d’applications, les interfaces homme-machine, les postes de travail d’ingénierie utilisés pour programmer les contrôleurs de terrain, etc. Généralement appelée Centre de contrôle (Control Center), cette couche est connectée au réseau IT général de l’entreprise (Level 4) par une zone démilitarisée (DMZ).
C’est dans cette DMZ que les entreprises ont concentré leurs efforts en matière de sécurité du périmètre afin de disposer d’une segmentation solide entre les parties informatique et technique de leurs réseaux. Des contrôles supplémentaires sont souvent mis en place entre le niveau Level 3 et le niveau Level 2, dans le but de protéger les appareils de terrain contre les intrusions dans les centres de contrôle. Cependant, il arrive que certaines entreprises aient besoin de connecter des installations industrielles distantes à leurs centres de contrôle principaux. Cette situation est plus courante dans des secteurs comme le gaz et le pétrole, où les exploitants peuvent avoir plusieurs champs pétroliers et puits de gaz en exploitation à différents endroits, mais cette configuration peut se retrouver couramment dans d’autres secteurs.
Ces liens entre les dispositifs distants de niveau 0-2 et les systèmes de contrôle de niveau Level 3 sont fréquemment assurés par des passerelles cellulaires industrielles ou des points d’accès WiFi industriels. Ces dispositifs IoT industriels sans fil peuvent dialoguer avec les appareils de terrain via plusieurs protocoles, comme Modbus et DNP3 (Distributed Network Protocol), puis se reconnecter au centre de contrôle de l’entreprise via Internet en utilisant divers mécanismes de communication sécurisés comme le VPN. De nombreux fabricants d’appareils fournissent également des interfaces de gestion basées sur le cloud pour que les propriétaires d’actifs industriels puissent gérer leurs appareils à distance.
Vulnérabilités des dispositifs industriels IoT sans fil
Ces terminaux, comme tout autre connecté à Internet, augmentent la surface d’attaque des réseaux OT et affaiblissent les contrôles de sécurité traditionnellement mis en place par les entreprises, offrant ainsi aux attaquants une option de contournement vers les niveaux inférieurs des réseaux OT. « En utilisant des moteurs de recherche comme Shodan, nous avons observé une exposition généralisée des passerelles et routeurs cellulaires industriels, ce qui les rend faciles à découvrir et potentiellement vulnérables à l’exploitation par des acteurs de la menace », indiquent les chercheurs d’Otorio dans leur rapport.
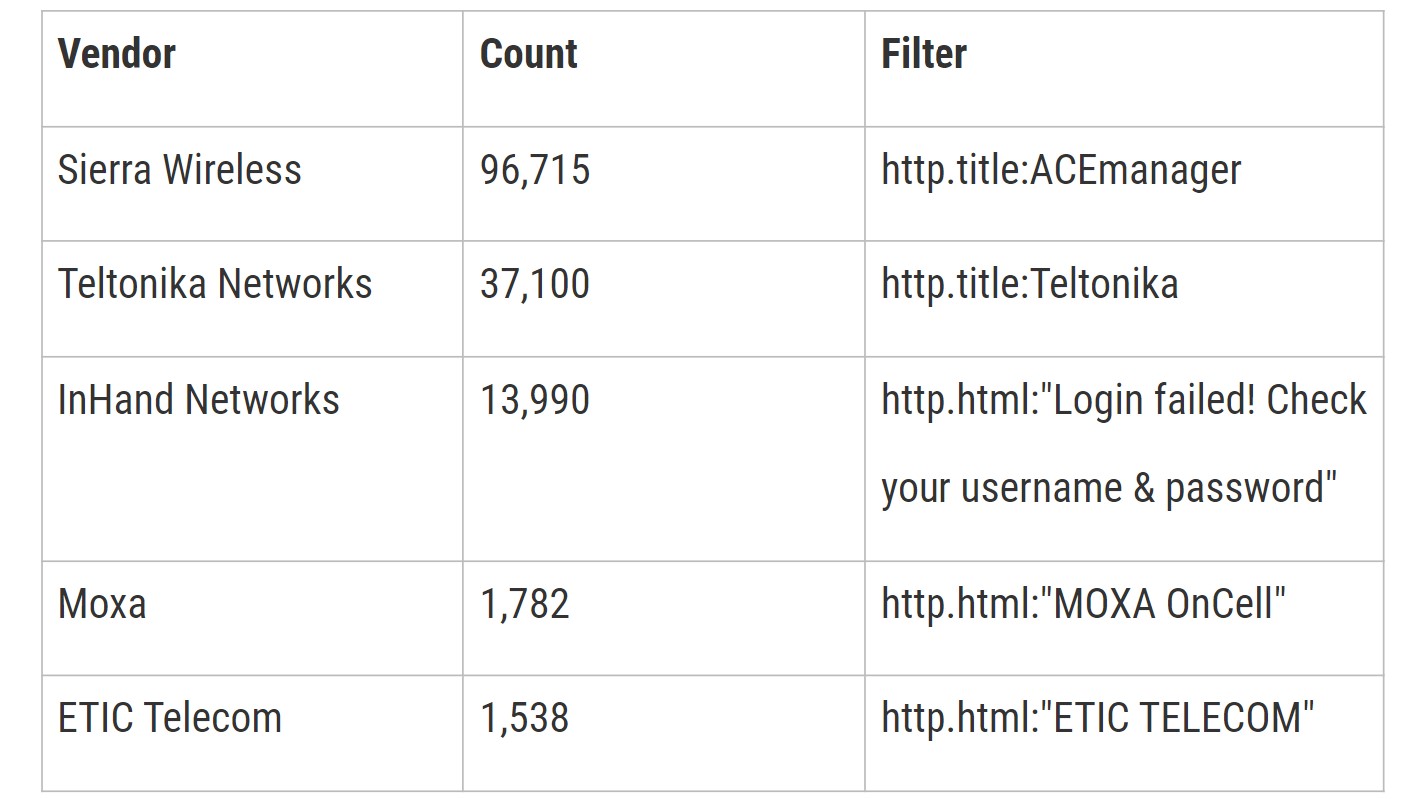
Voici quelques-unes de leurs conclusions concernant les appareils dotés de serveurs et d’interfaces web accessibles par Internet :
Les chercheurs affirment avoir trouvé 24 vulnérabilités dans les interfaces web des appareils de trois de ces fournisseurs – Sierra, InHand et ETIC – et avoir réussi à exécuter du code à distance sur les trois.
Alors que la plupart de ces failles sont encore en cours de divulgation, l’une d’entre elles, référencée CVE-2022-46649, a déjà été corrigée sur les routeurs AirLink de Sierra Wireless. Il s’agit d’une vulnérabilité par injection de commande dans la fonction de journalisation IP d’ACEManager, l’interface de gestion web du routeur, et c’est une variante d’une autre faille trouvée par les chercheurs de Talos en 2018 et suivie sous la référence CVE-2018-4061. Il s’avère que le filtrage mis en place par Sierra pour traiter la vulnérabilité CVE-2018-4061 ne couvrait pas tous les scénarios d’exploitation et les chercheurs d’Otorio ont pu le contourner.
Dans la CVE-2018-4061, les attaquants pouvaient joindre des commandes shell supplémentaires à la commande tcpdump exécutée par le script ACEManager iplogging.cgi en utilisant le drapeau -z. Ce drapeau est supporté par l’utilitaire tcpdump en ligne de commande et est utilisé pour passer des commandes dites postrotate. Sierra a corrigé le problème en appliquant un filtre qui supprime tout drapeau -z de la commande passée au script iplogging s’il est suivi d’un espace, d’une tabulation, d’un saut de page ou d’une tabulation verticale, ce qui bloquerait, par exemple, « tcpdump -z reboot ». Mais, selon Otorio, une chose leur a échappé : c’est que le drapeau -z ne nécessite aucun de ces caractères et qu’une commande comme « tcpdump -zreboot » s’exécuterait parfaitement et contournerait le filtrage. Ce seul contournement limiterait toujours les attaquants à l’exécution de fichiers binaires qui existent déjà sur l’appareil. Les chercheurs ont donc développé un moyen de cacher leur charge utile dans un fichier PCAP (package capture) téléchargé sur l’appareil via une autre fonction d’ACEManager appelée iplogging_upload.cgi. Ce fichier PCAP spécifiquement conçu peut également se comporter comme un script shell quand il est analysé par sh (l’interpréteur shell) et son analyse et son exécution peuvent être déclenchées en utilisant la vulnérabilité -z dans iplogging.cgi.
Risques liés à la gestion du cloud
Même si ces dispositifs n’exposent pas leurs interfaces de gestion basées sur le Web directement à Internet, ce qui n’est pas une pratique de déploiement sécurisée, ils ne sont pas totalement inaccessibles aux attaquants distants. En effet, la plupart des fournisseurs proposent des plates-formes de gestion dans le cloud qui permettent aux propriétaires d’appareils d’effectuer des changements de configuration, des mises à jour de firmware, des reboots d’appareils, de faire passer du trafic par les appareils, etc. Généralement, les appareils communiquent avec ces services de gestion cloud à l’aide de protocoles M2M (machine-to-machine), tels que MQTT, un protocole de messagerie publish-subscribe basé sur le protocole TCP/IP, et leur mise en œuvre peut présenter des faiblesses. Les chercheurs d’Otorio ont découvert des vulnérabilités critiques dans les plateformes cloud de trois fournisseurs, qui permettent aux attaquants de compromettre à distance tout appareil géré par le cloud sans authentification. « En ciblant la plateforme de gestion cloud d’un seul fournisseur, un attaquant à distance peut exposer des milliers d’appareils situés sur différents réseaux et secteurs », ont déclaré les chercheurs. « La surface d’attaque sur la plateforme de gestion cloud est large. Elle comprend l’exploitation de l’application web (interface utilisateur cloud, Cloud-UI), notamment l’abus des protocoles M2M, l’abus des politiques de contrôle d’accès faibles ou l’abus d’un processus d’authentification faible ».
Les chercheurs illustrent ces risques par une chaîne de trois vulnérabilités trouvées dans la plateforme de gestion cloud « Device Manager » d’InHand Networks et dans le firmware de ses appareils InRouter, qui auraient pu entraîner l’exécution de code à distance avec des privilèges root sur tous les appareils InRouter gérés dans le cloud. En premier lieu, ils ont examiné la manière dont les appareils communiquent avec la plateforme via MQTT et la manière dont l’authentification, ou « l’enregistrement », est réalisée et dont la sécurité est assurée. Ils ont découvert que l’enregistrement utilise des valeurs insuffisamment aléatoires et peut être abusé par force brute. En d’autres termes, en exploitant deux de ces vulnérabilités, les chercheurs ont réussi à obliger un routeur à fournir son fichier de configuration en usurpant l’identité d’une connexion authentifiée et à lui demander d’accomplir des tâches, par exemple de modifier son nom d’hôte. La troisième vulnérabilité concernait la manière dont le routeur analysait les fichiers de configuration via MQTT, en particulier la fonction utilisée pour analyser les paramètres d’une fonction appelée auto_ping. Les chercheurs ont découvert qu’ils pouvaient activer auto_ping, puis concaténer une ligne de commande reverse shell à la fonction auto_ping_dst, qui s’exécutait avec les privilèges de l’utilisateur root sur l’appareil.
Attaques sans fil sur les réseaux OT
En plus des vecteurs d’attaque à distance disponibles sur Internet, ces terminaux exposent également les signaux WiFi et cellulaires localement, de sorte que toute attaque sur ces technologies pourrait être utilisée contre eux. « Différents types d’attaques locales peuvent être utilisés contre les canaux de communication WiFi et cellulaires, depuis les attaques sur les cryptages faibles comme le WEP et les attaques de déclassement vers le GPRS (General Packet Radio Service) vulnérable, jusqu’aux vulnérabilités complexes des chipsets qui peuvent prendre du temps à corriger », ont déclaré les chercheurs. Même si ces derniers n’ont pas étudié les vulnérabilités des modems WiFi ou cellulaires en bande de base, ils ont effectué une reconnaissance en utilisant WiGLE, un service public de cartographie des réseaux sans fil qui collecte des informations sur les points d’accès sans fil dans le monde entier. « En exploitant les options de filtrage avancées, nous avons écrit un script Python pour rechercher des environnements industriels ou d’infrastructures critiques potentiellement de grande valeur, en mettant en évidence ceux qui sont configurés avec un cryptage faible », ont déclaré les chercheurs. « Notre analyse a permis de découvrir des milliers de dispositifs sans fil liés aux infrastructures industrielles et critiques, dont des centaines étaient configurés avec des cryptages faibles connus du public », ont-ils ajouté. En utilisant cette technique, les chercheurs ont réussi à trouver des dispositifs avec un cryptage sans fil faible, déployés dans le monde réel, dans des usines de fabrication, des champs pétrolifères, des sous-stations électriques et des installations de traitement des eaux. Les attaquants pourraient utiliser cette reconnaissance pour identifier les appareils faibles, puis se rendre sur place pour les exploiter.
Atténuer les vulnérabilités des dispositifs IoT sans fil
Même si la correction des vulnérabilités de ces systèmes, quand elles sont découvertes, est d’une importance capitale en raison de leur position privilégiée dans les réseaux OT et de leur accès direct aux contrôleurs critiques, des mesures préventives supplémentaires sont nécessaires pour atténuer les risques. Les chercheurs d’Otorio recommandent notamment : de désactiver et d’éviter tout cryptage non sécurisé (WEP, WAP) et, dans la mesure du possible, de ne pas autoriser les anciens protocoles comme le GPRS ; de cacher les noms de ses réseaux (SSID) ; d’utiliser une liste blanche basée sur le MAC, ou d’utiliser des certificats, pour les appareils connectés ; de vérifier que les services de gestion sont limités à l’interface LAN uniquement ou qu’ils sont sur liste blanche IP ; de s’assurer qu’aucun justificatif d’identité par défaut n’est utilisé ; d’être attentif aux nouvelles mises à jour de sécurité disponibles pour ses appareils ; de vérifier que ces services sont désactivés s’ils ne sont pas utilisés (activés par défaut dans de nombreux cas) ; de mettre en œuvre des solutions de sécurité séparément (VPN, pare-feu), en traitant le trafic provenant de l’IIoT comme non fiable.